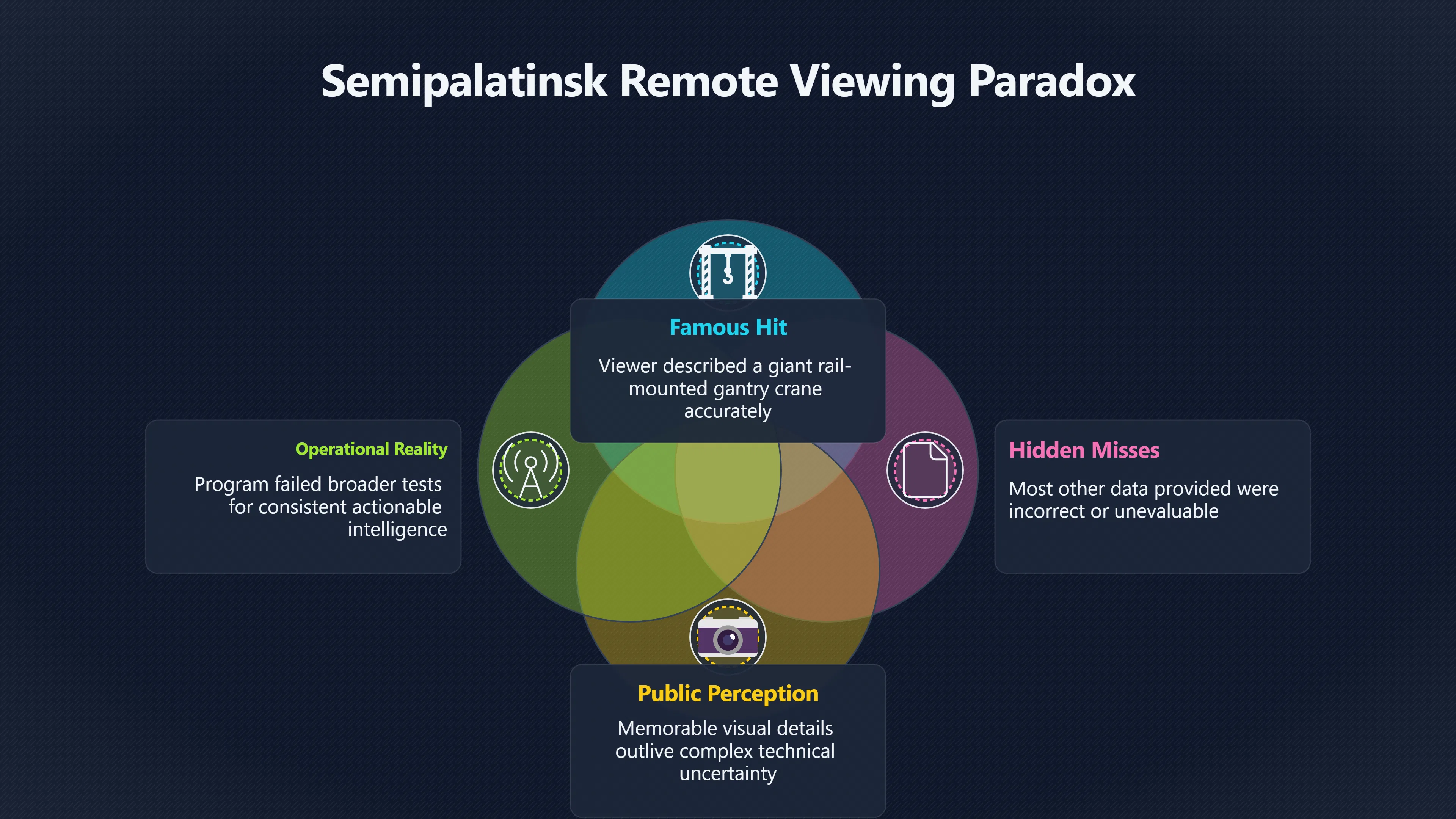
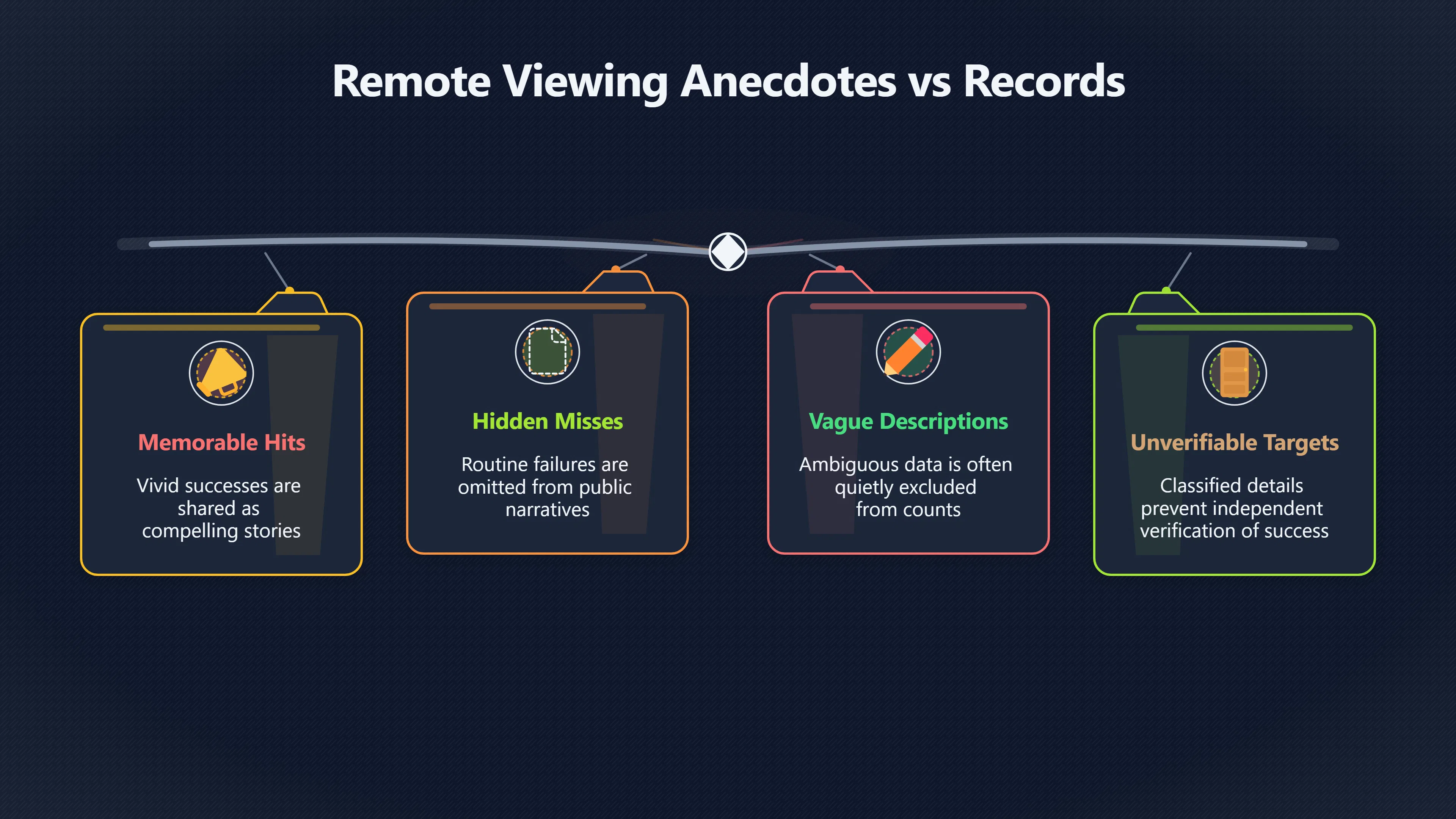
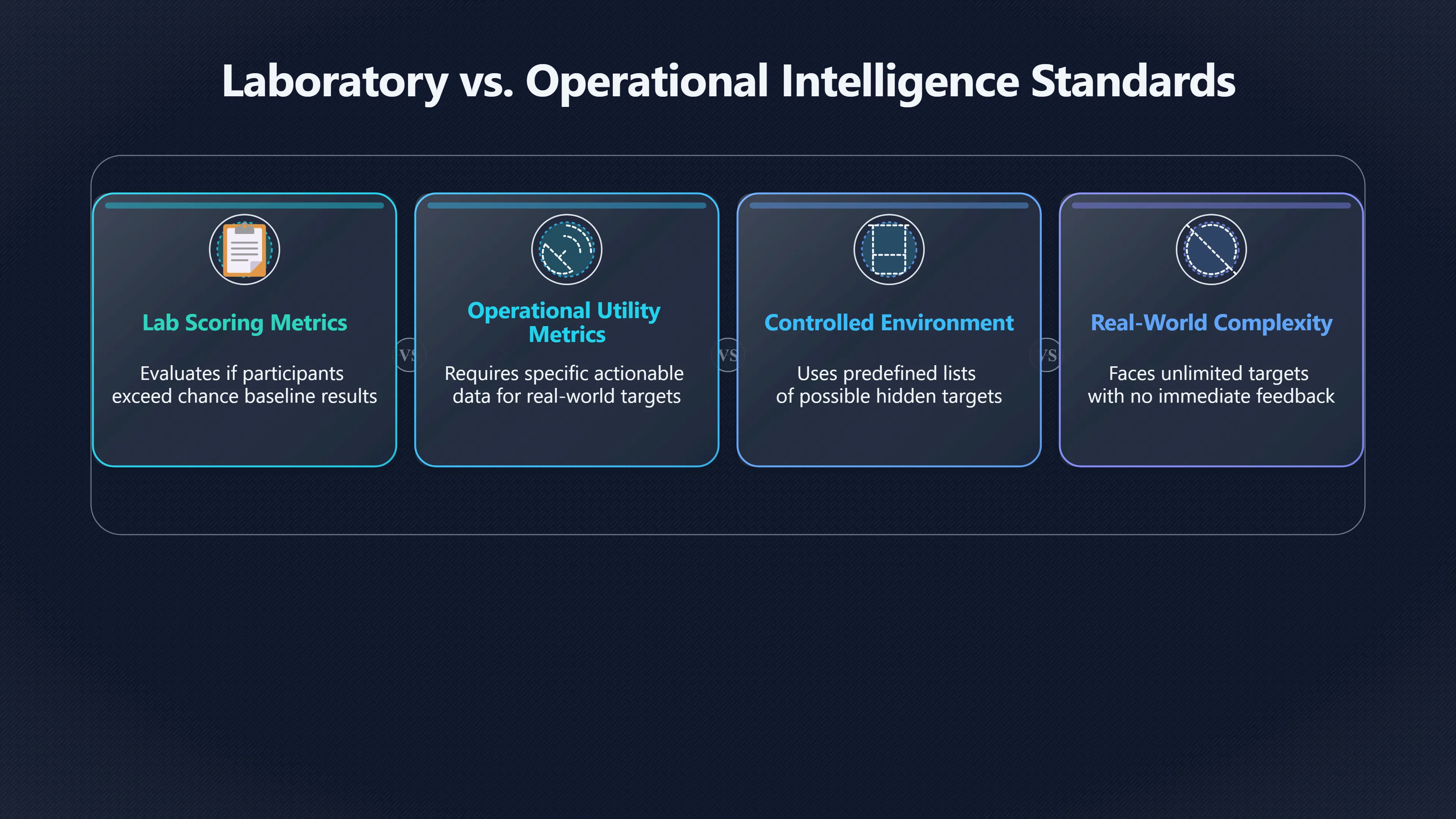
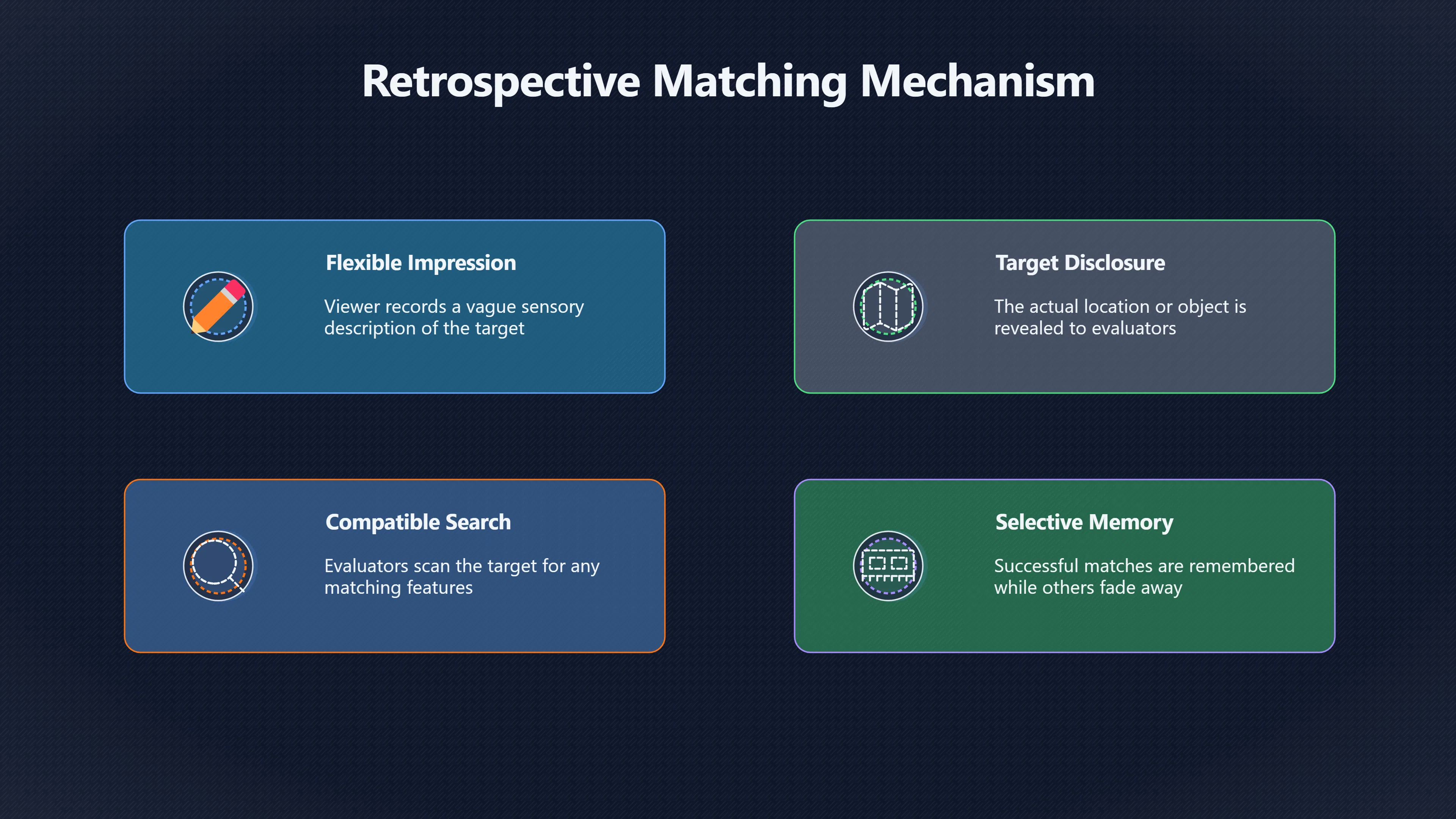
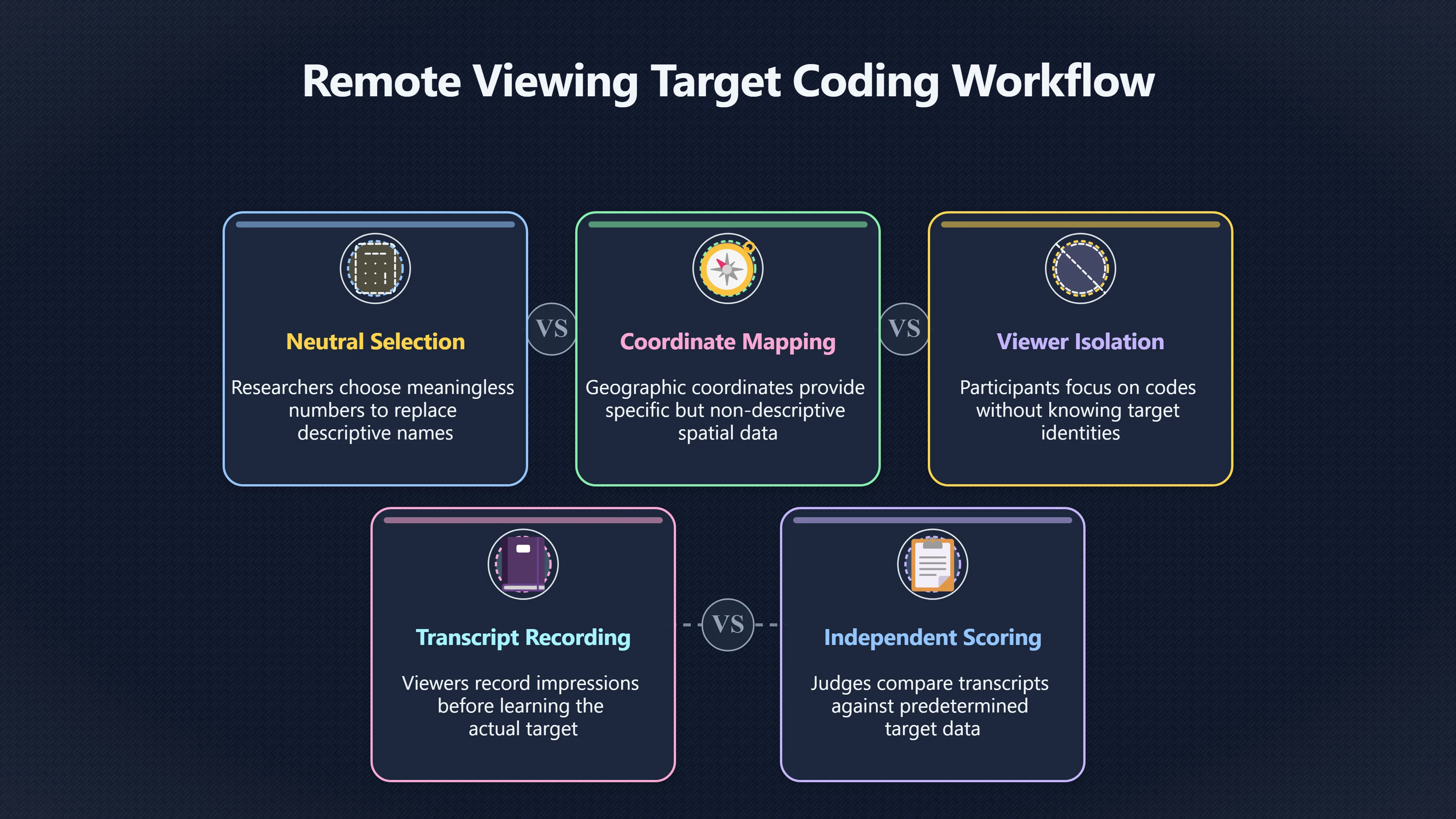
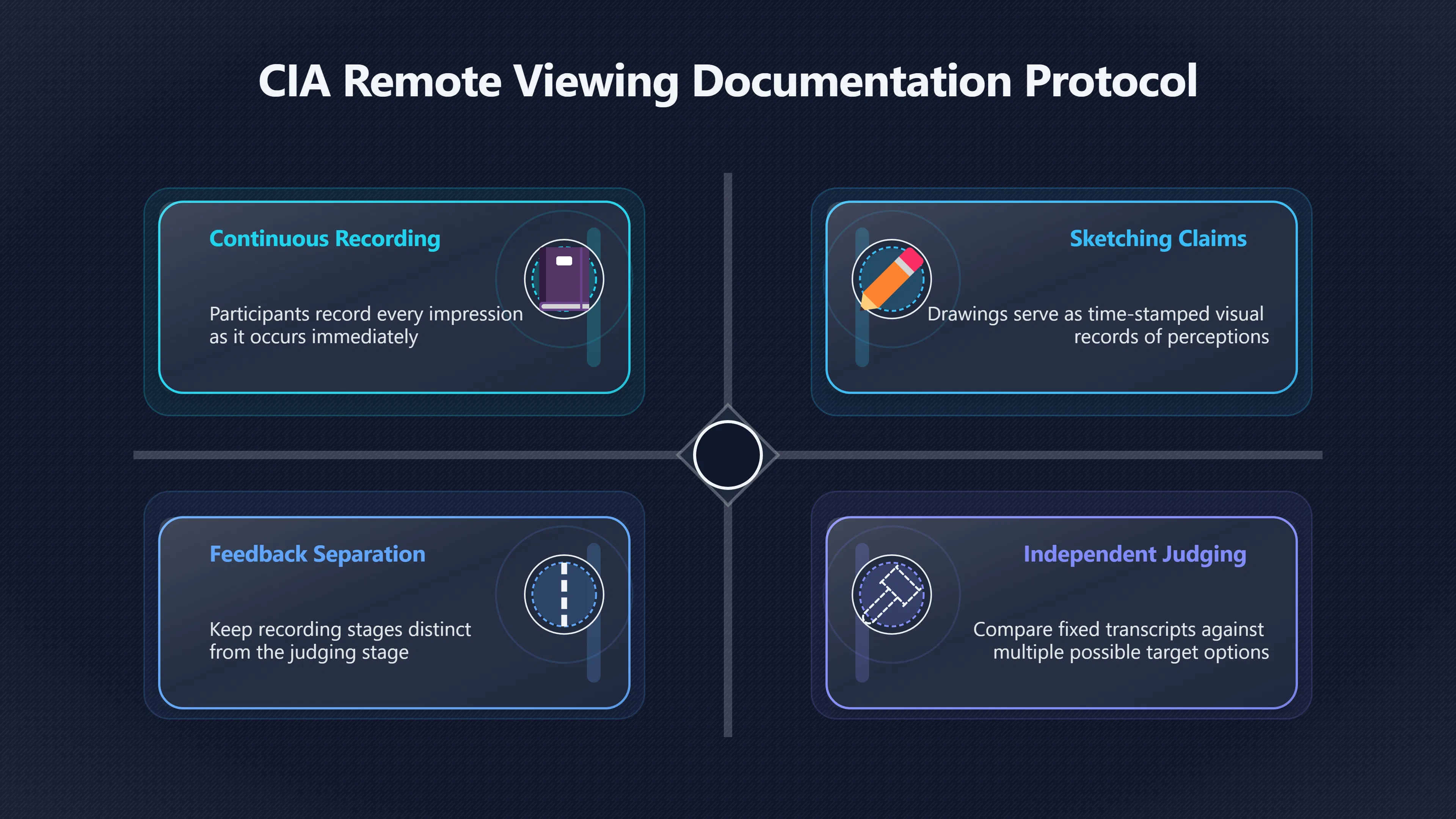
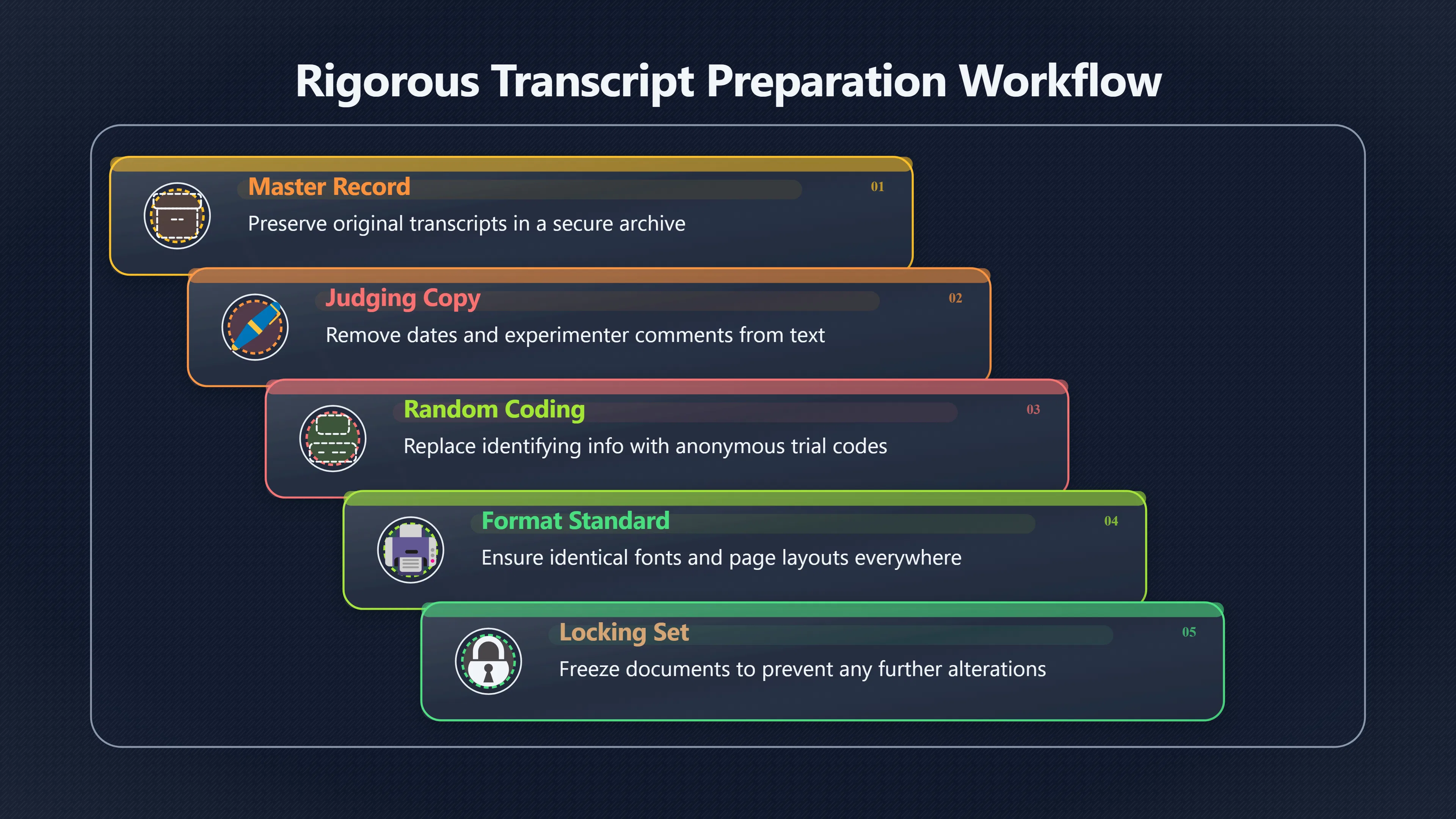
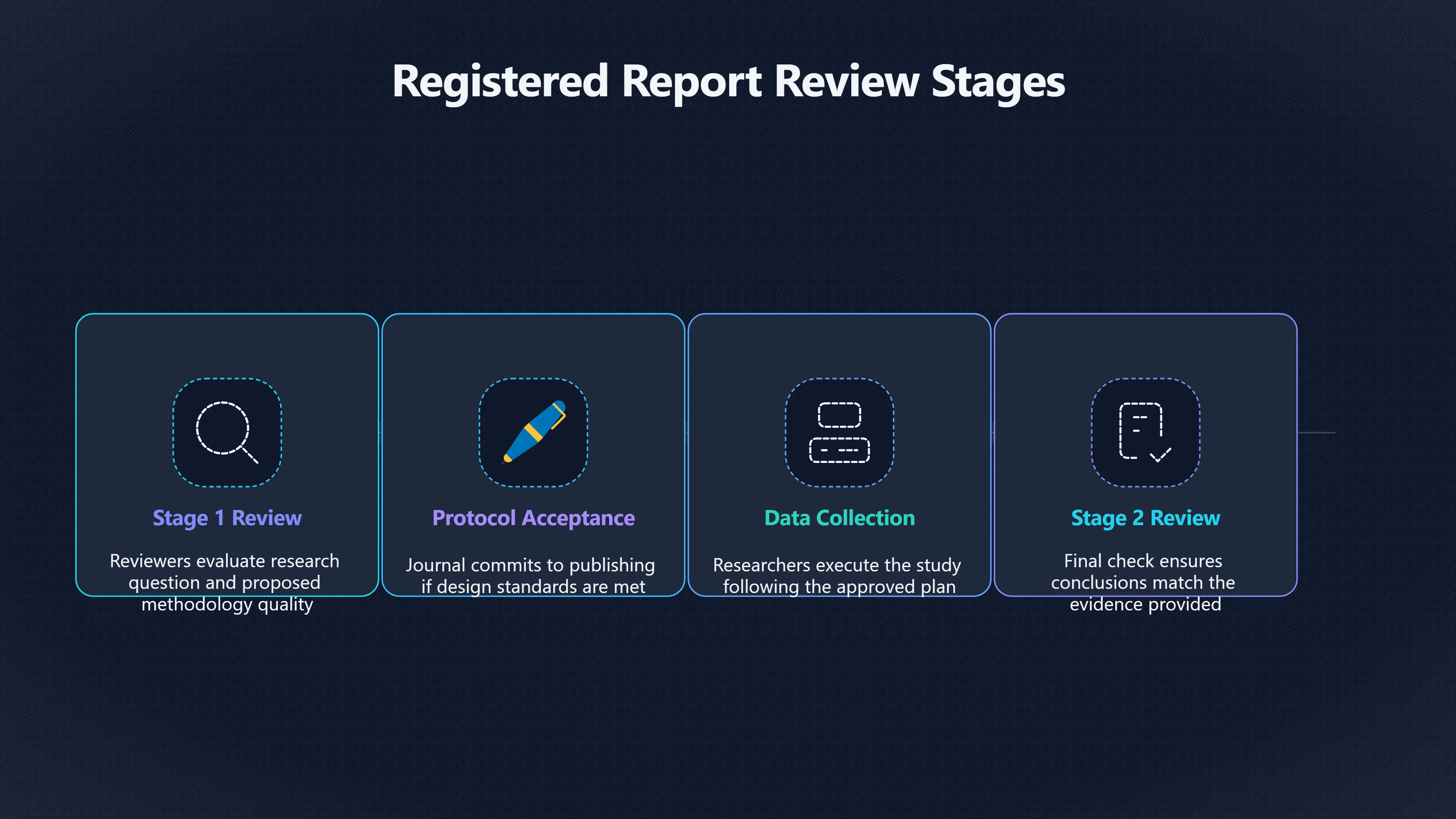
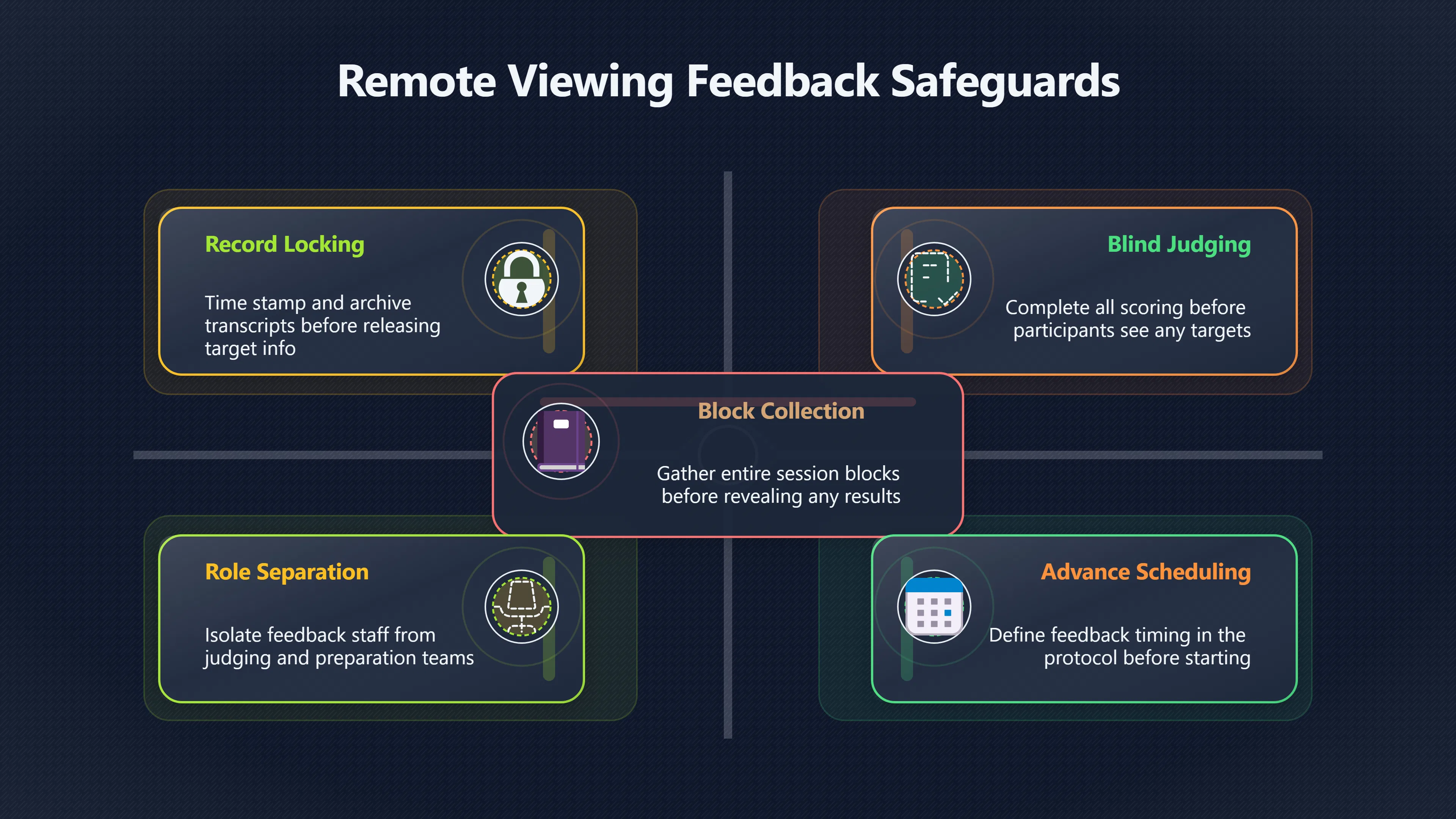
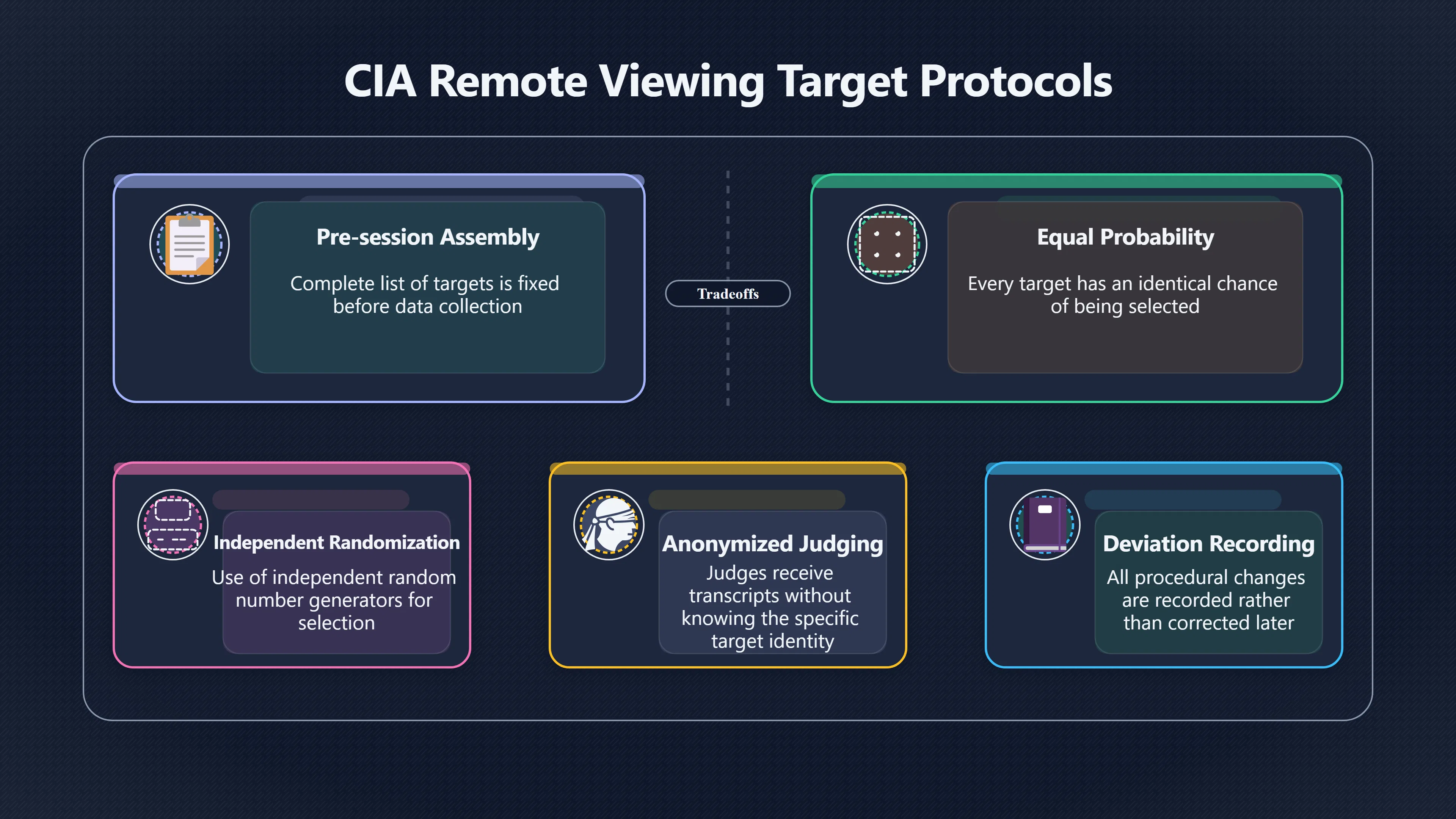
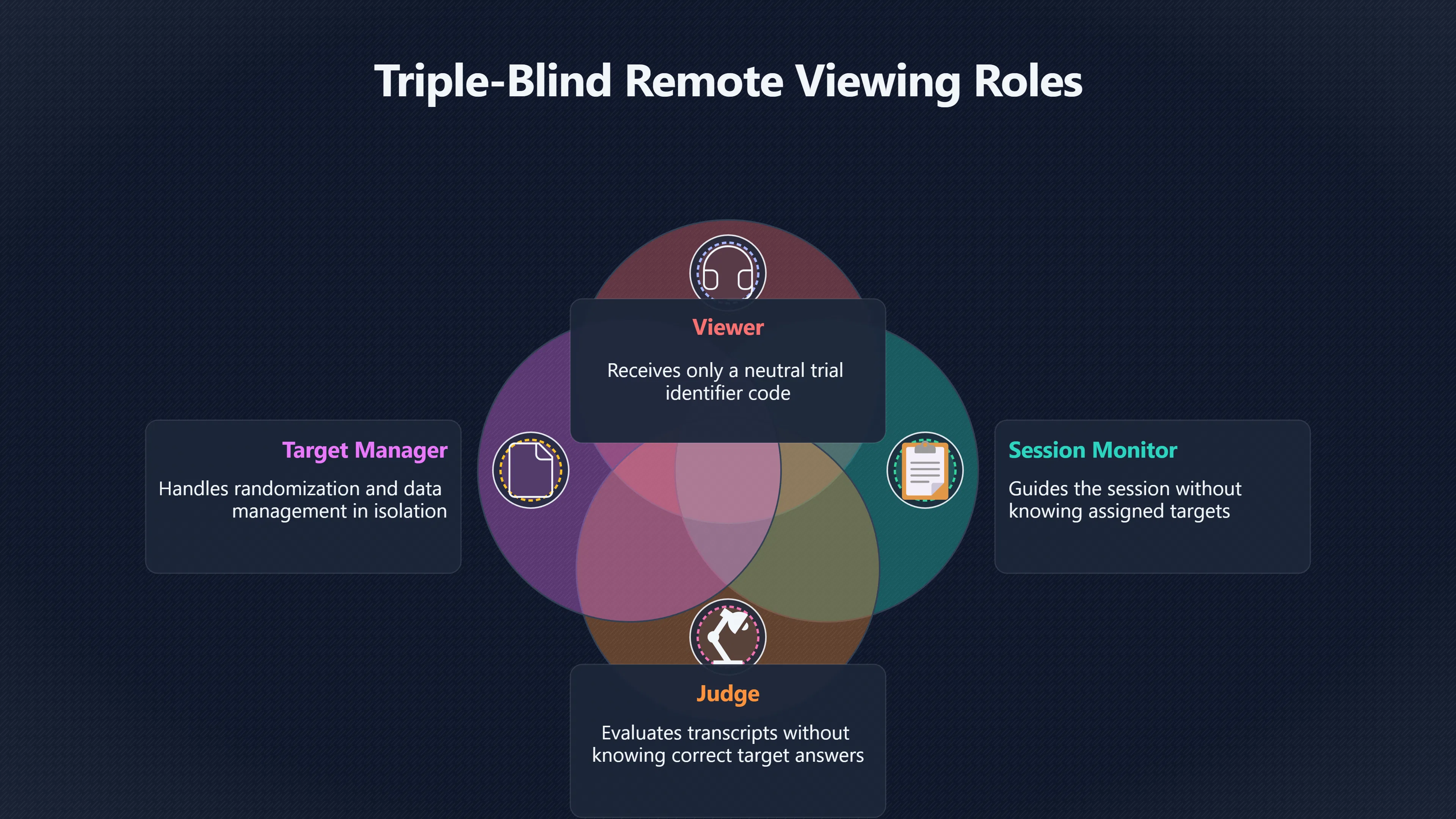
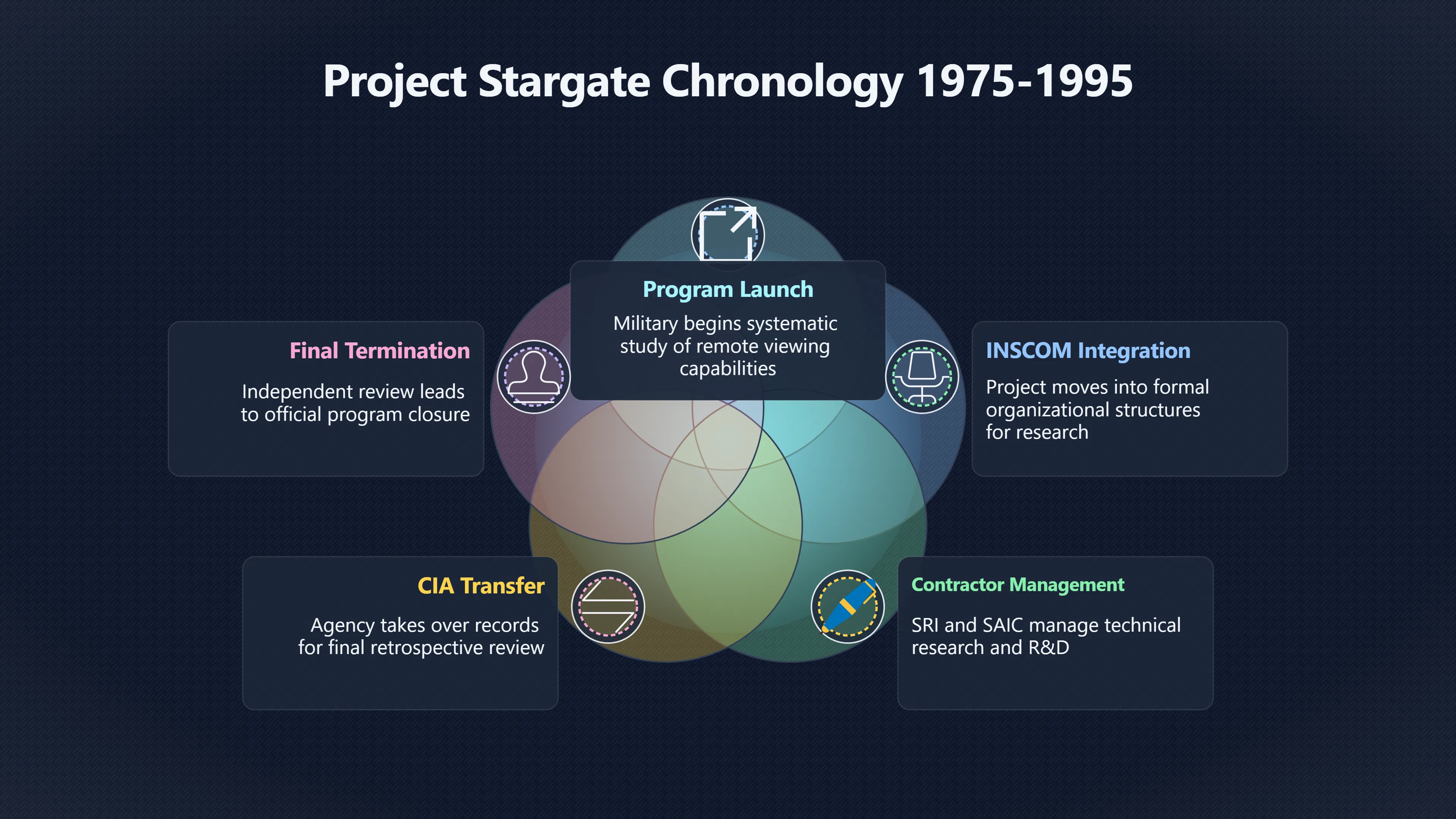
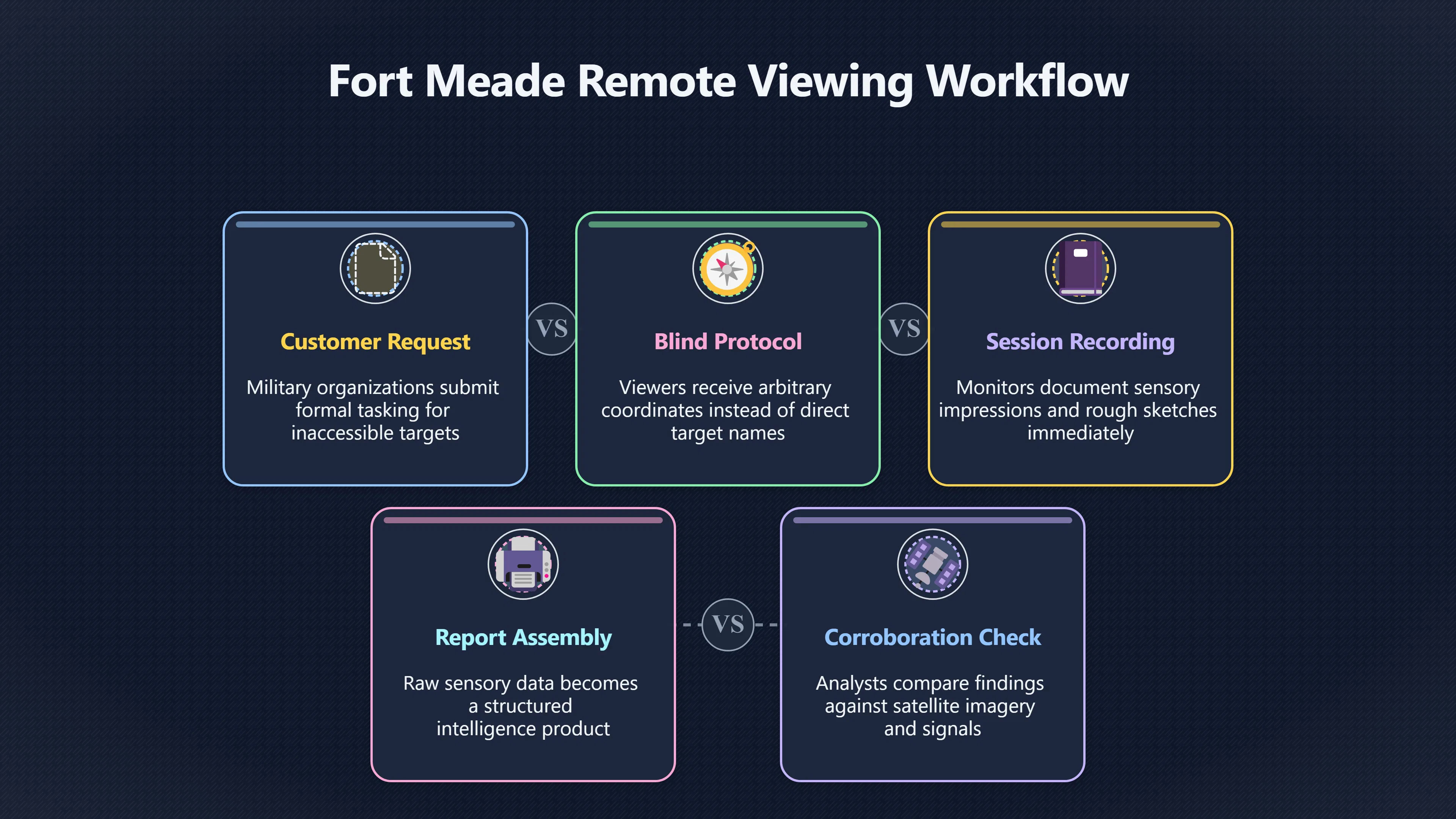
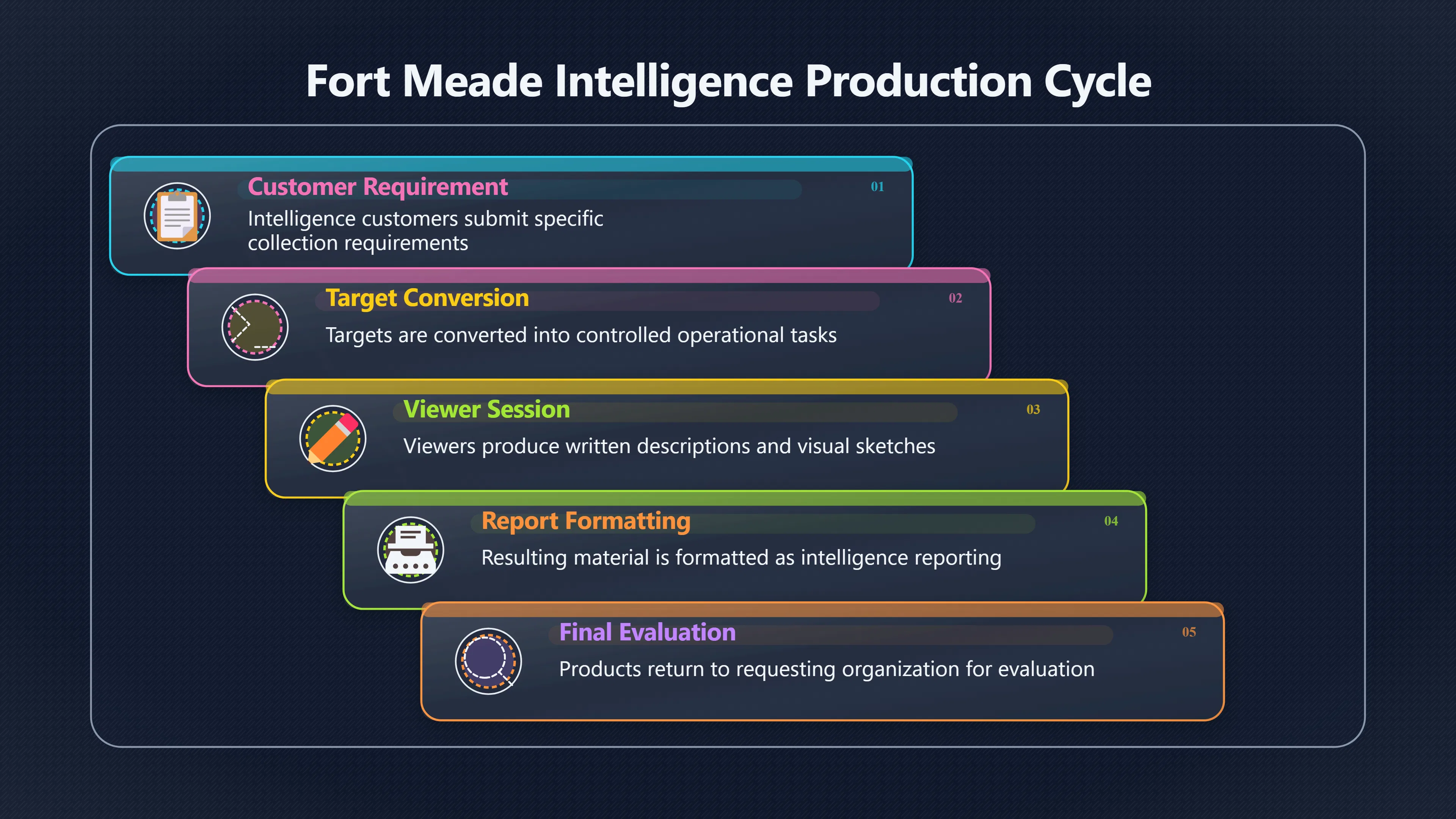
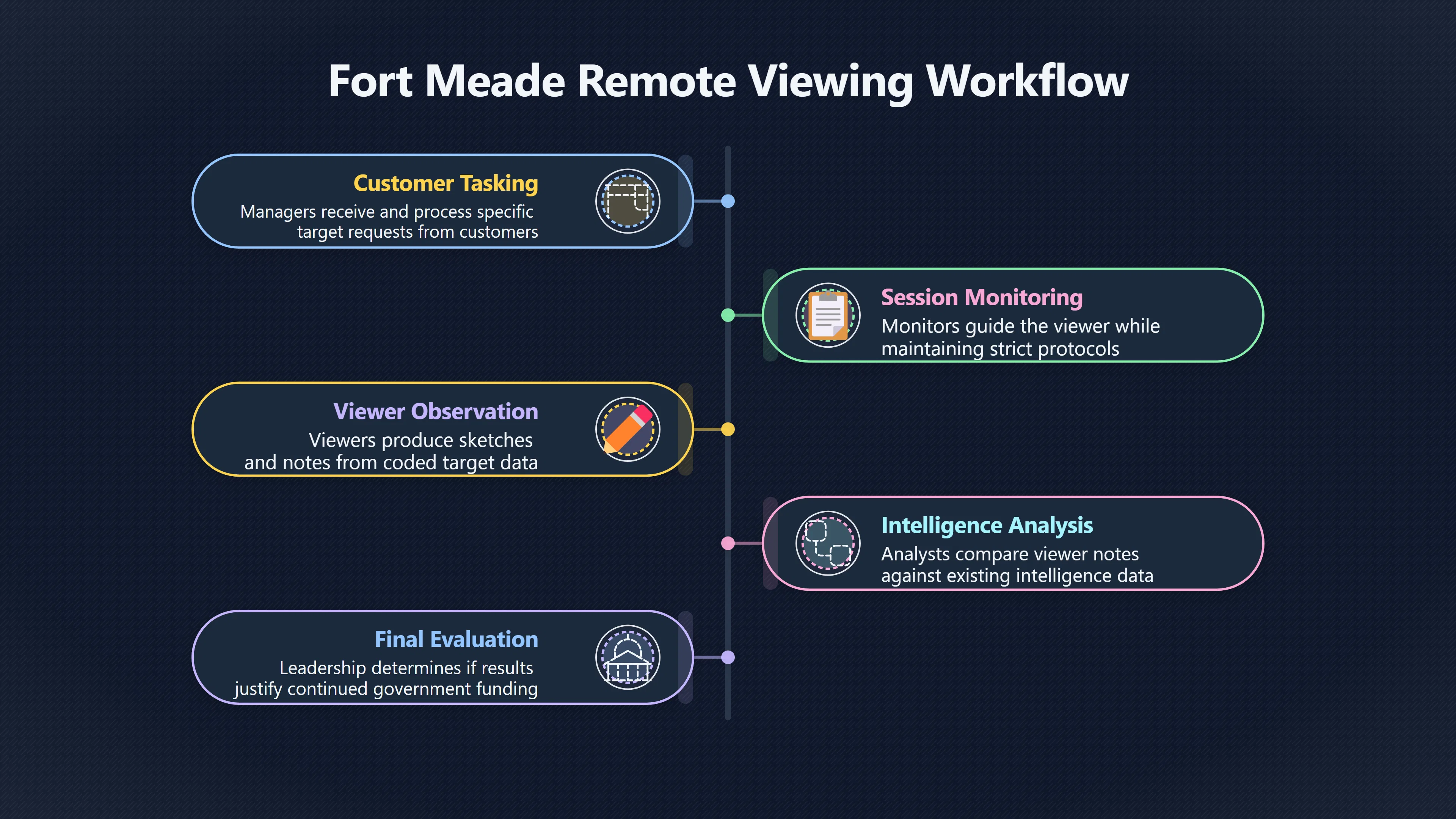
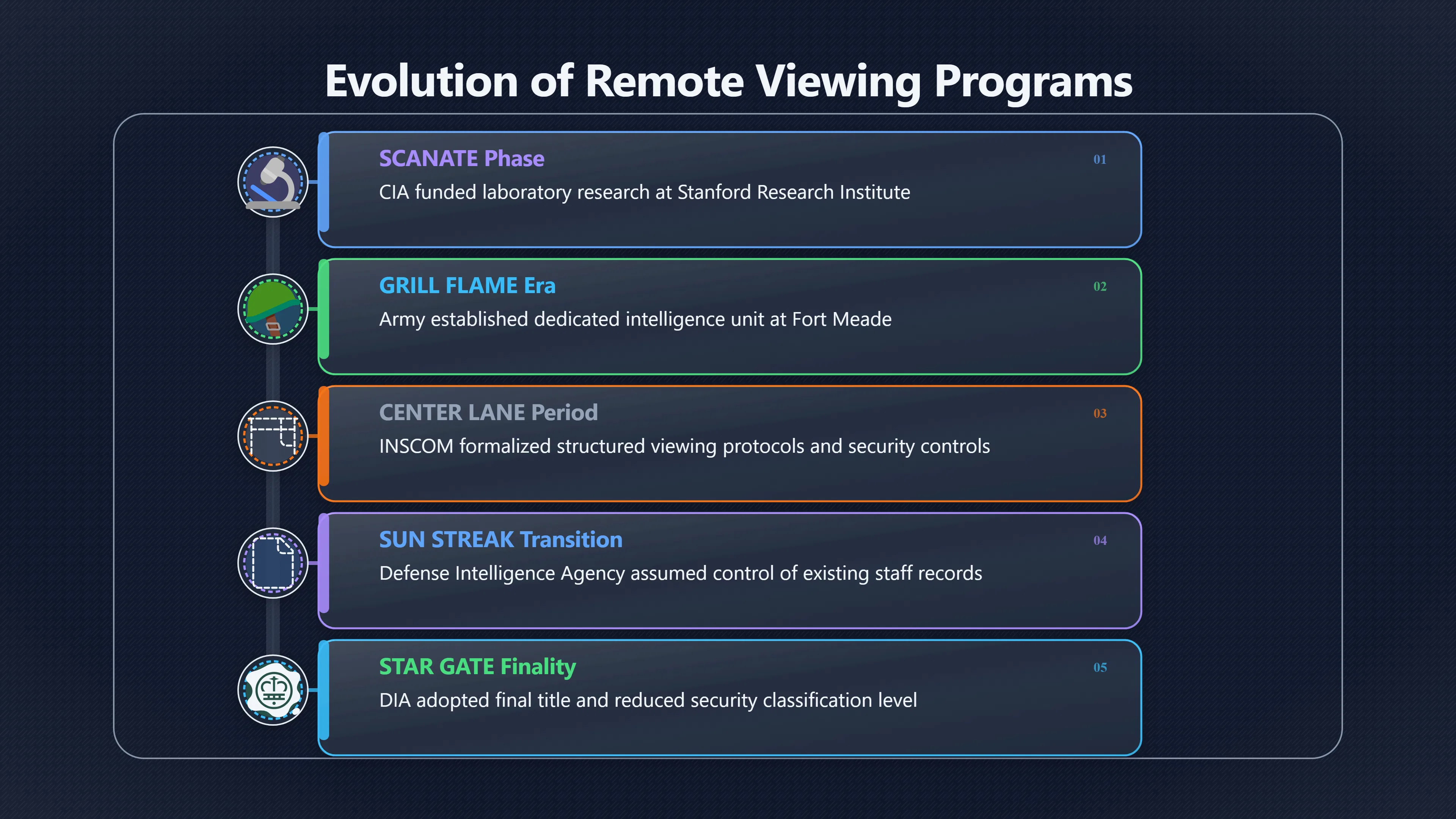
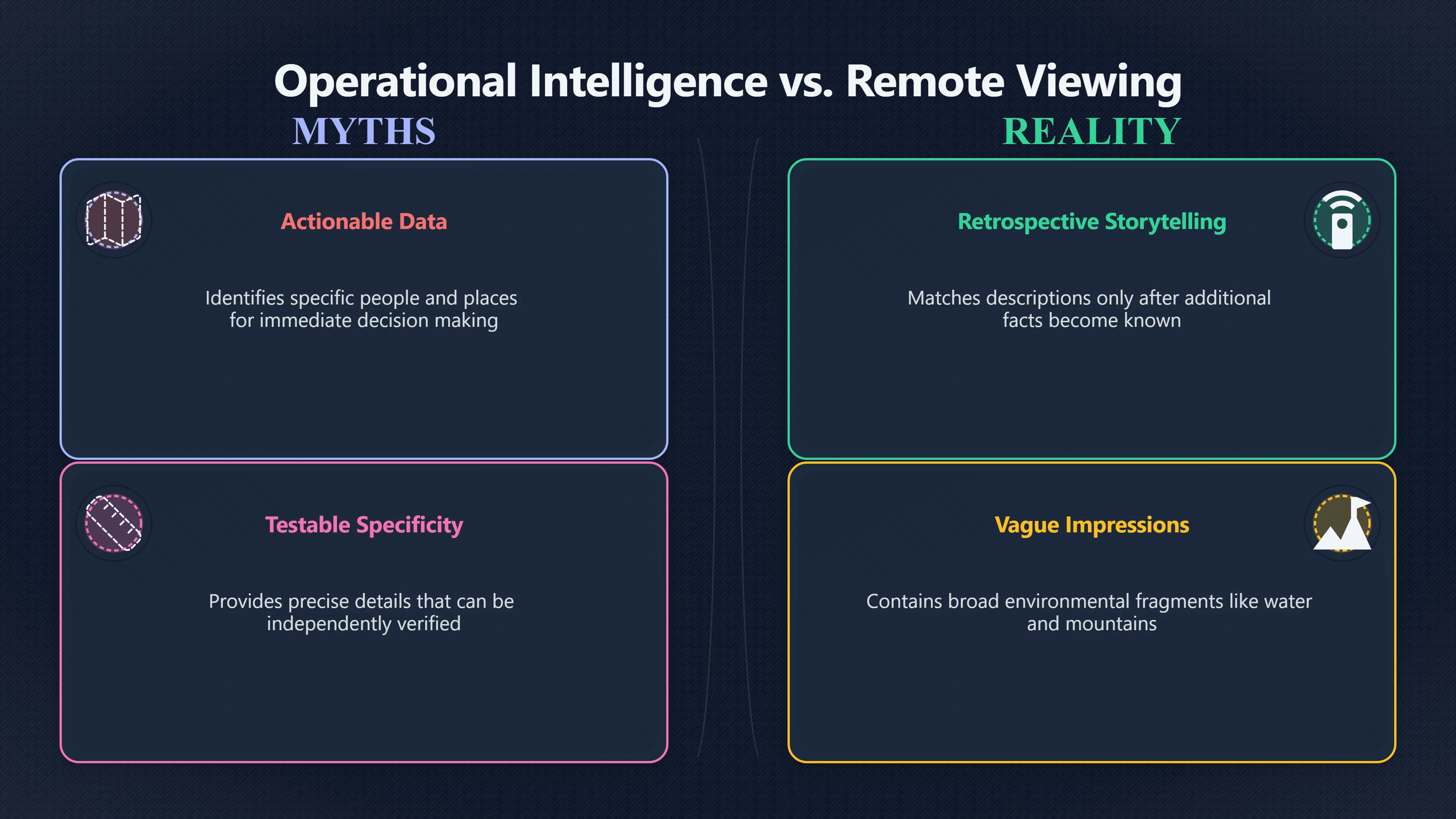
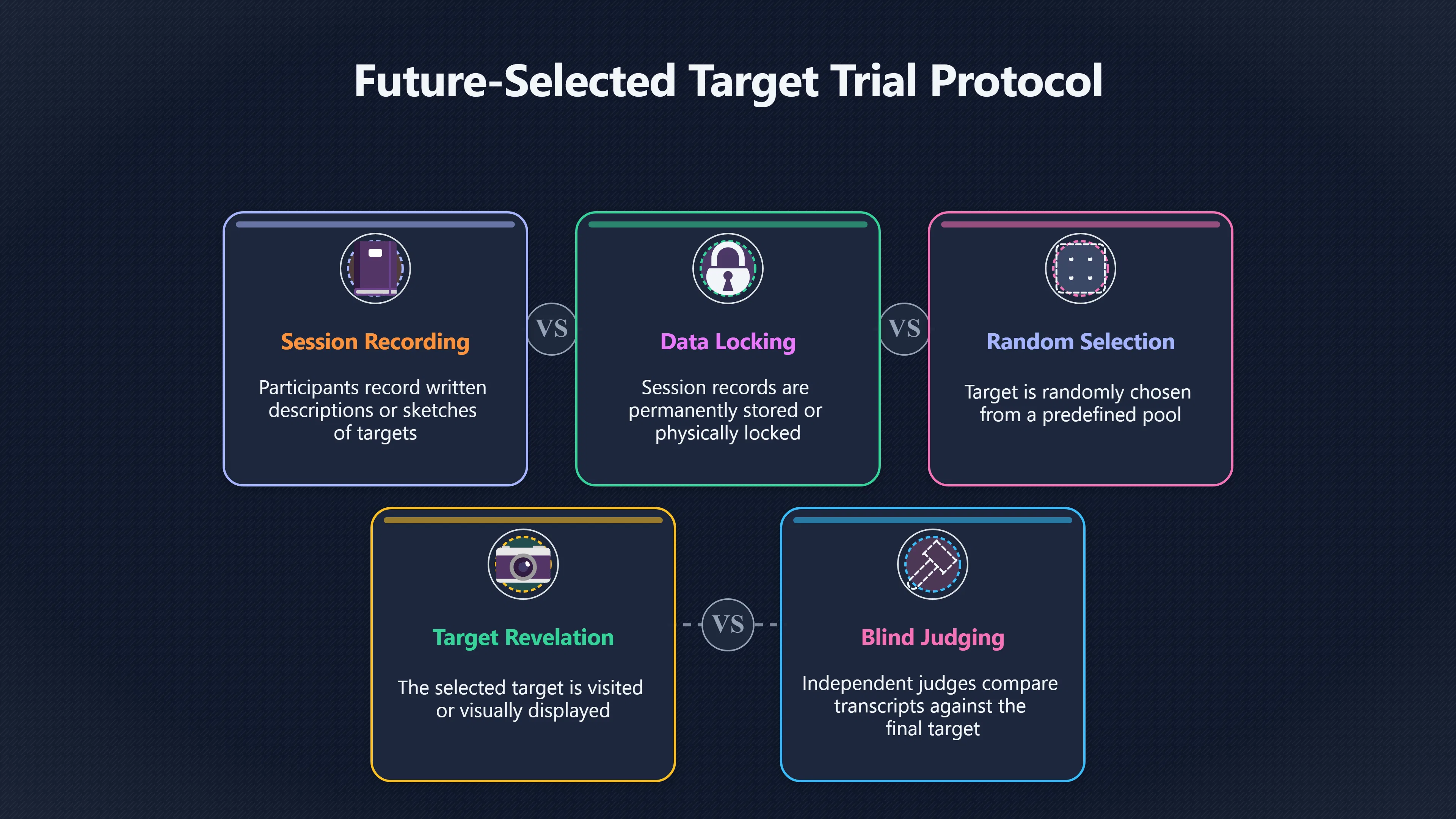
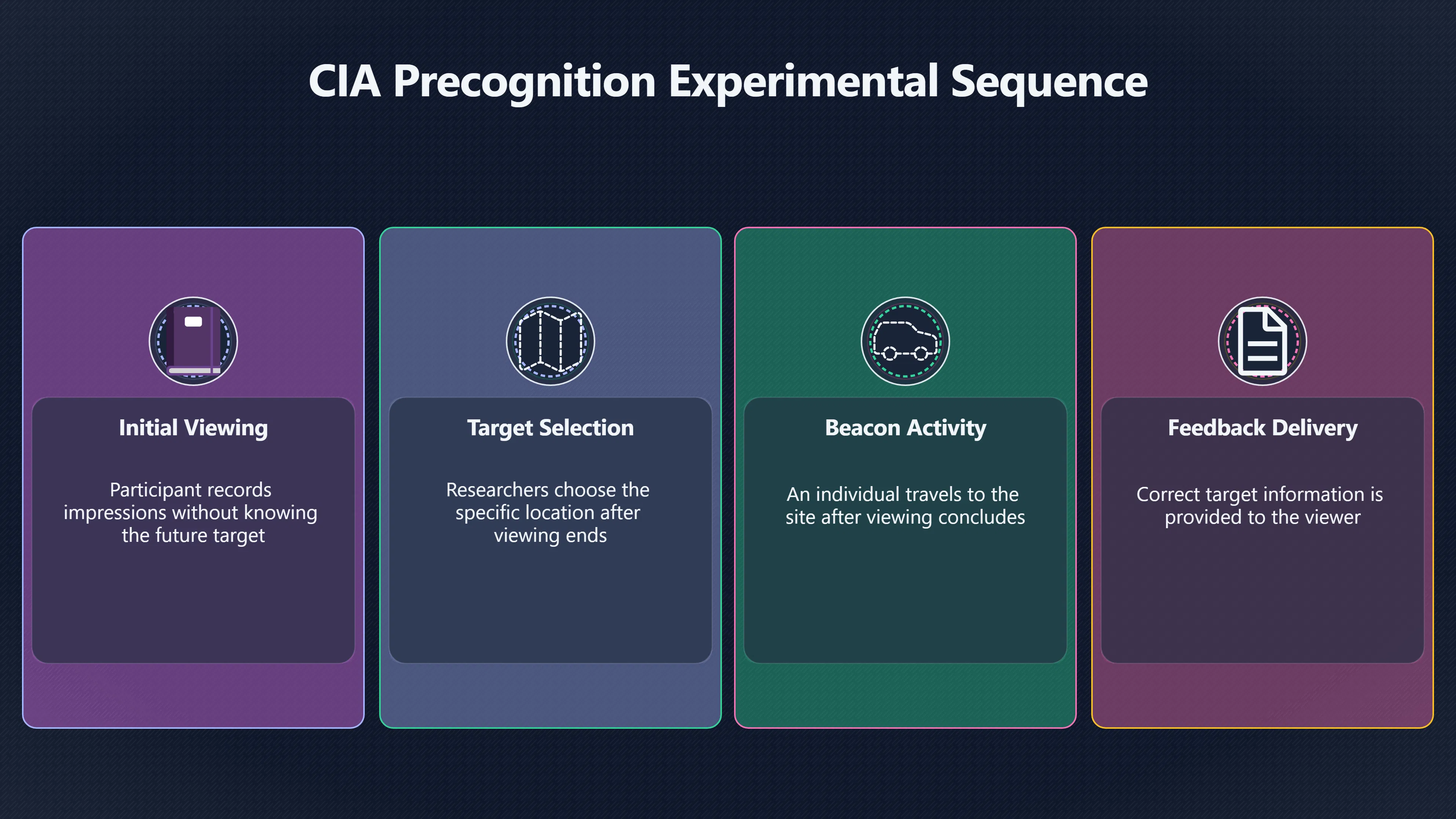
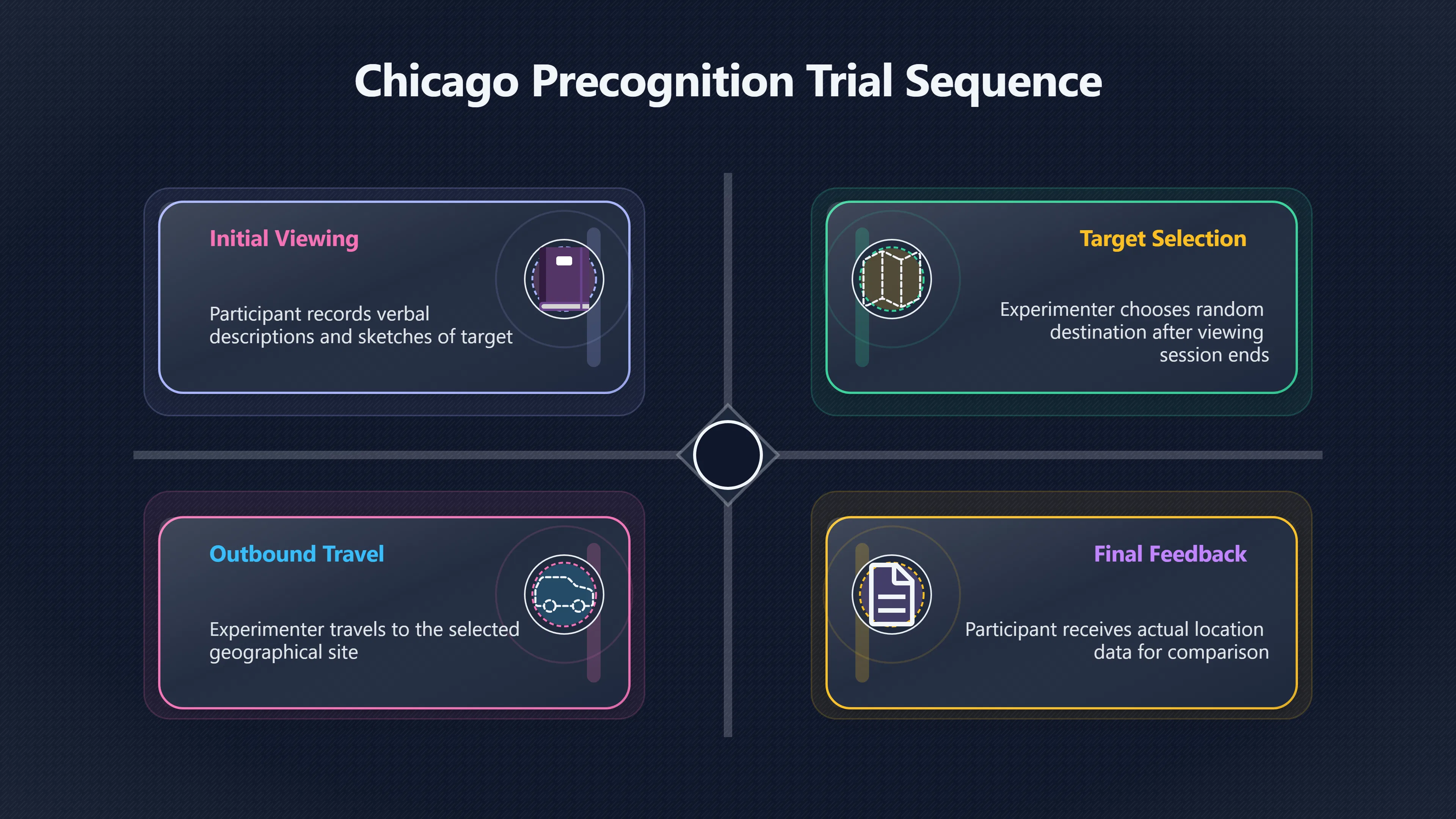
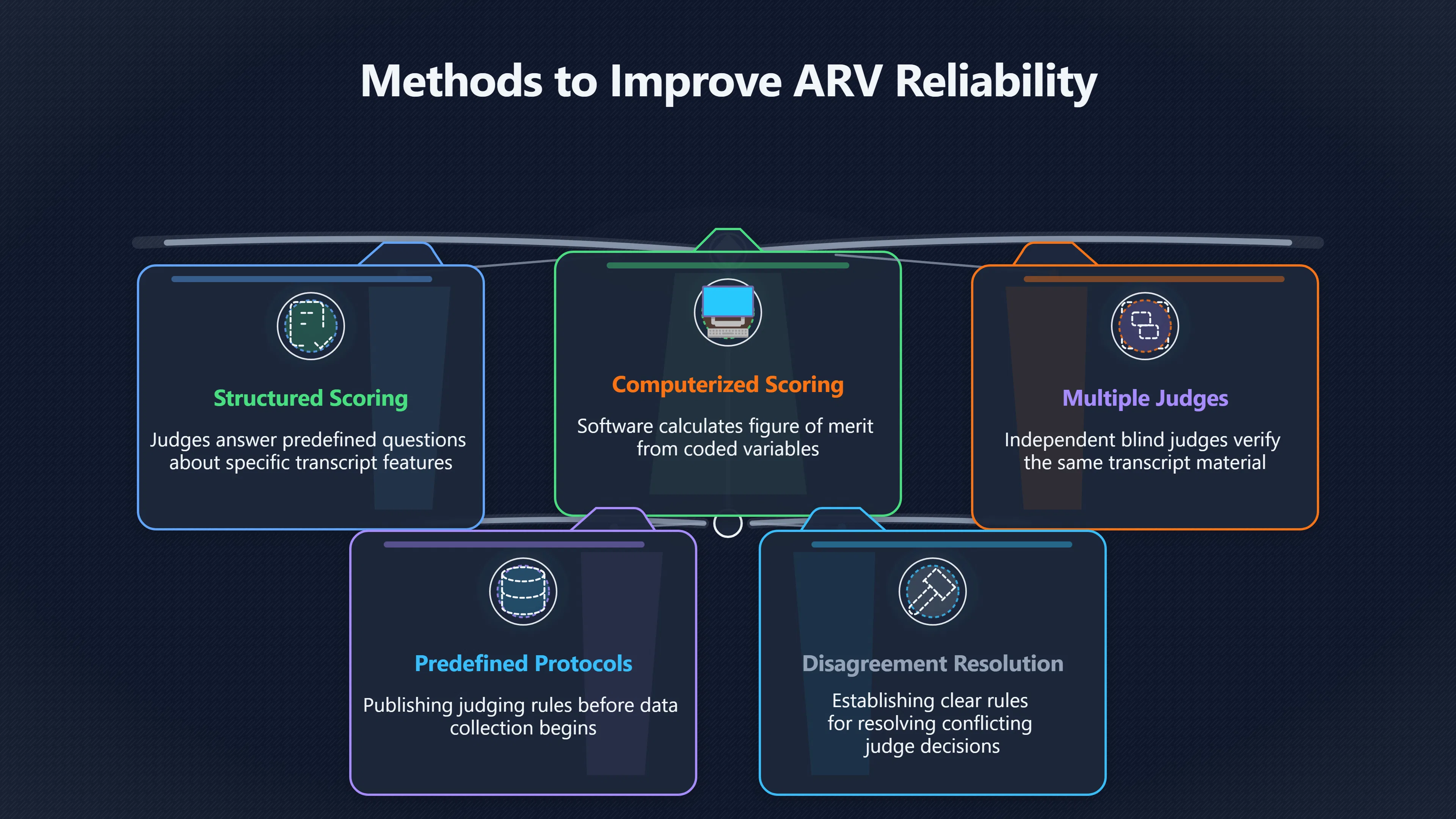
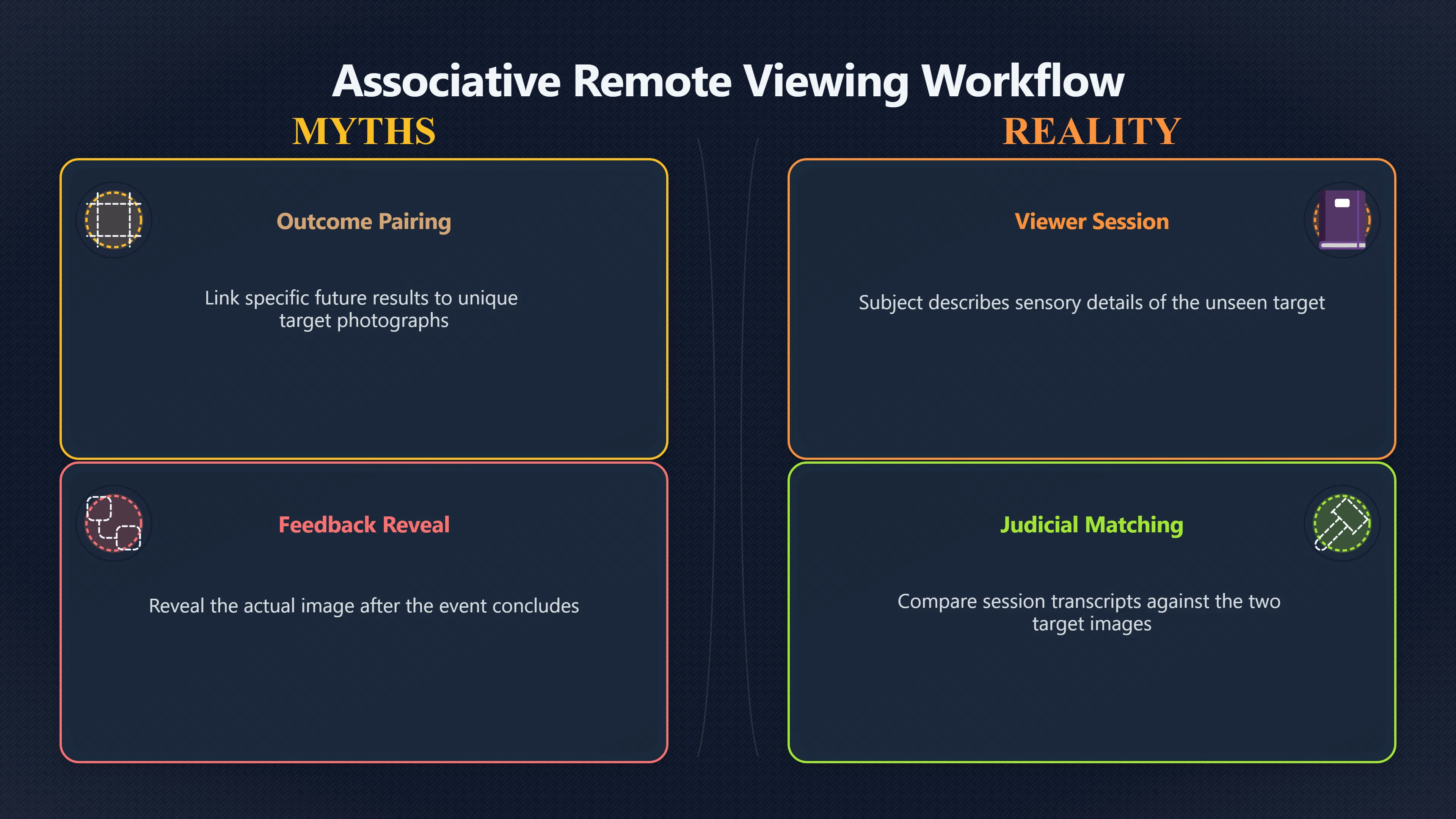
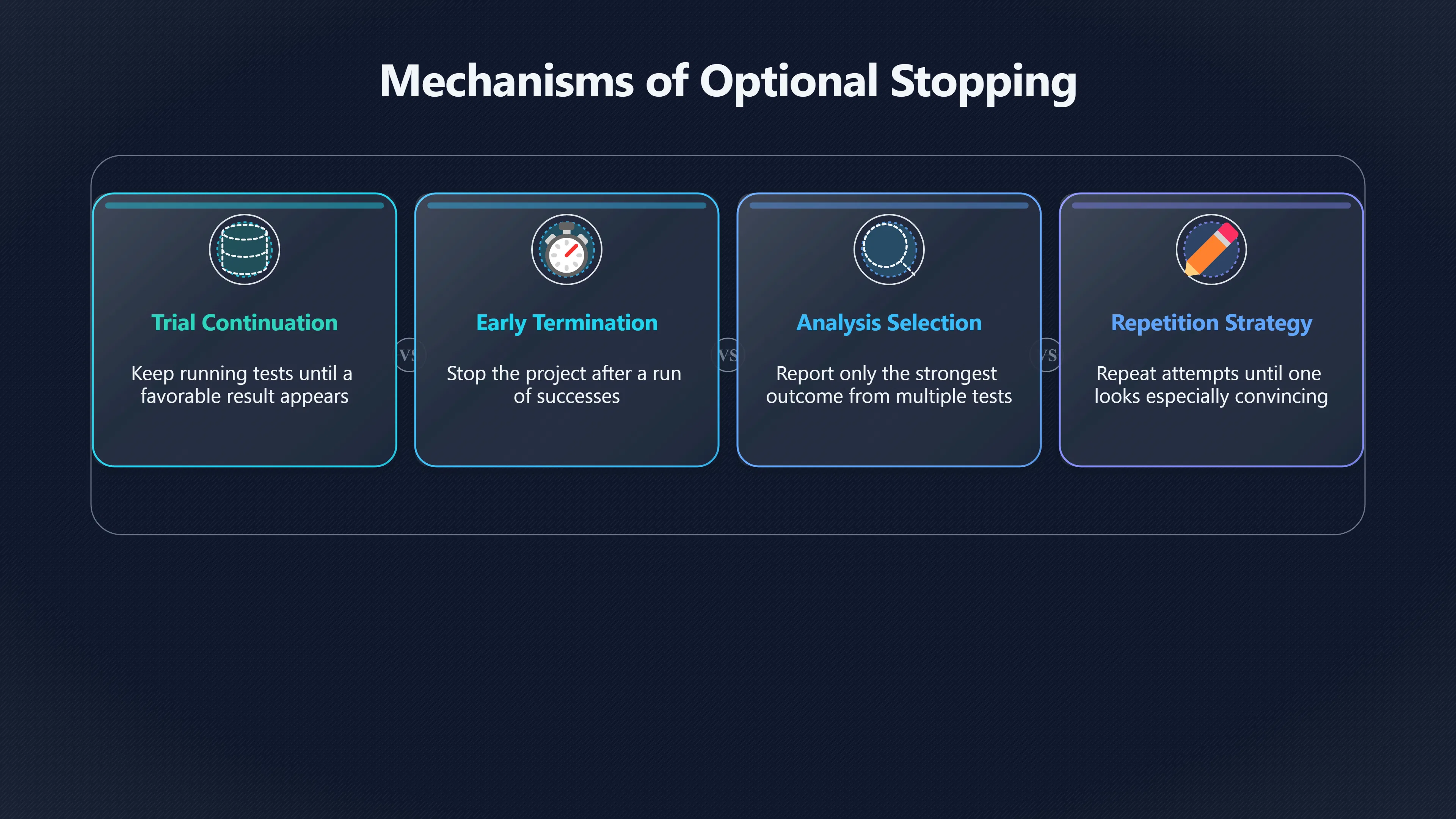
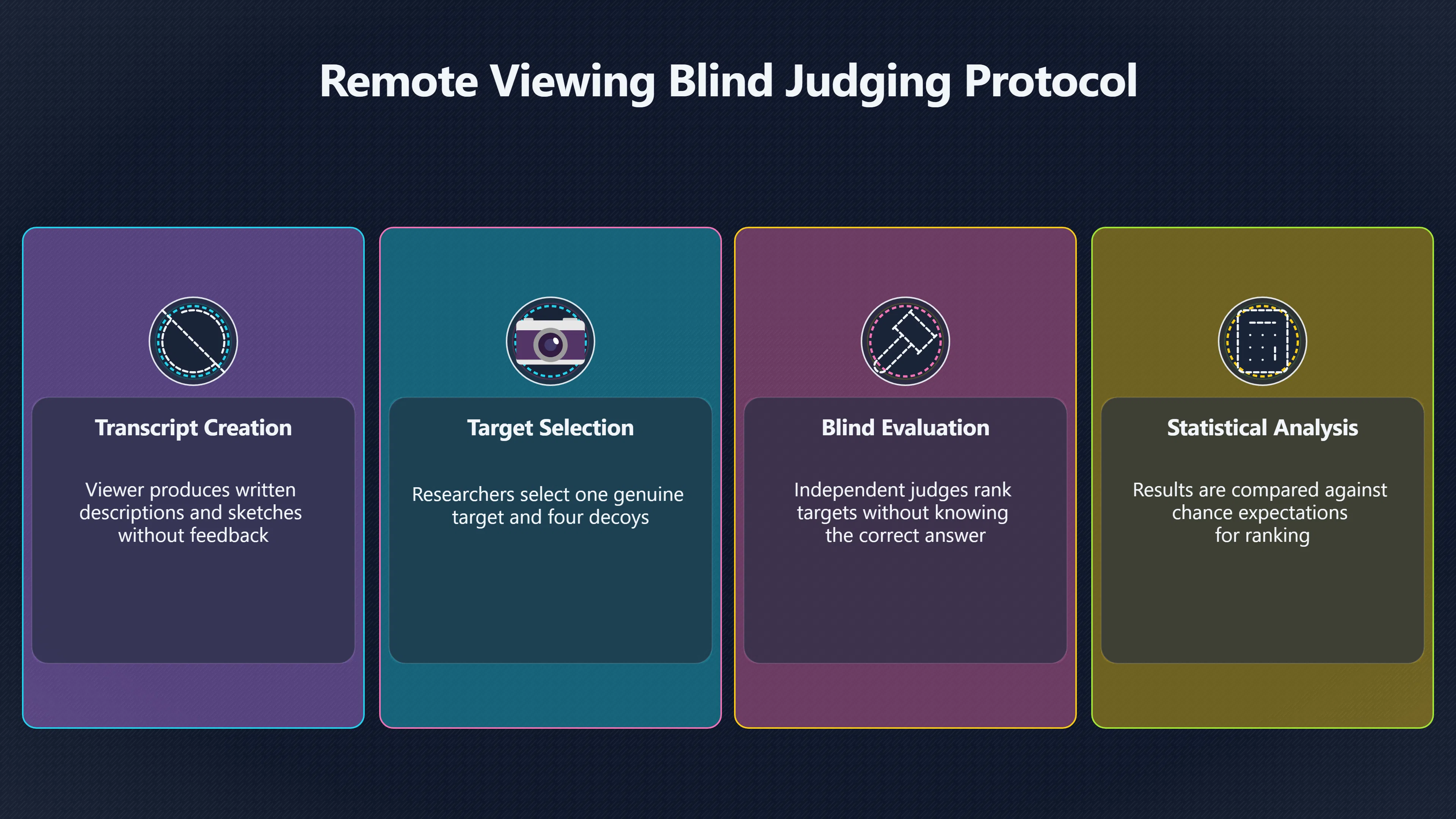
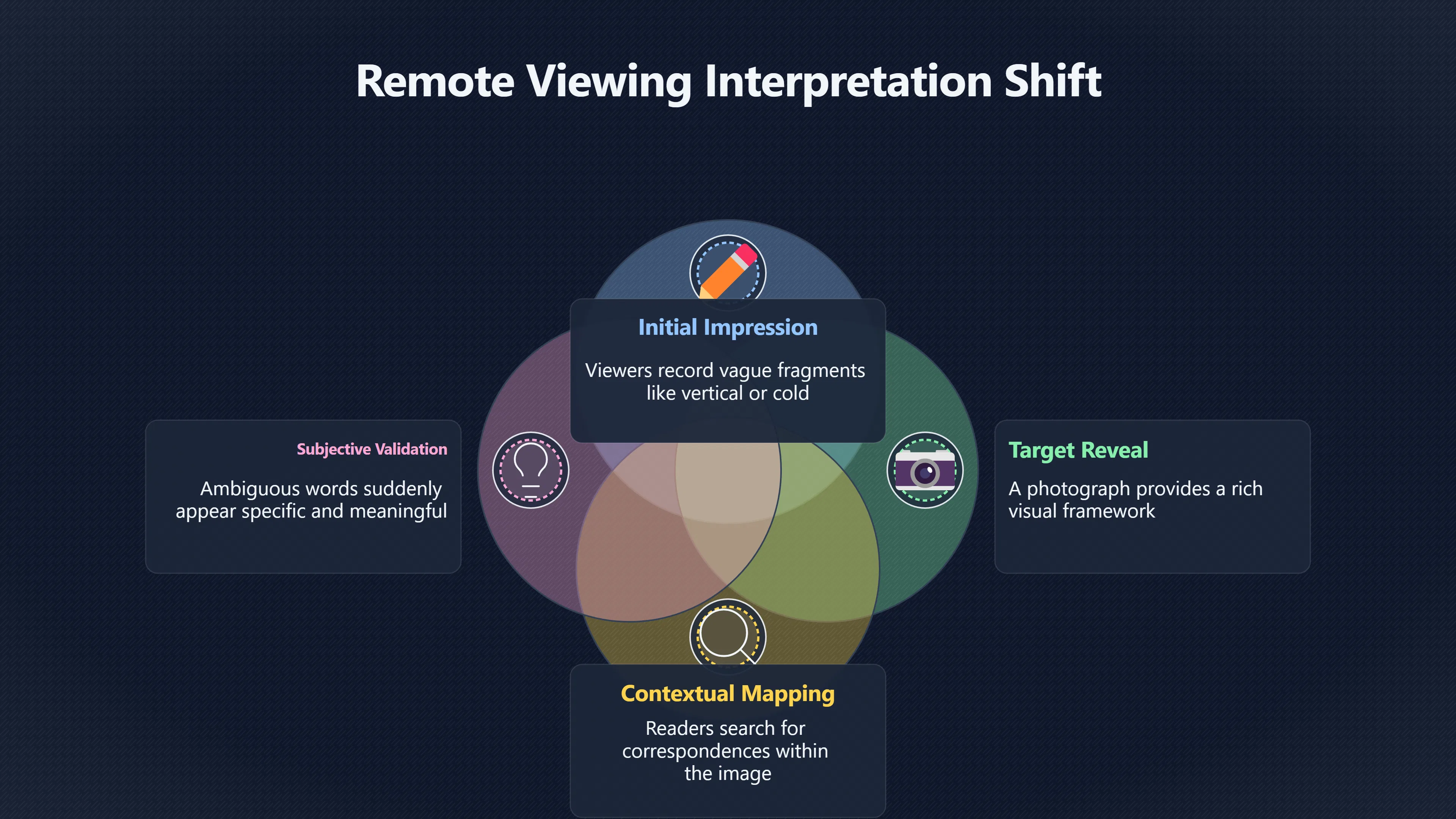
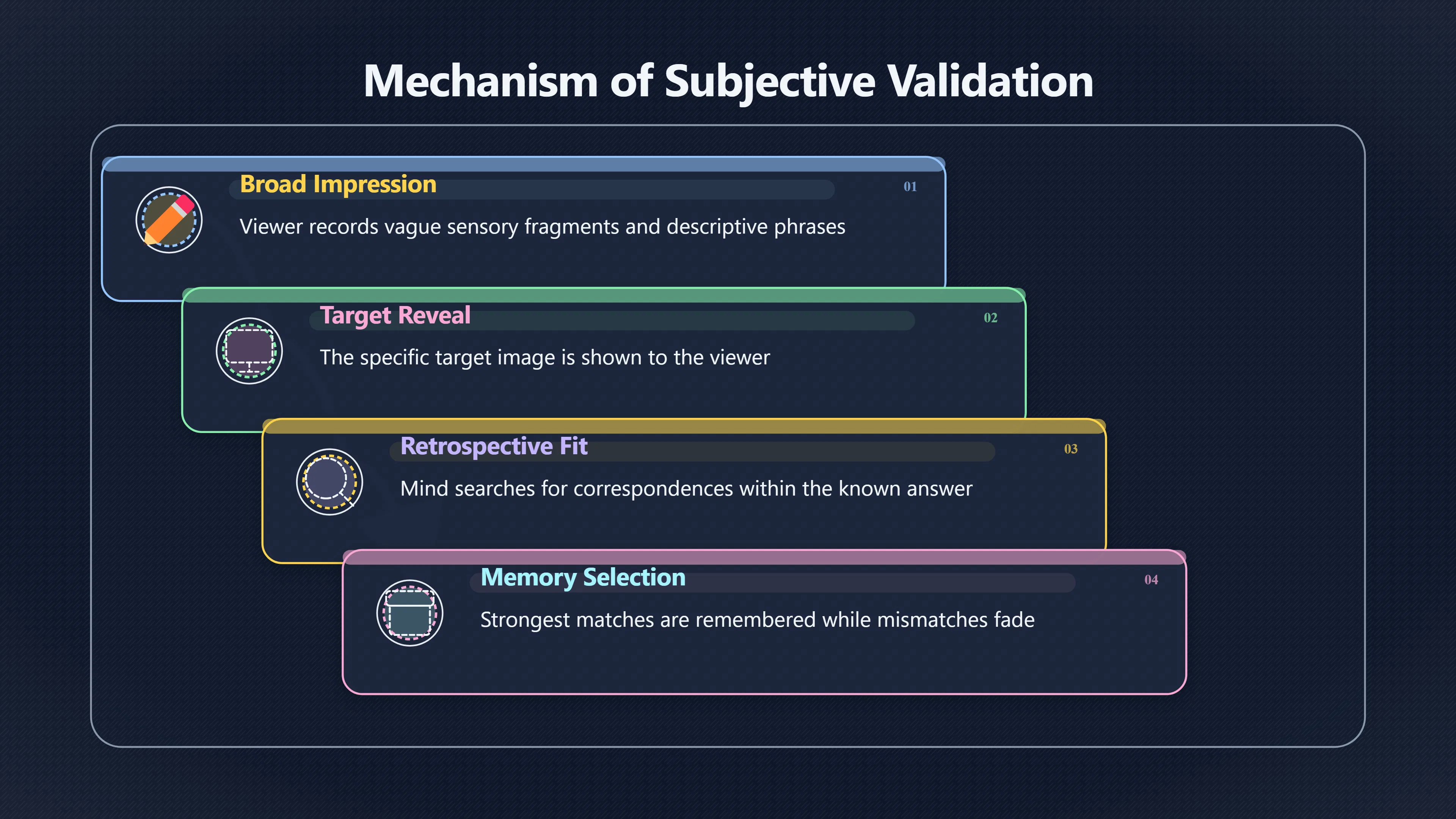
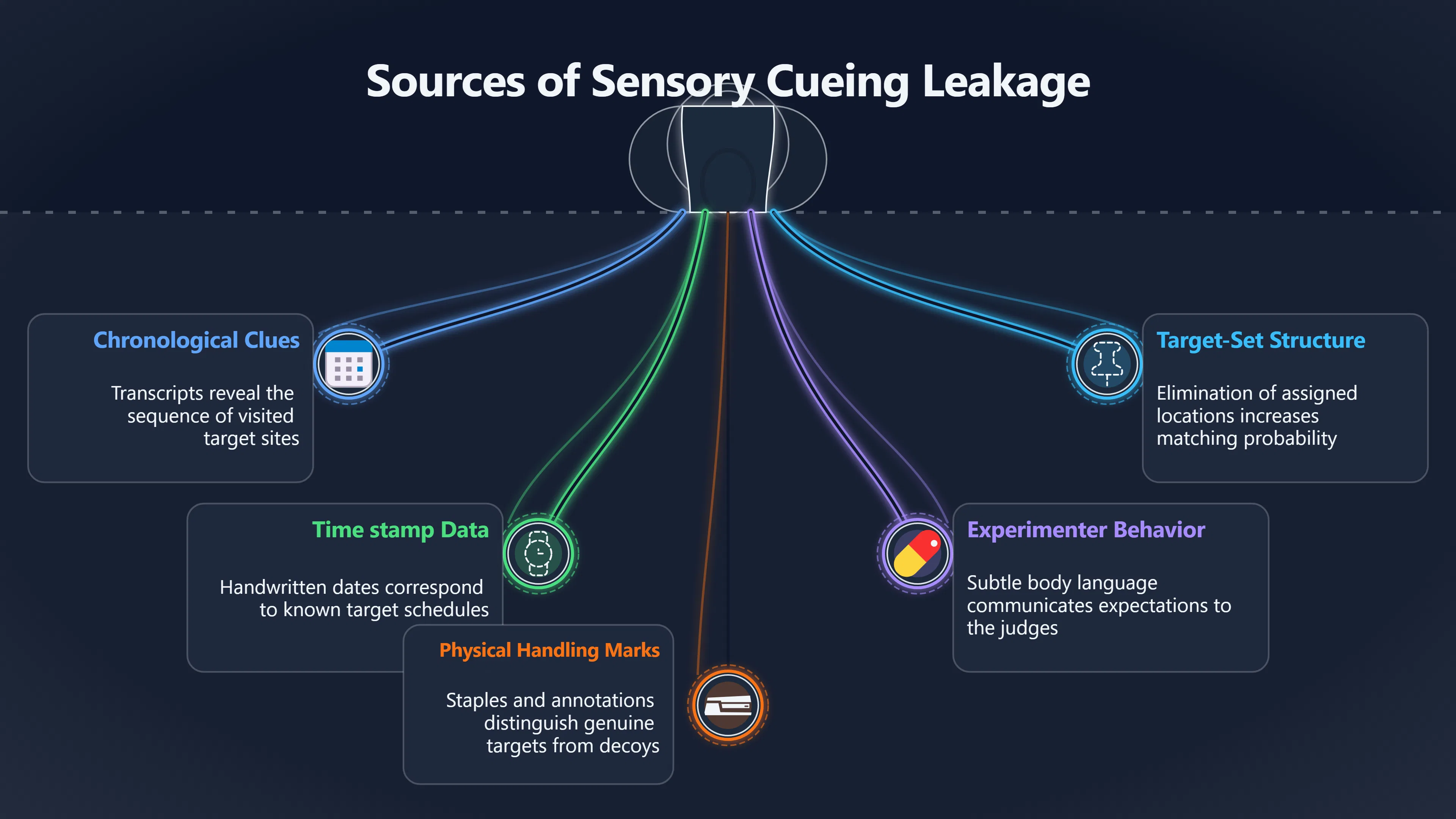
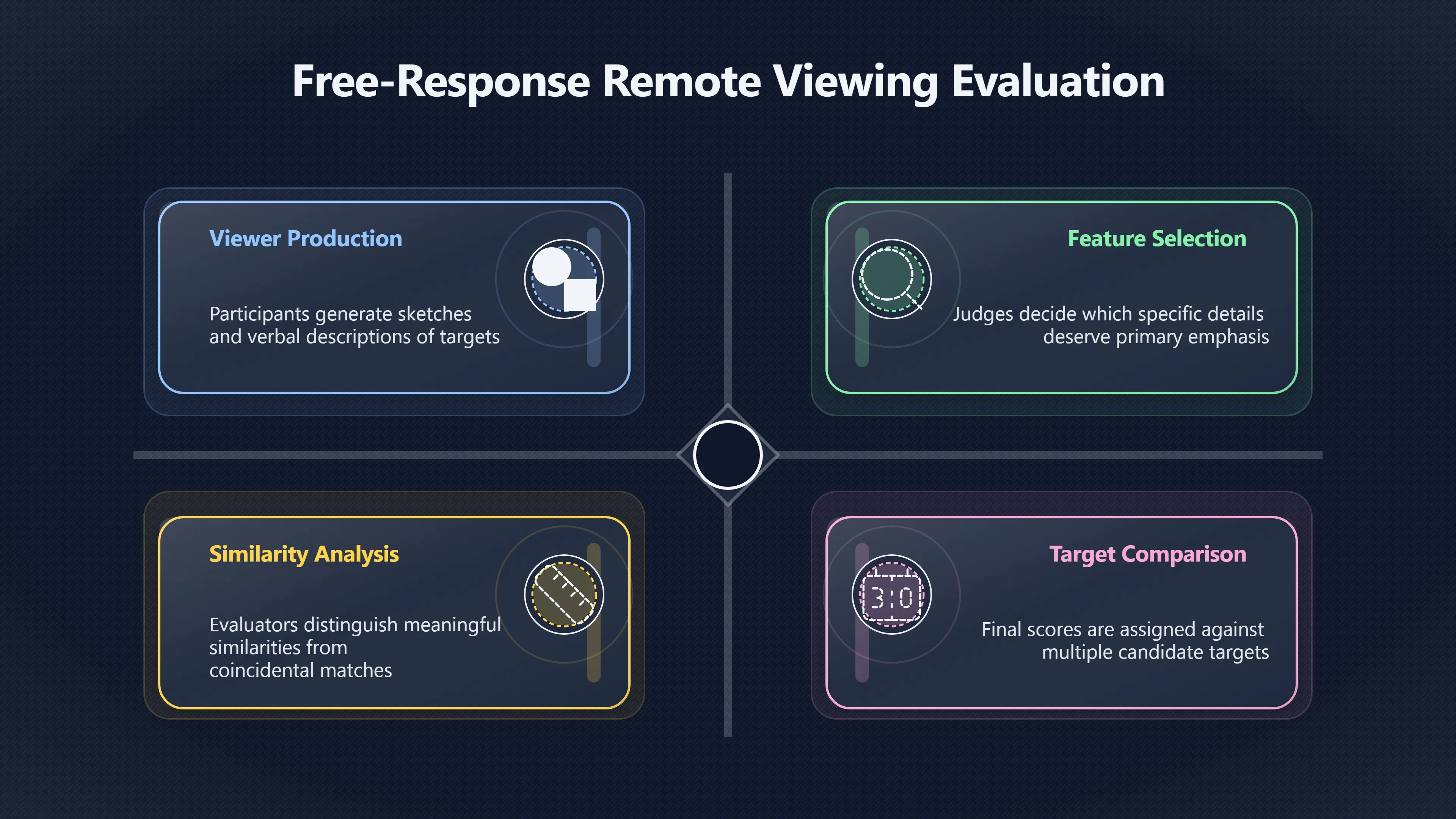
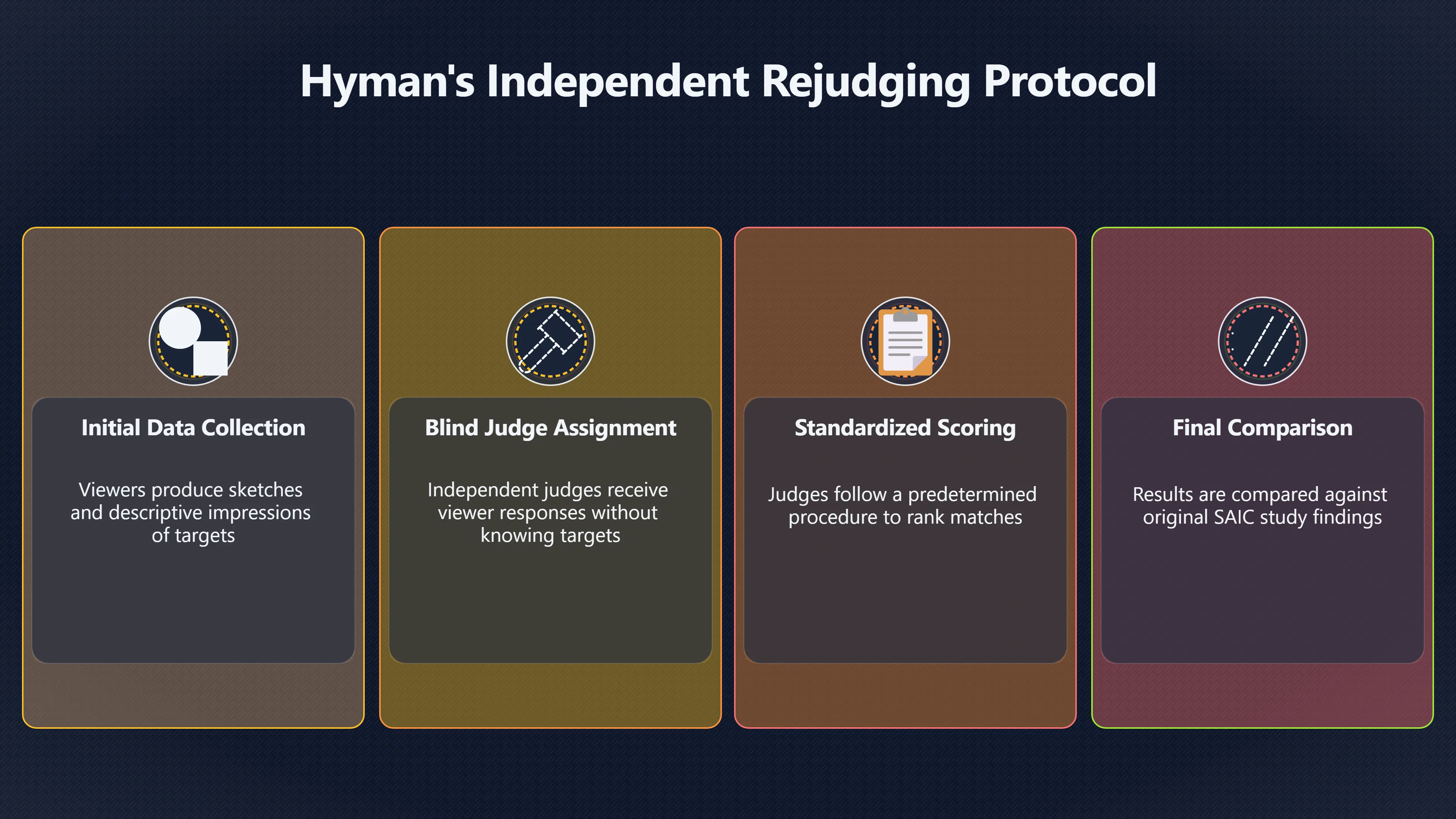
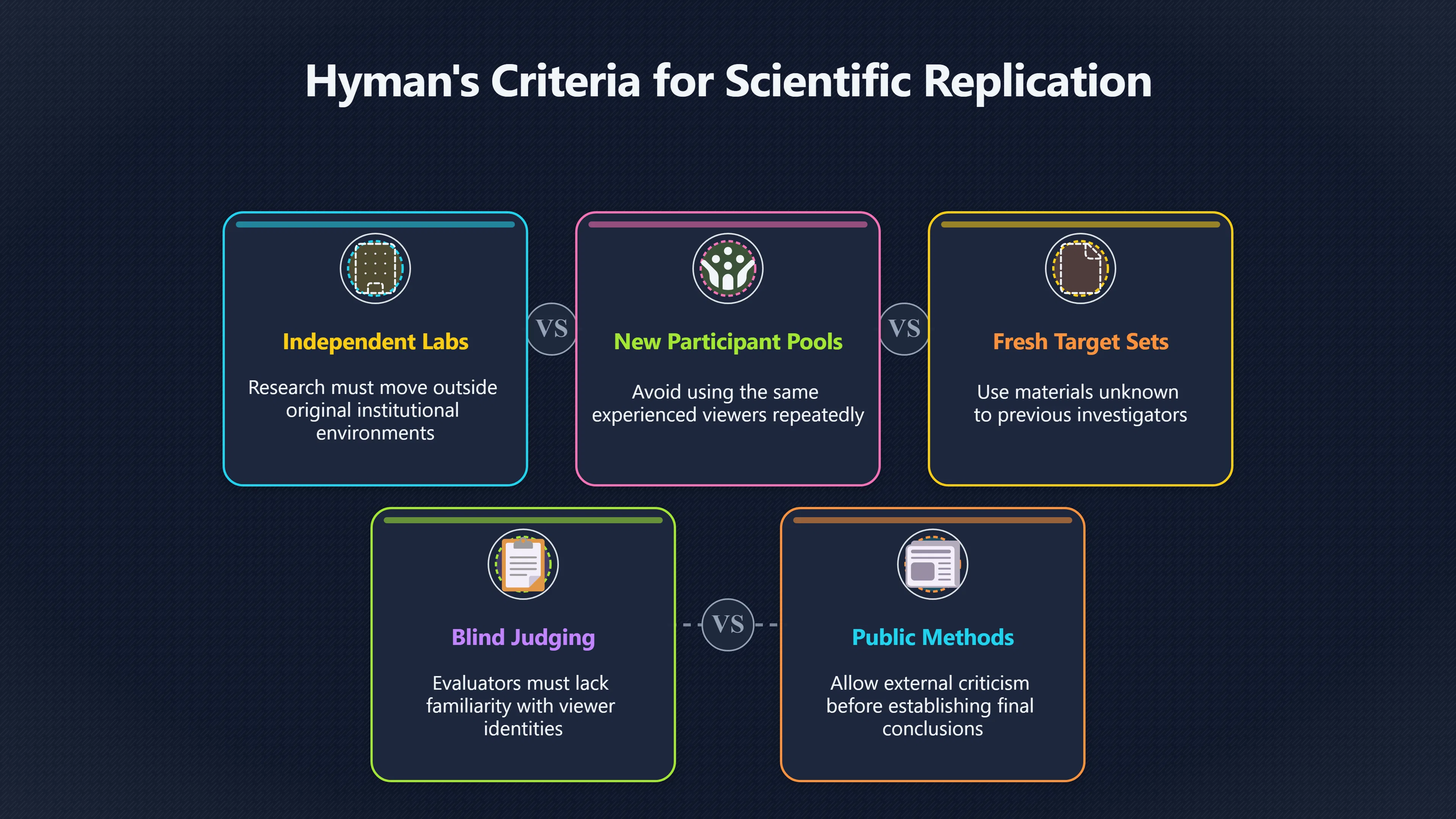
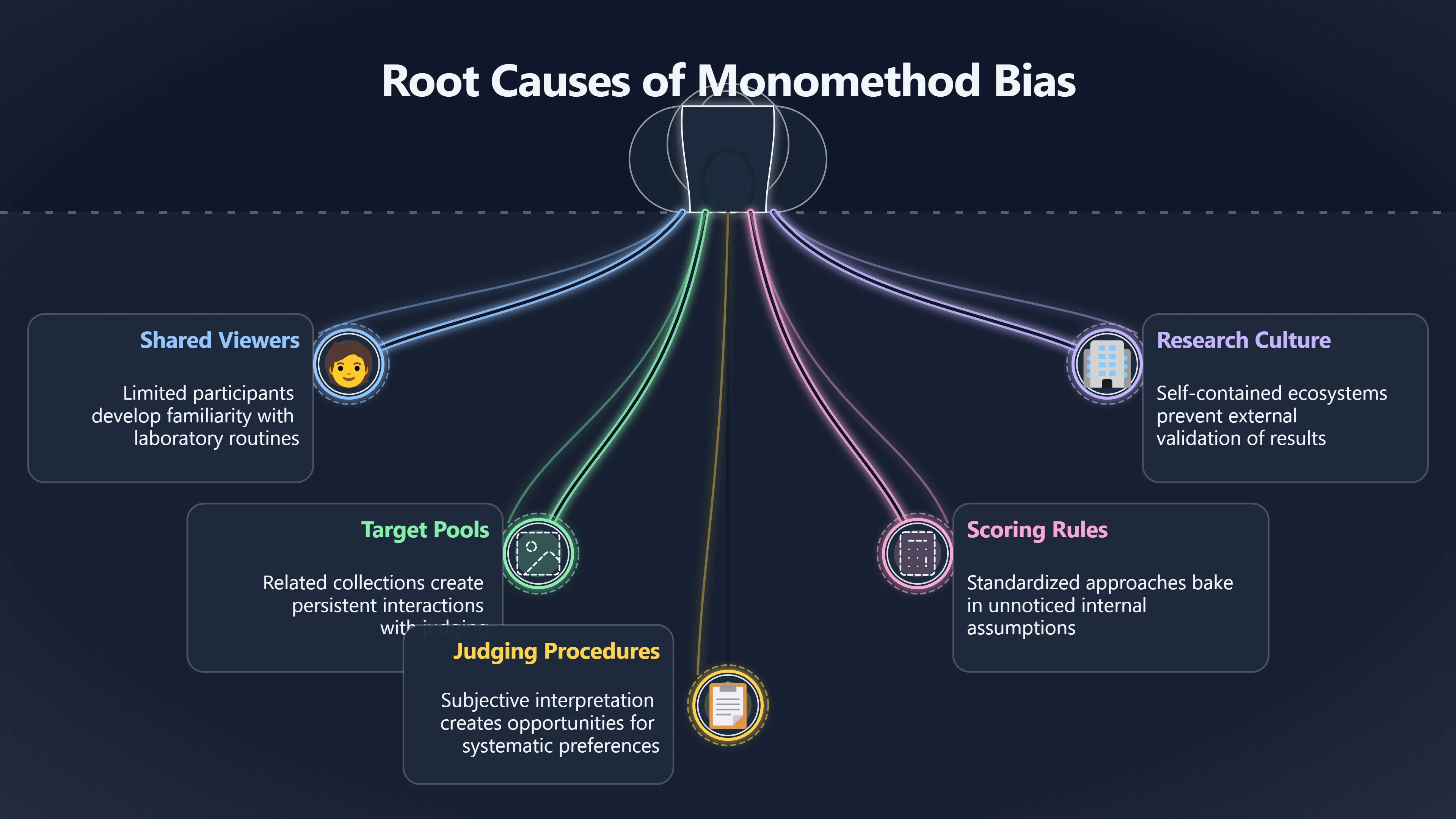
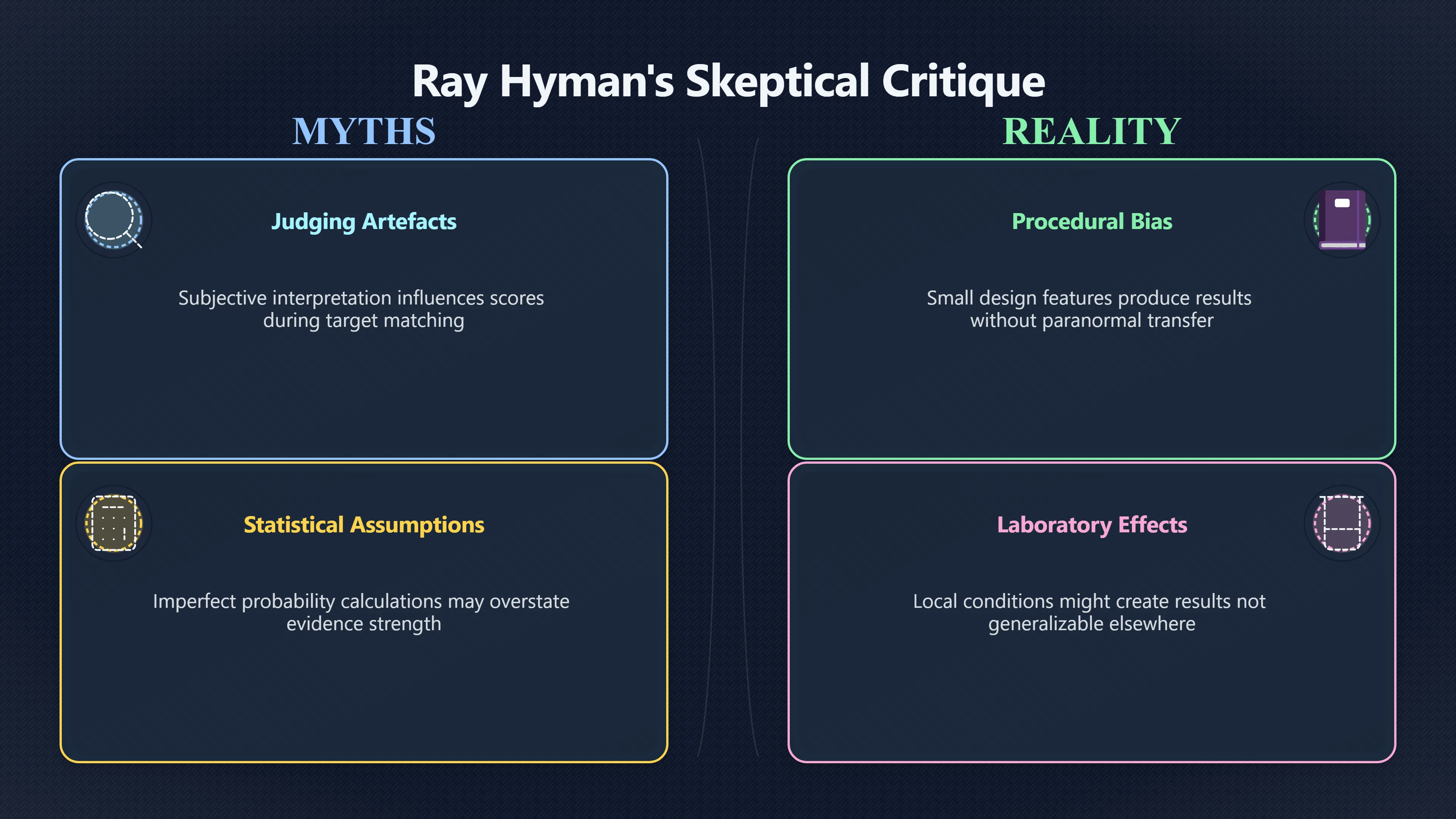
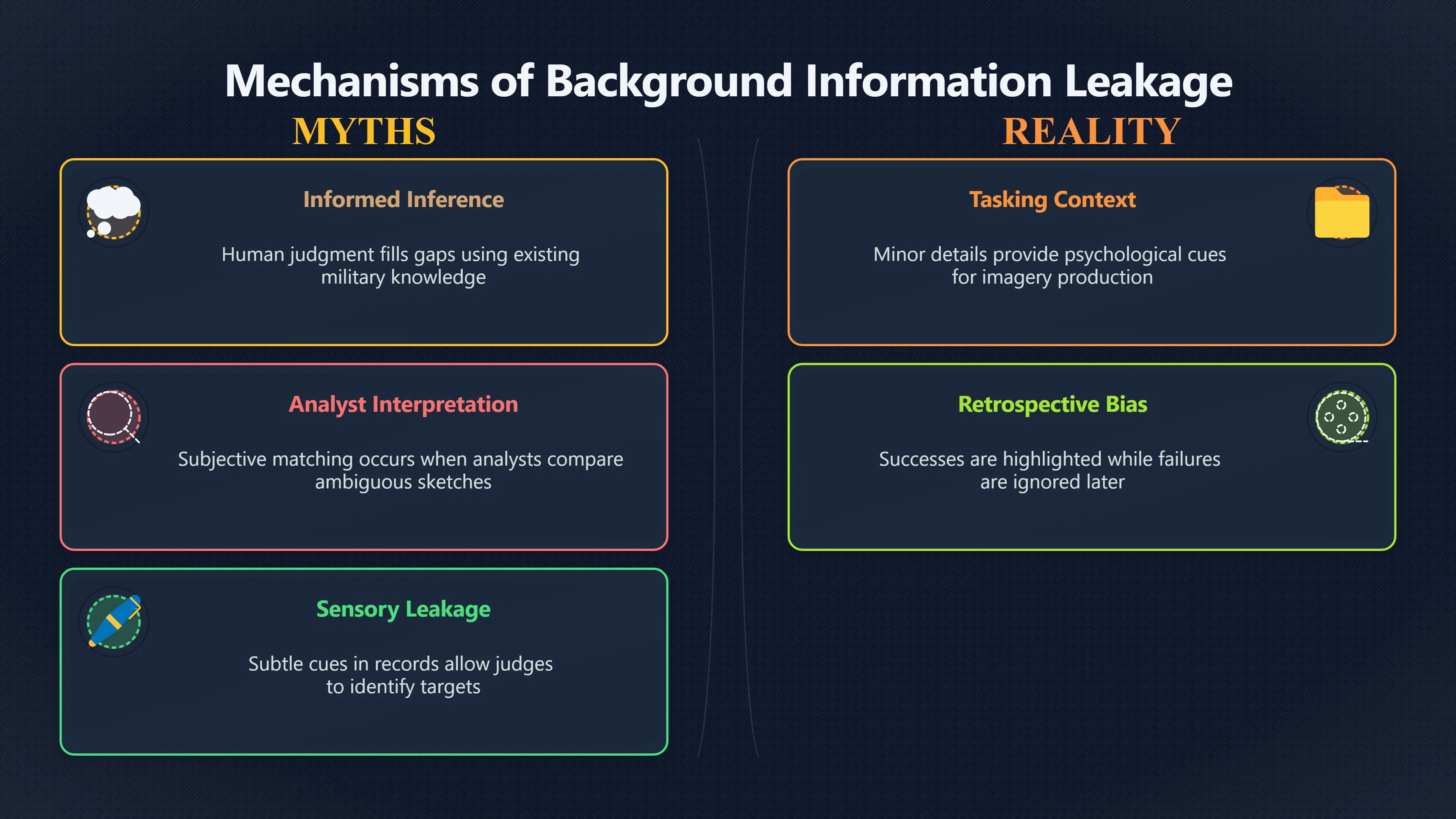
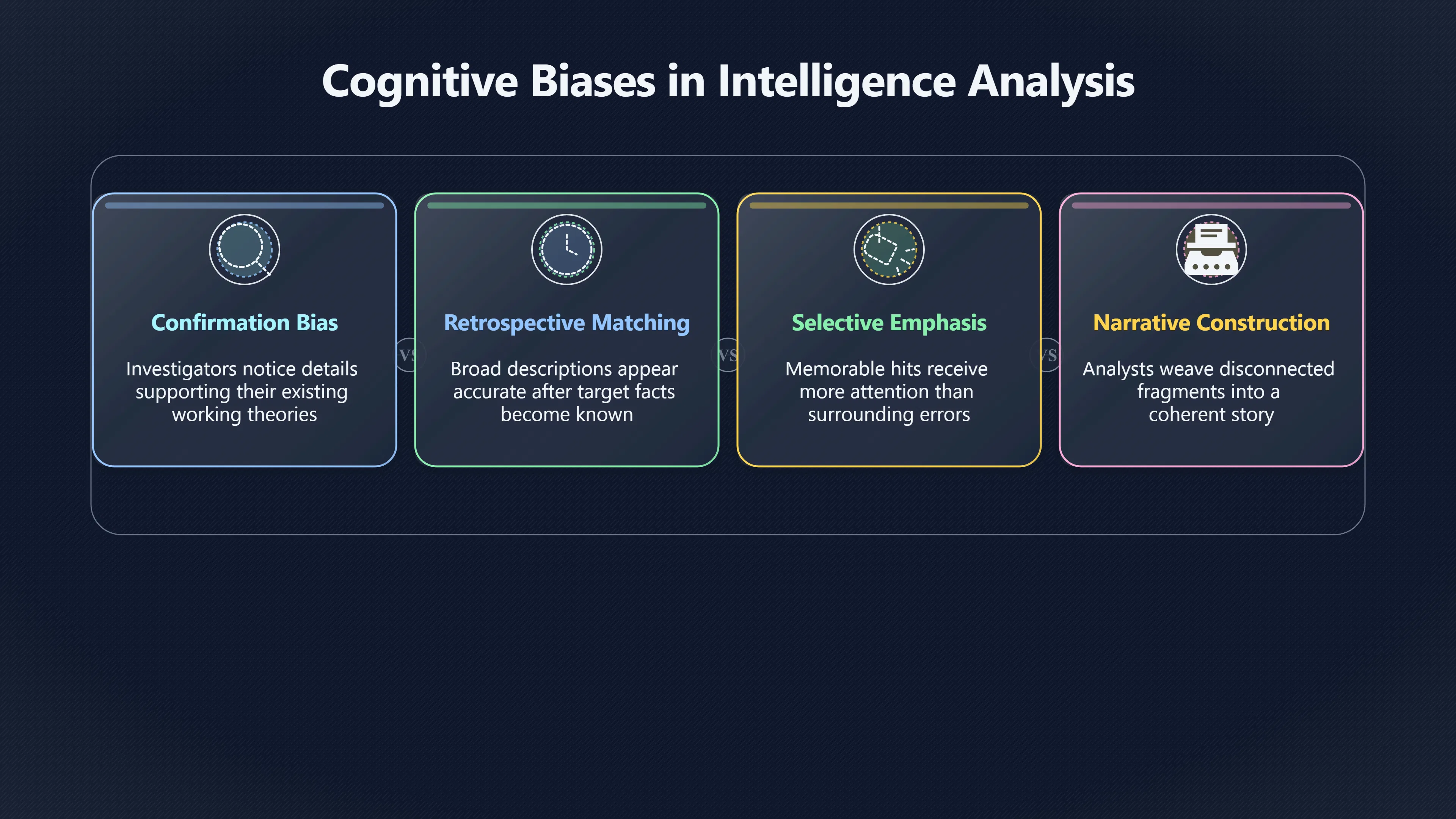
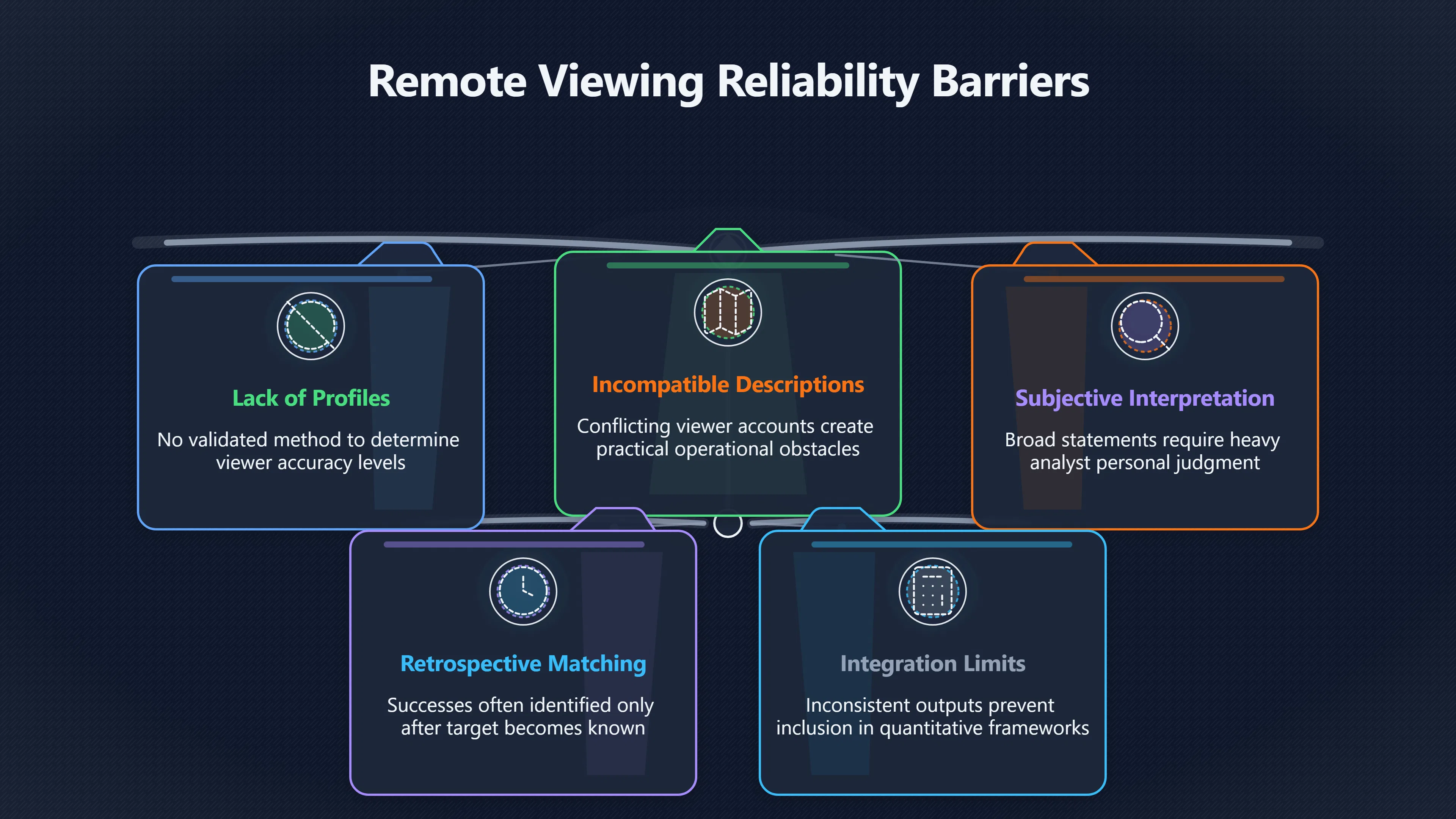
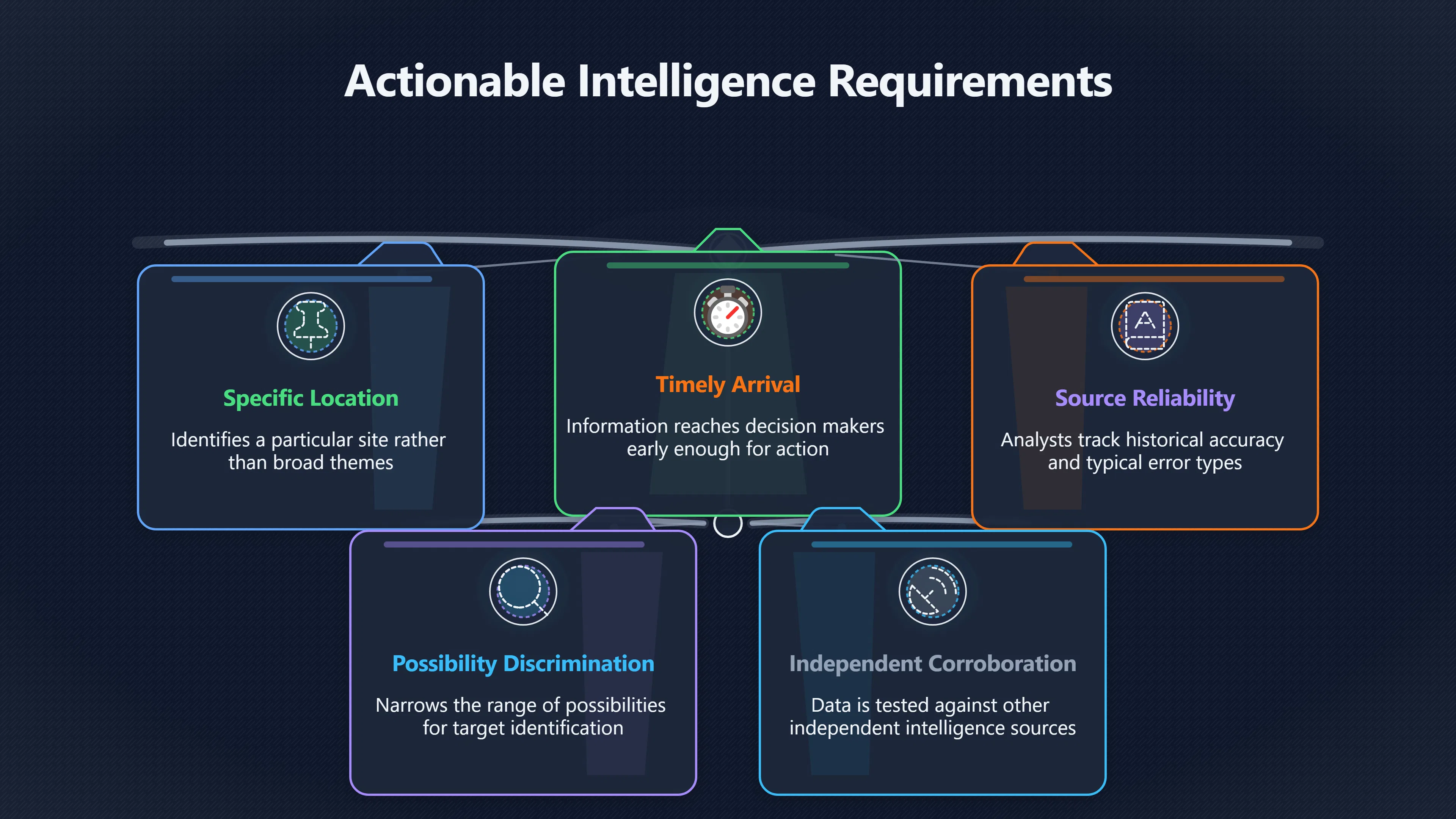
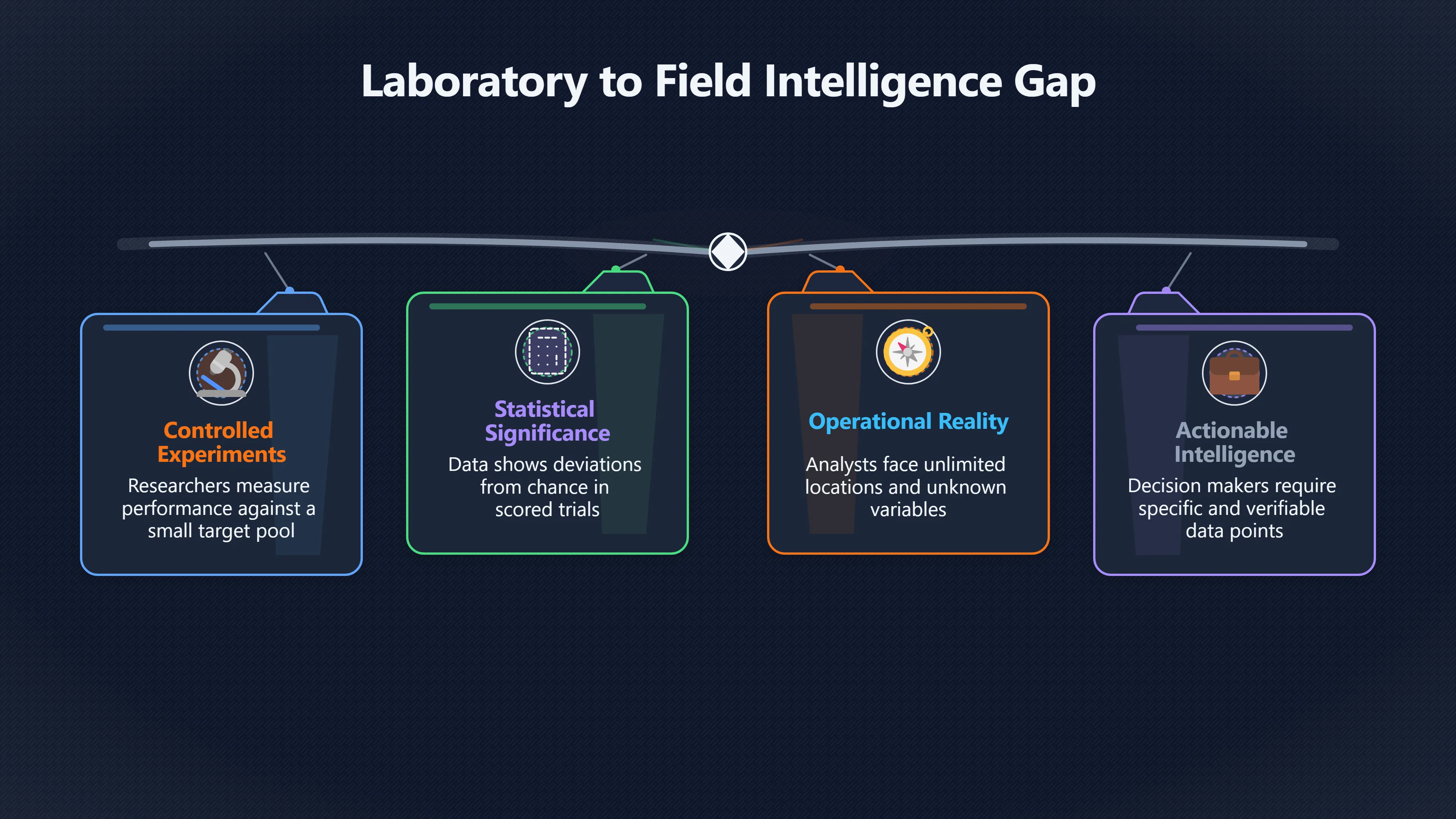
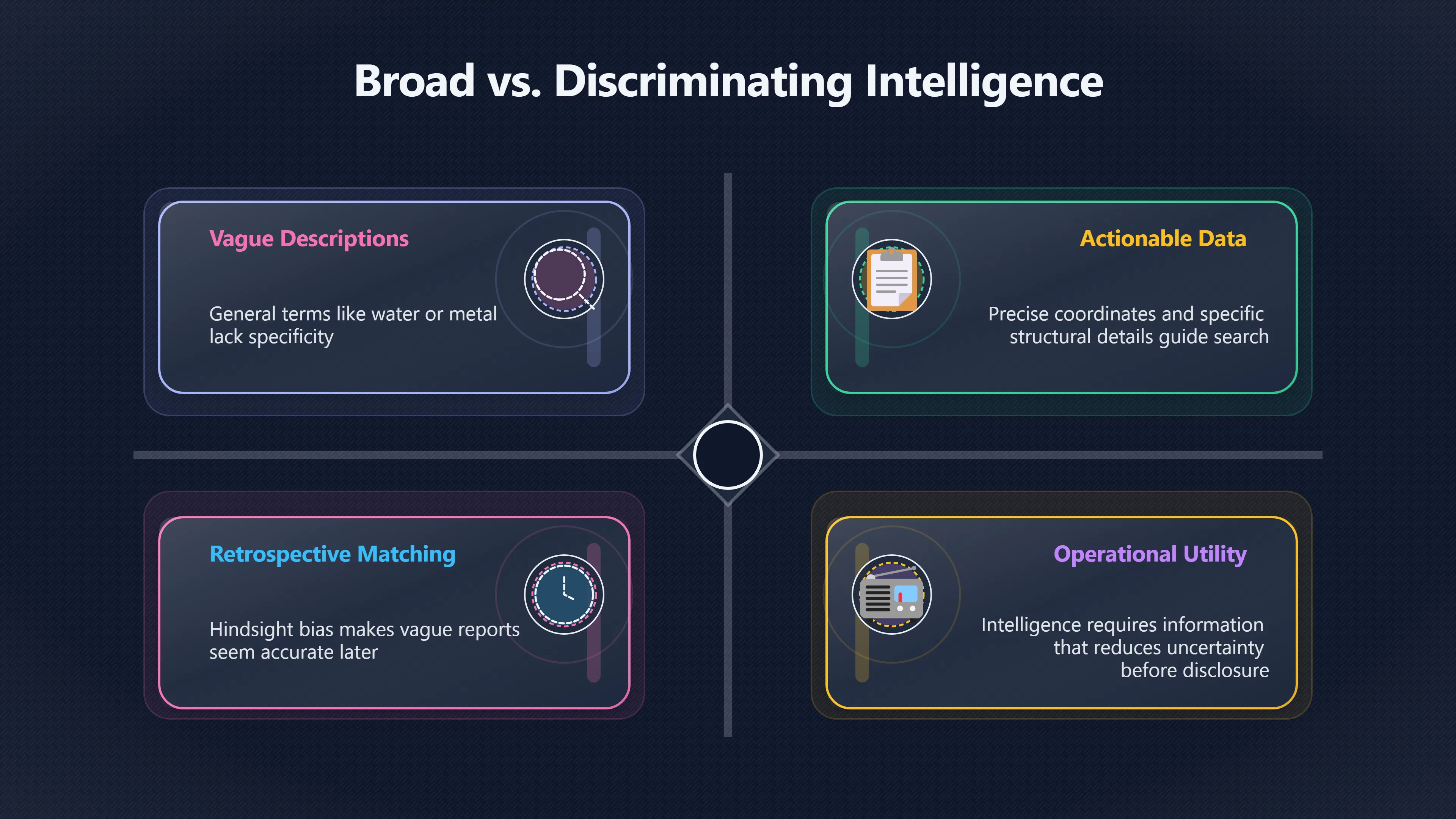
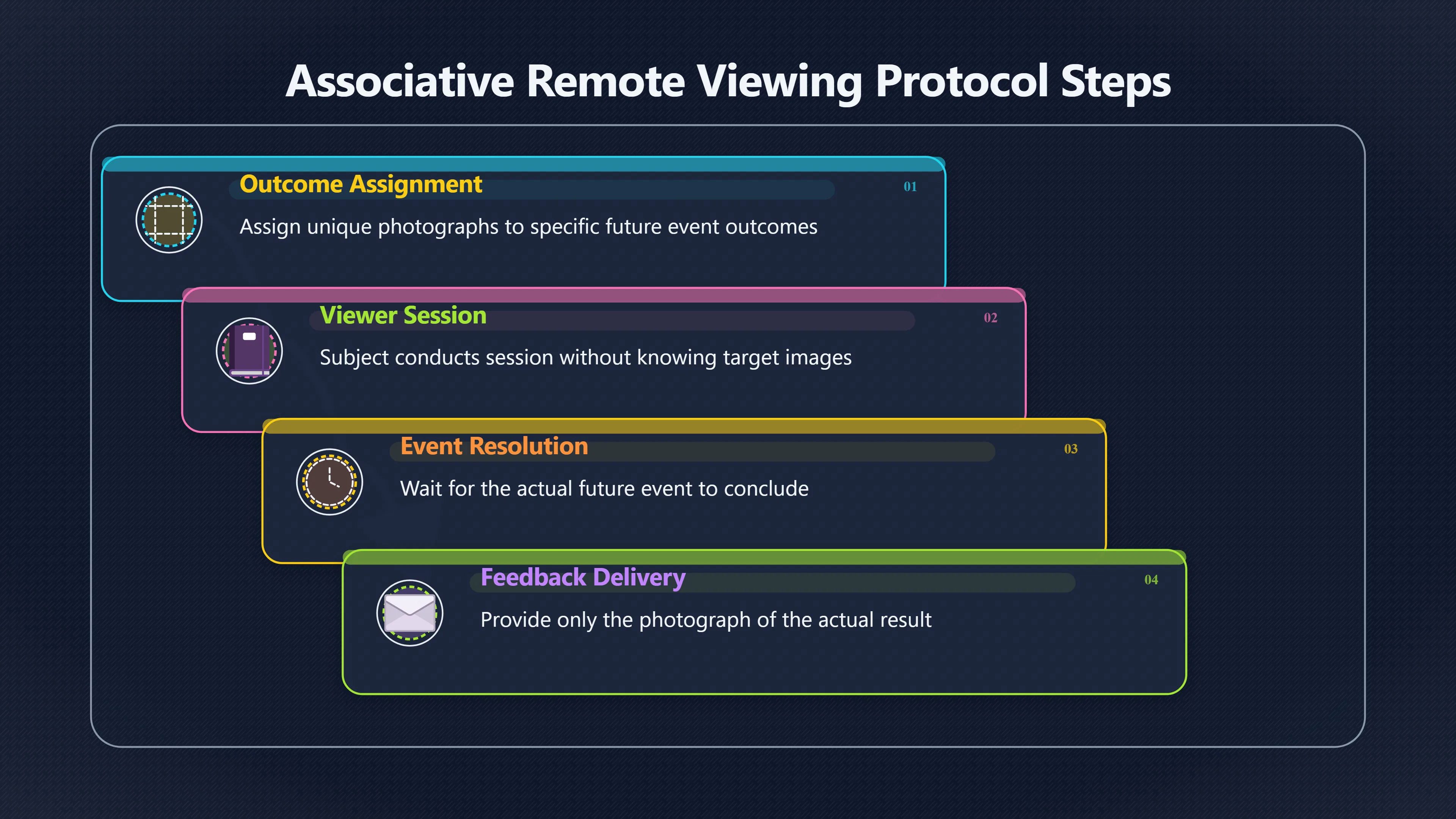
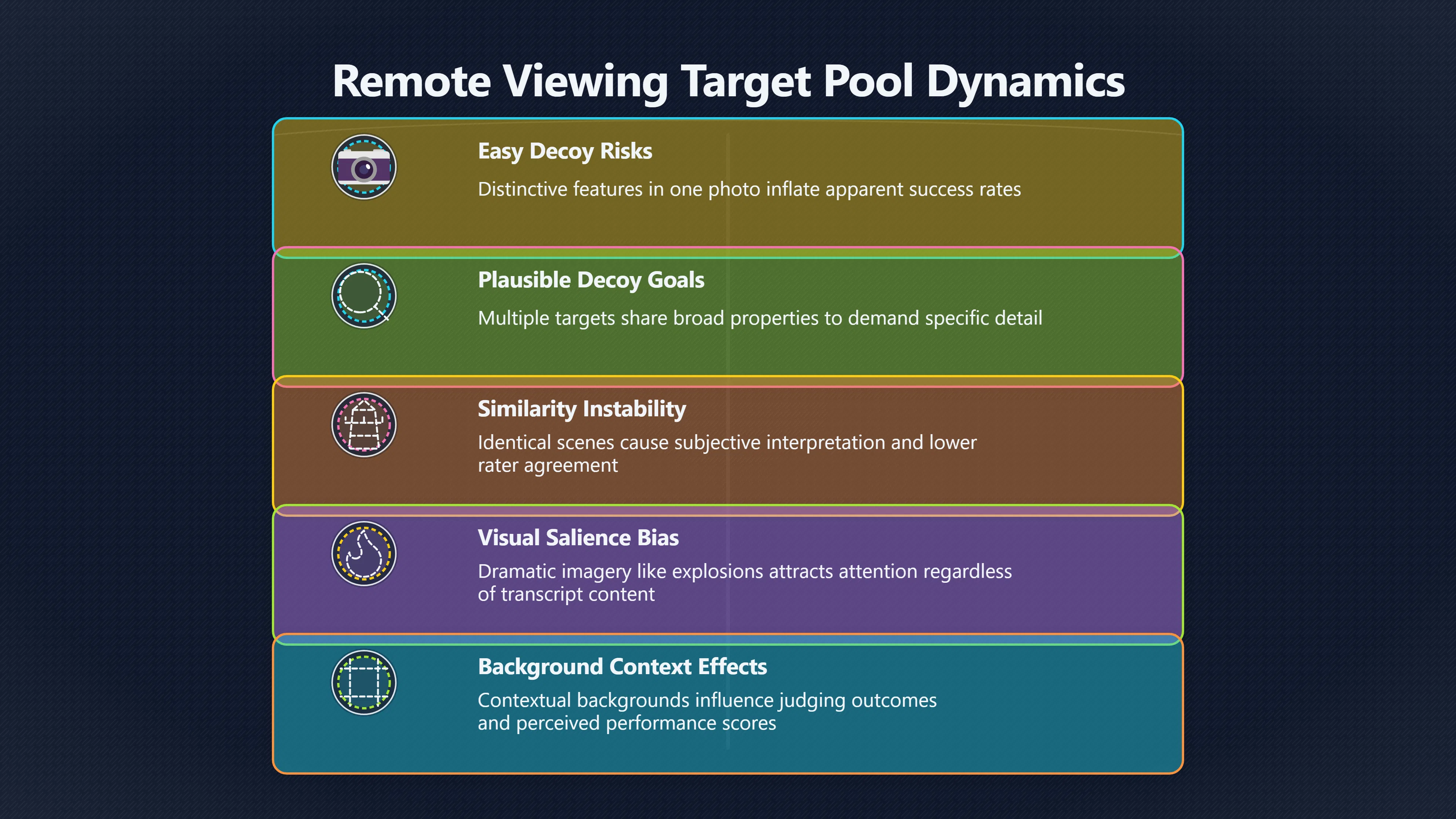
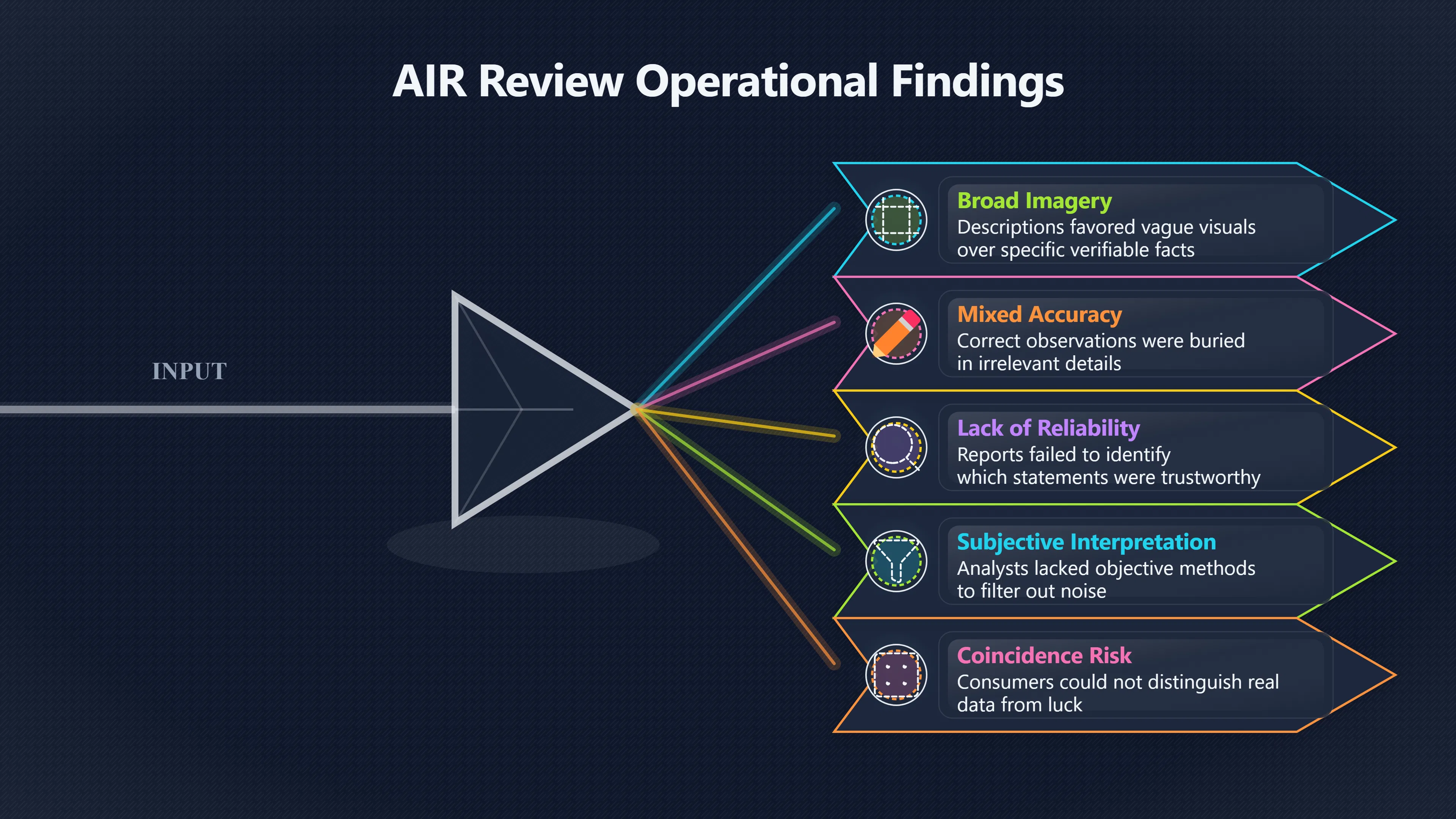
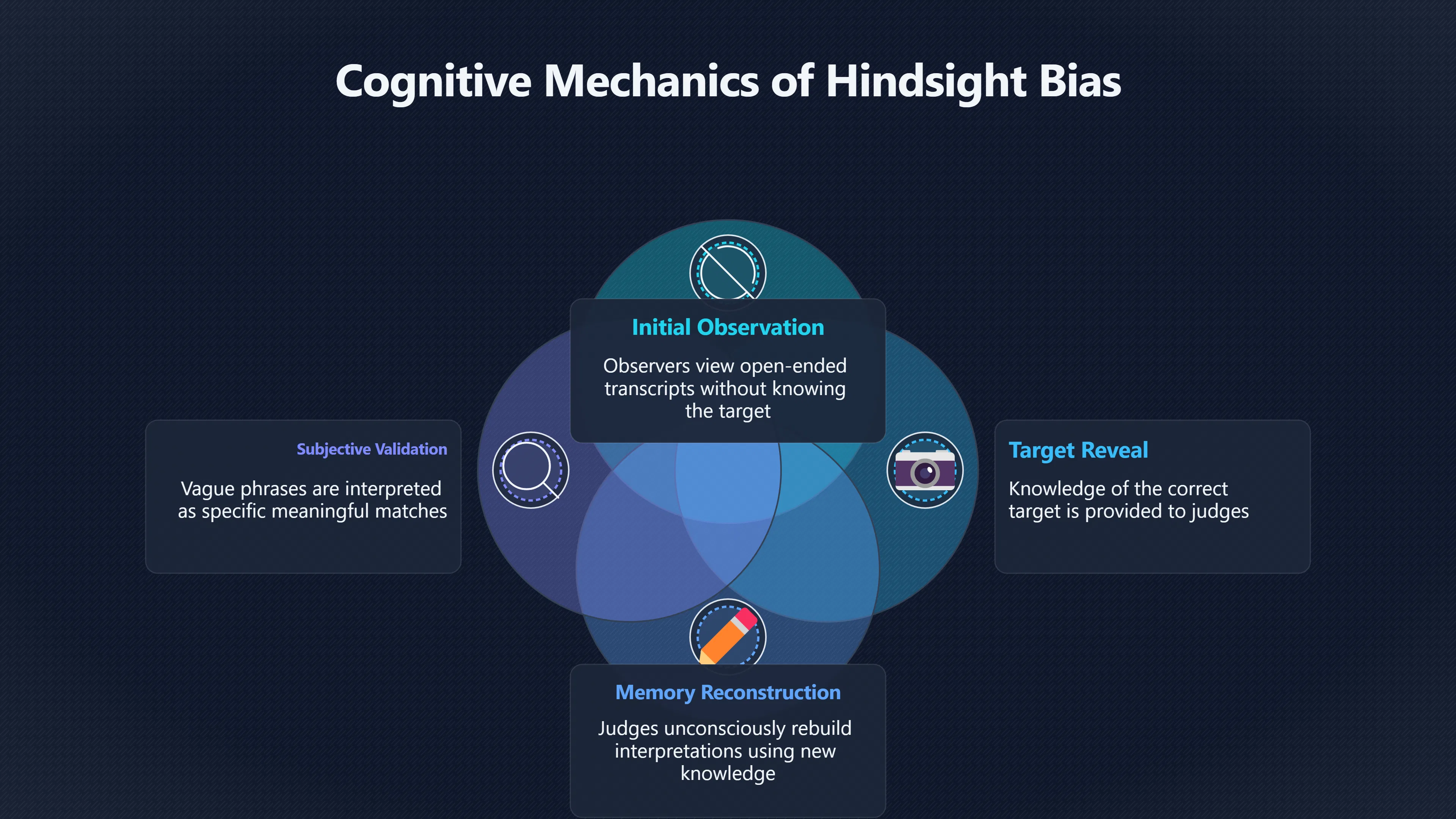
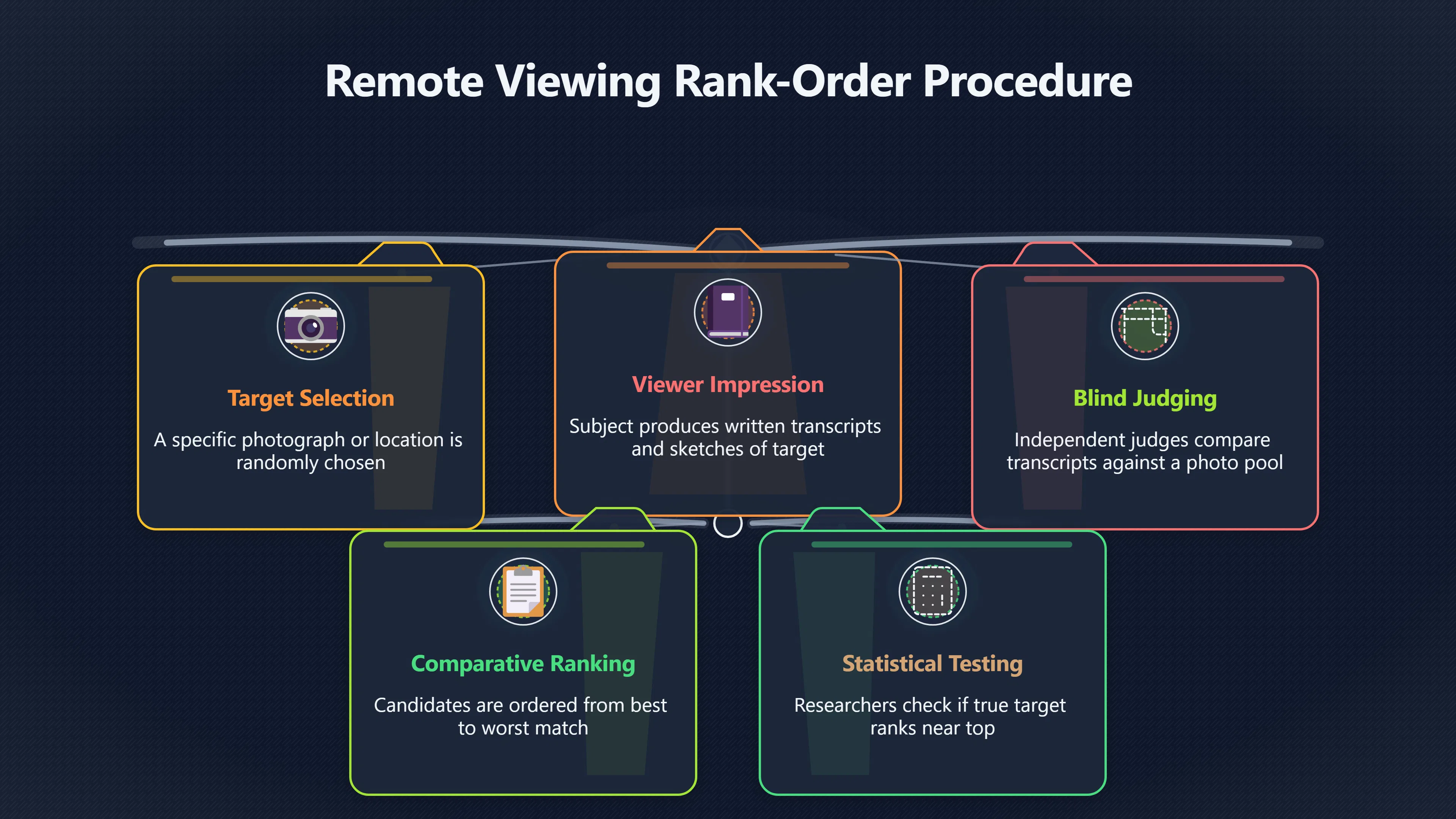
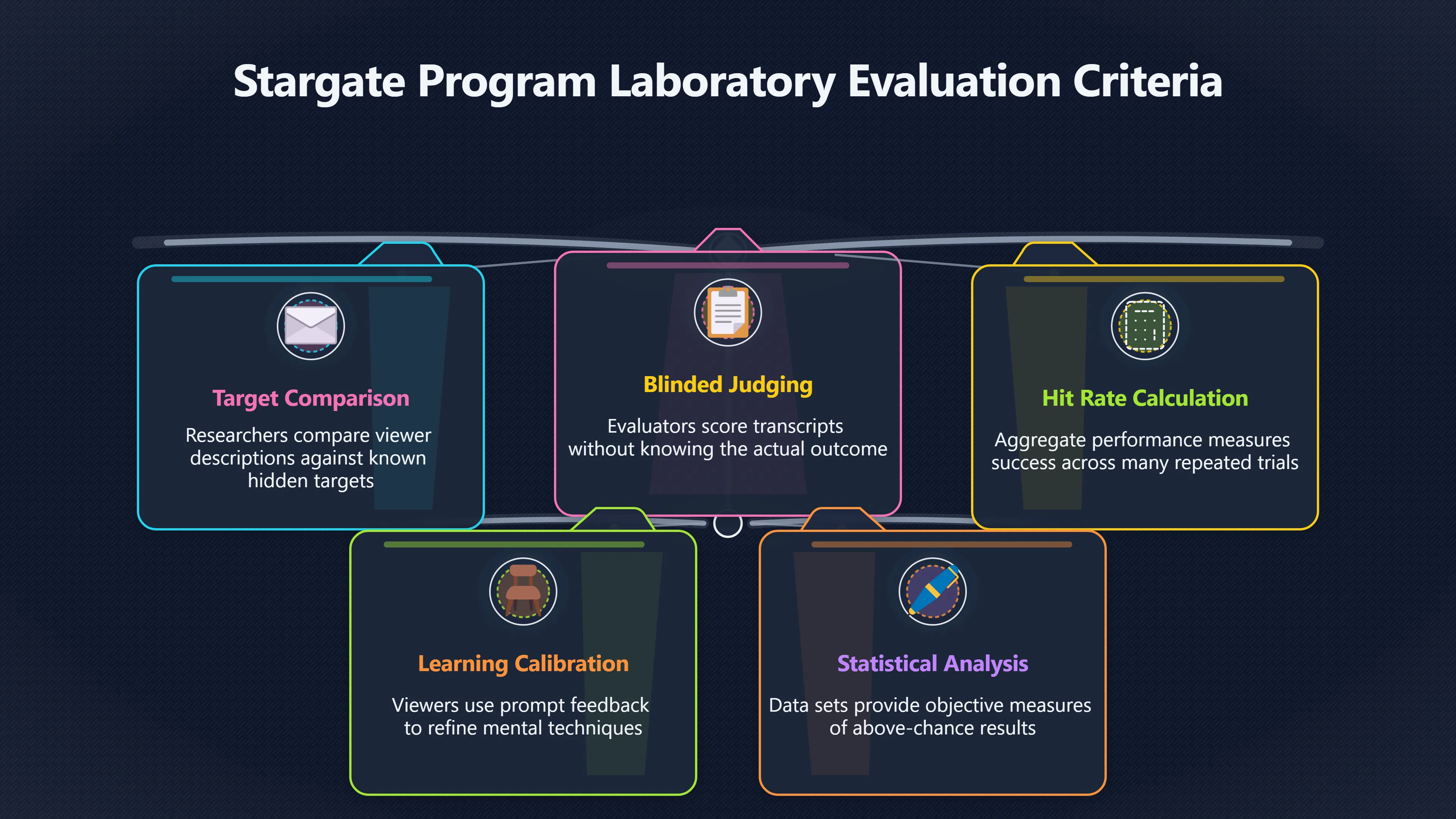
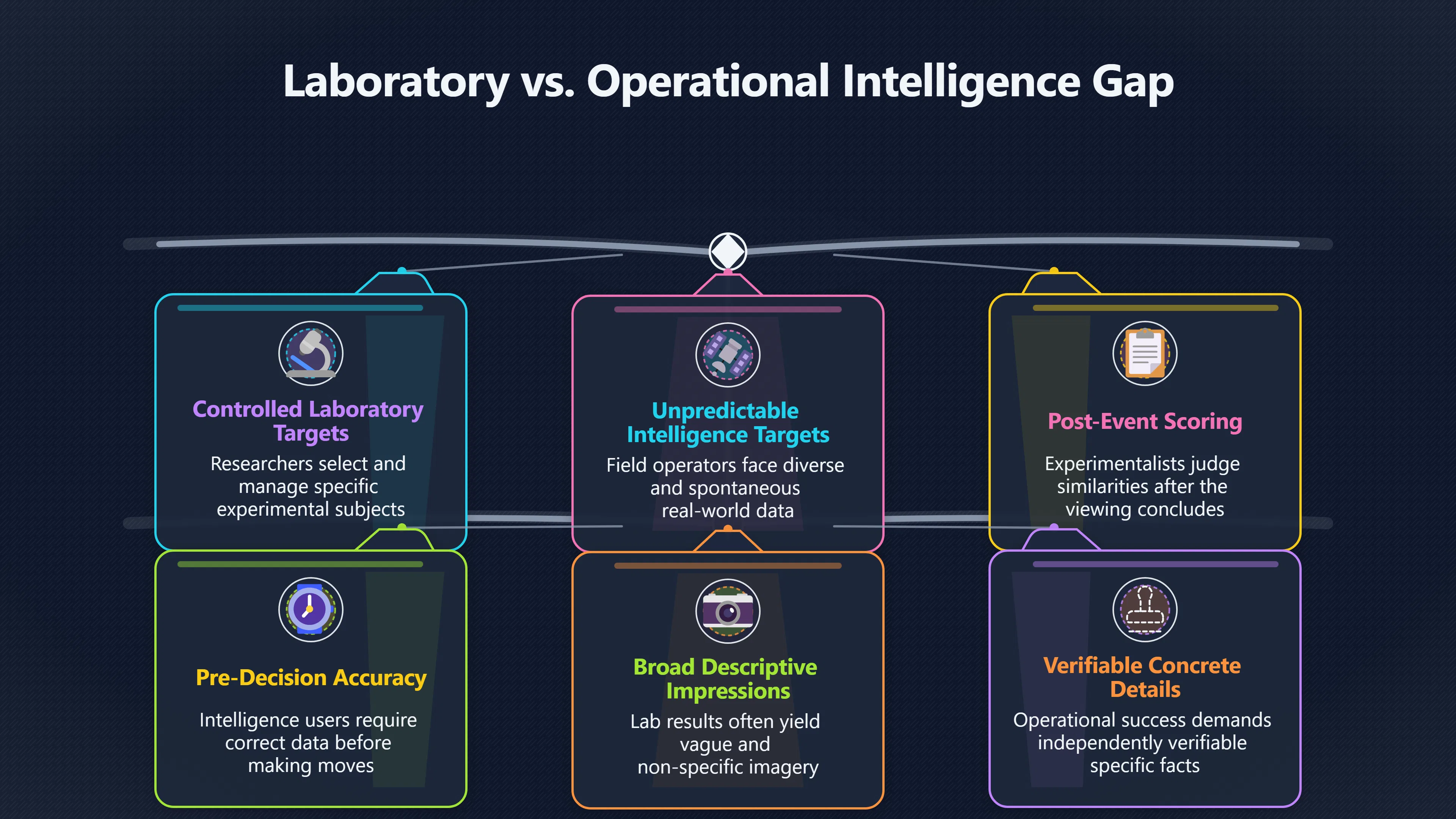
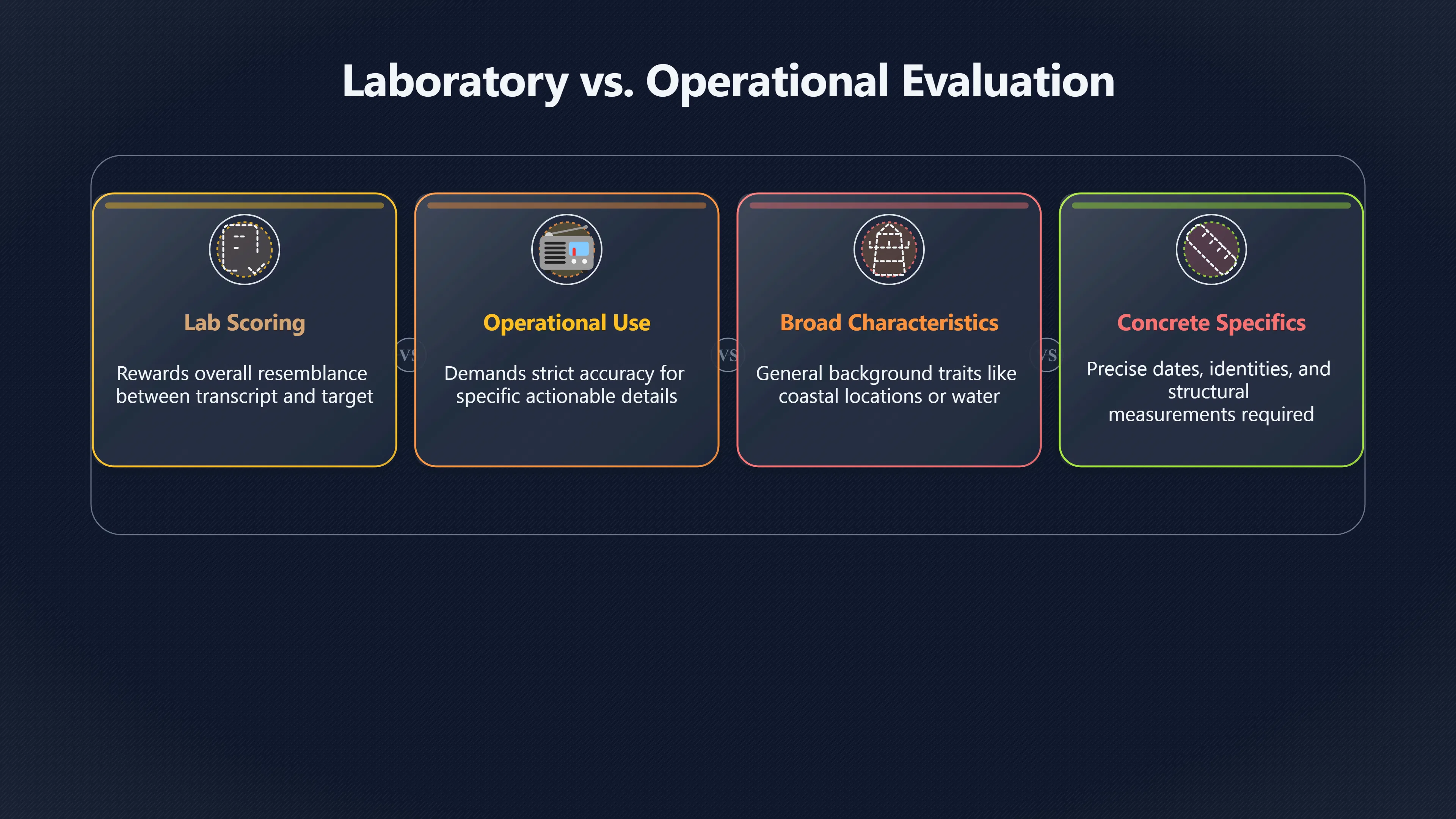
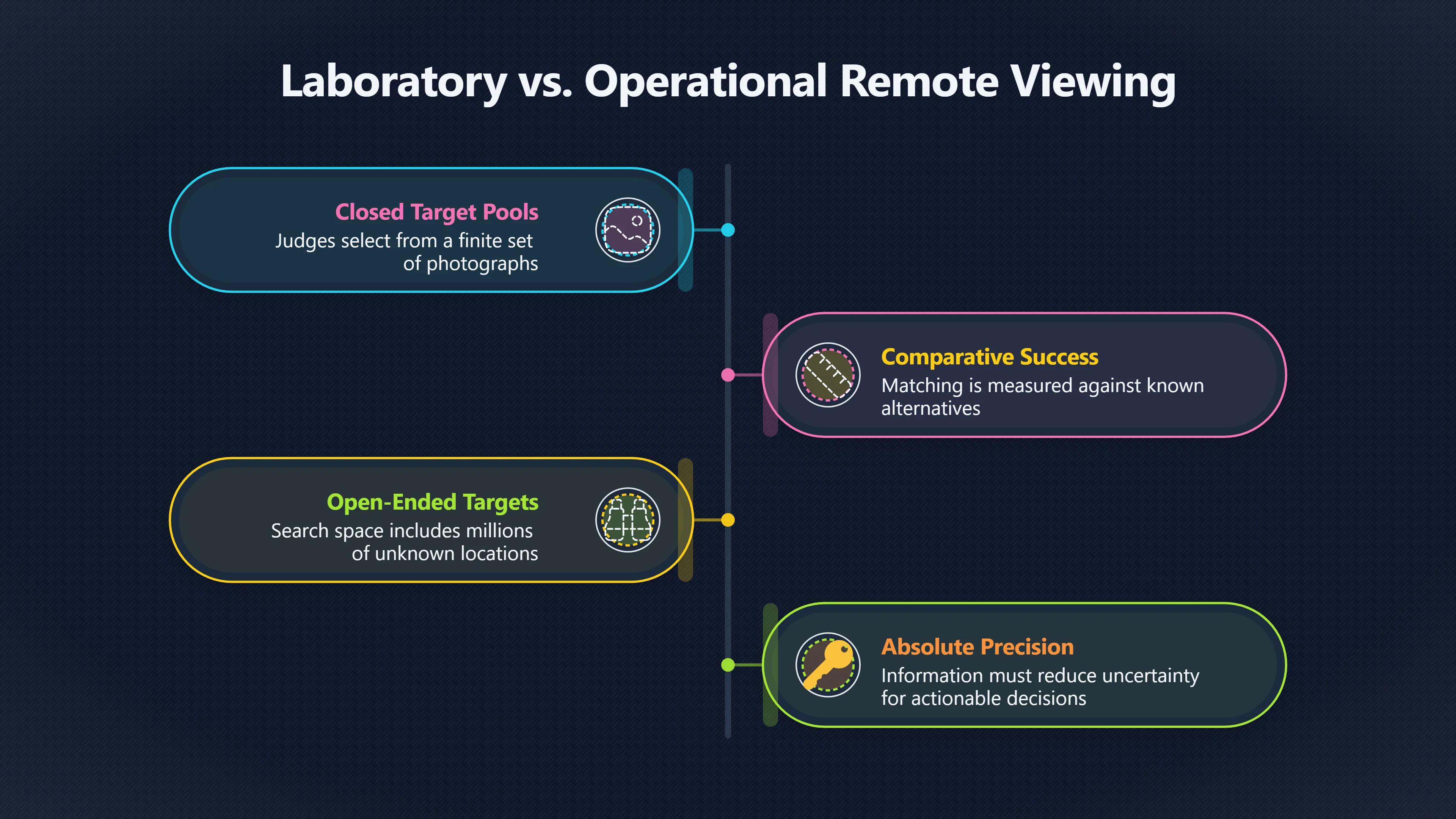
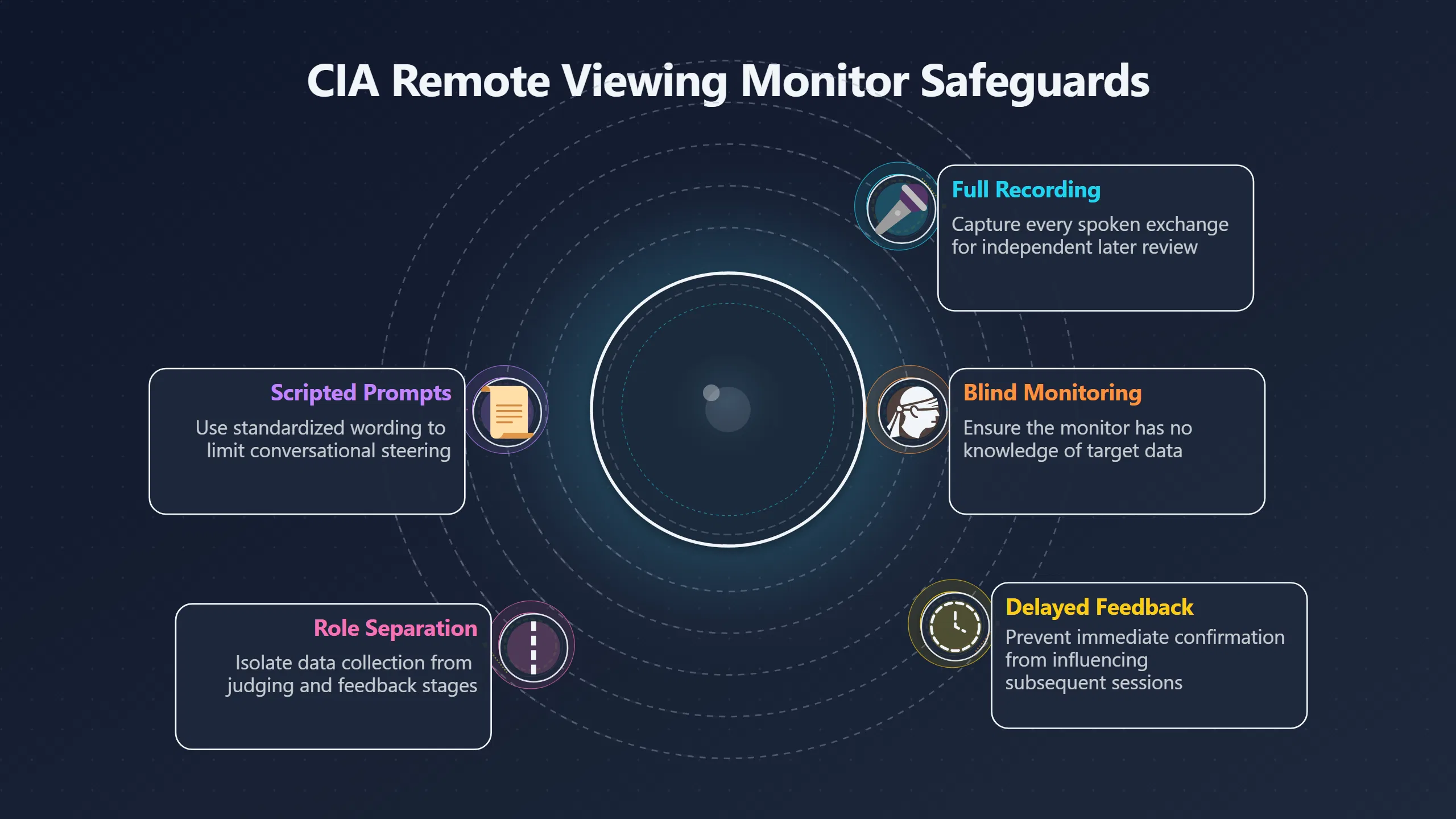
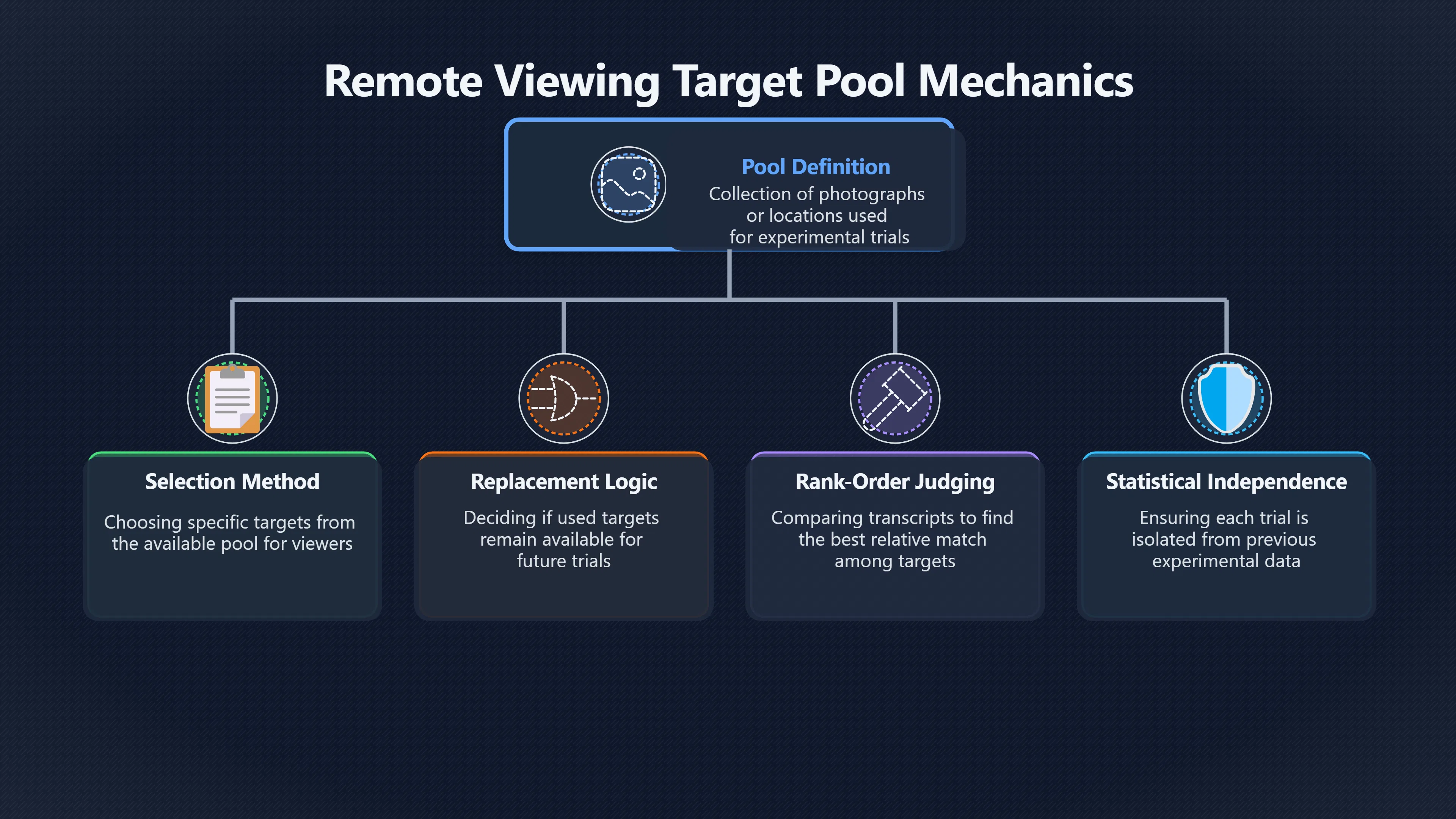
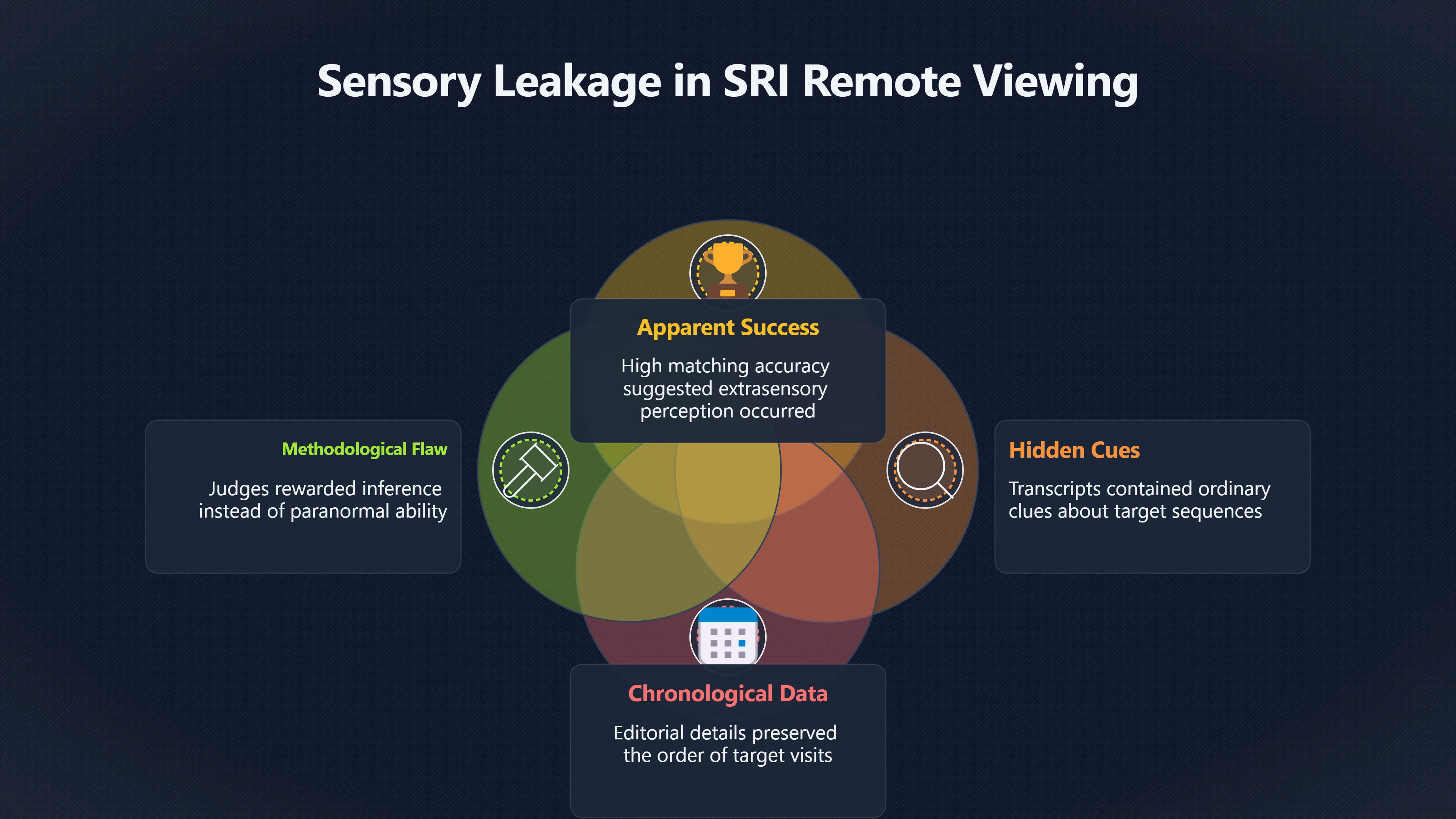
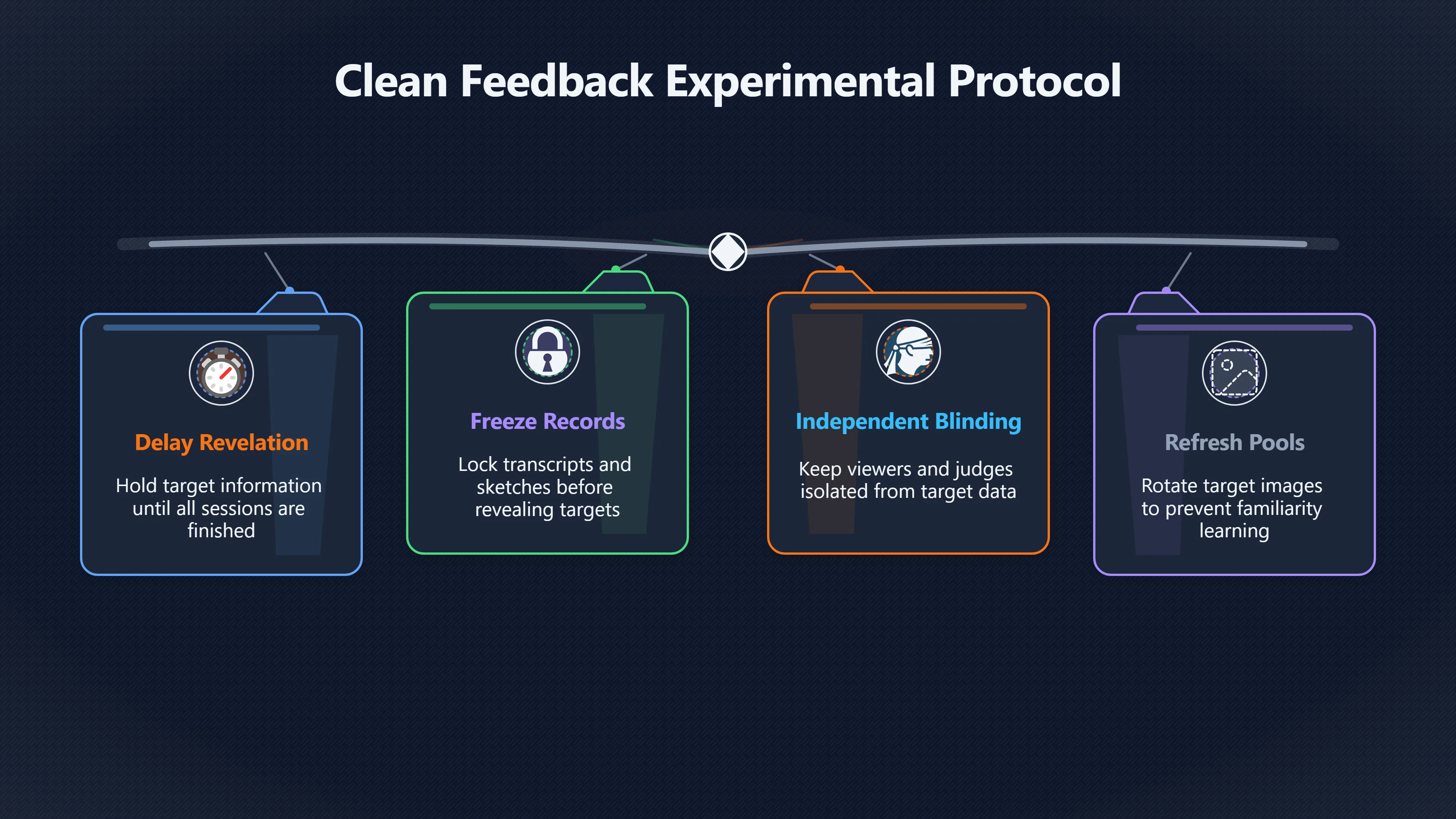
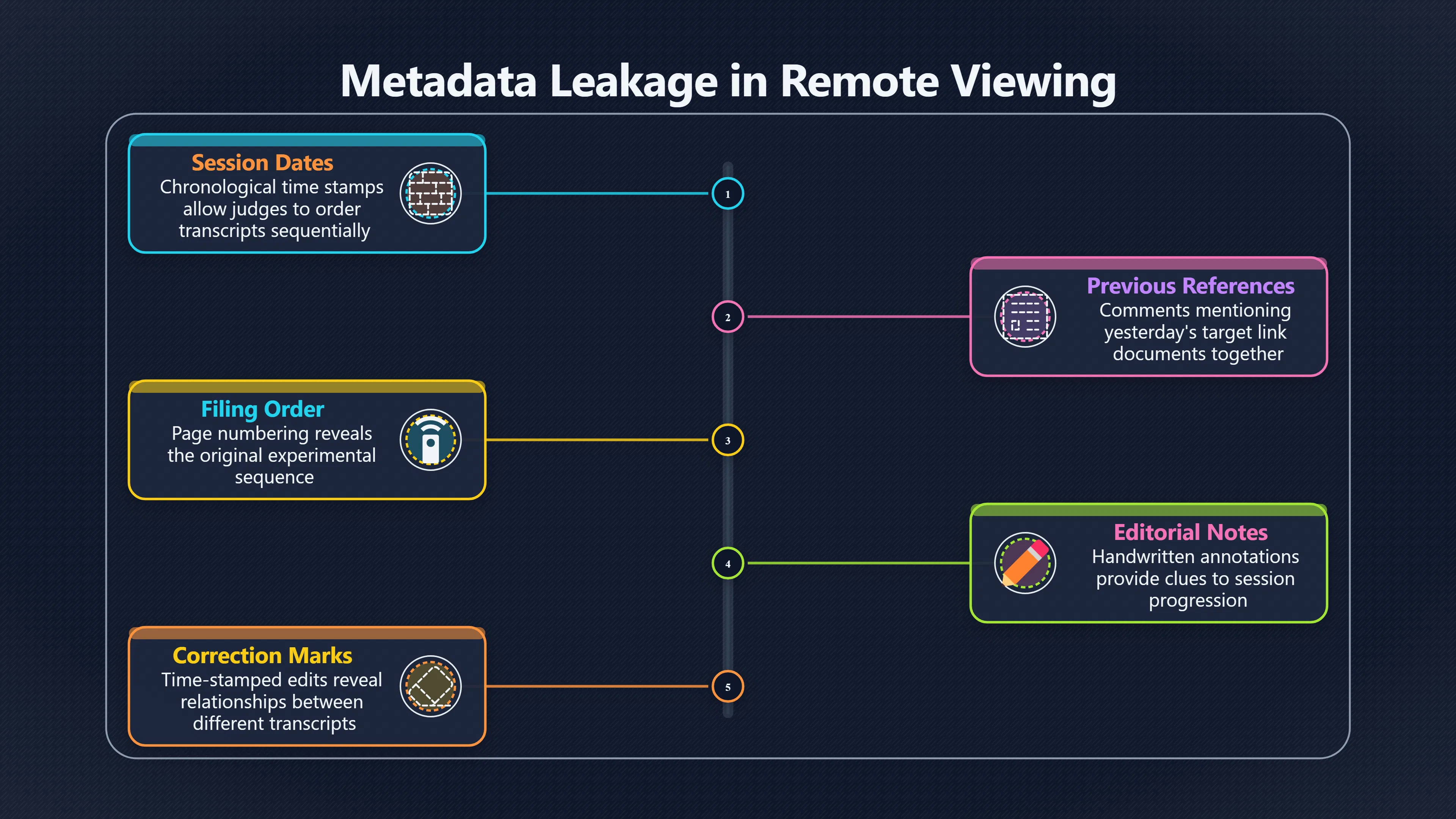
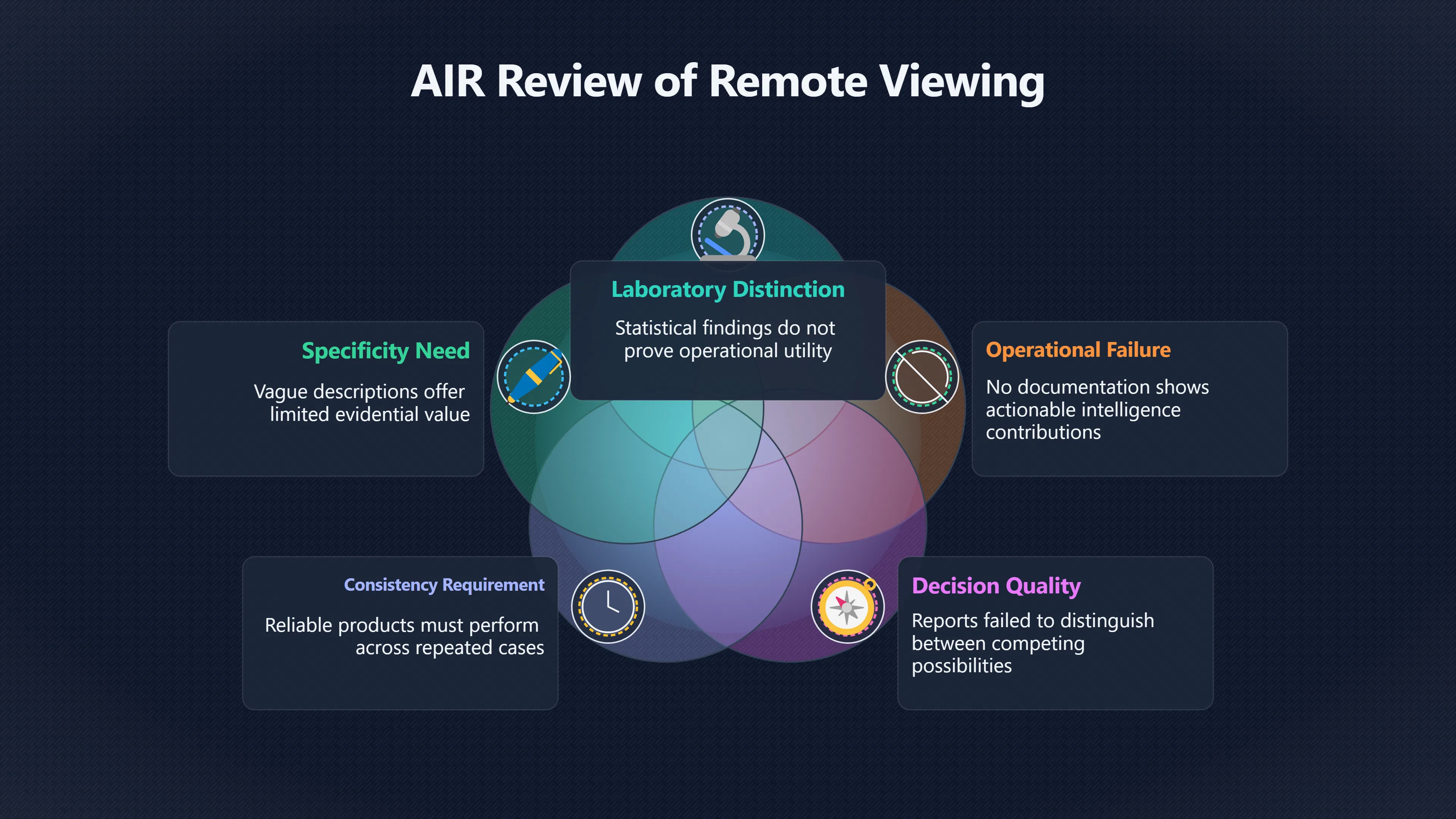
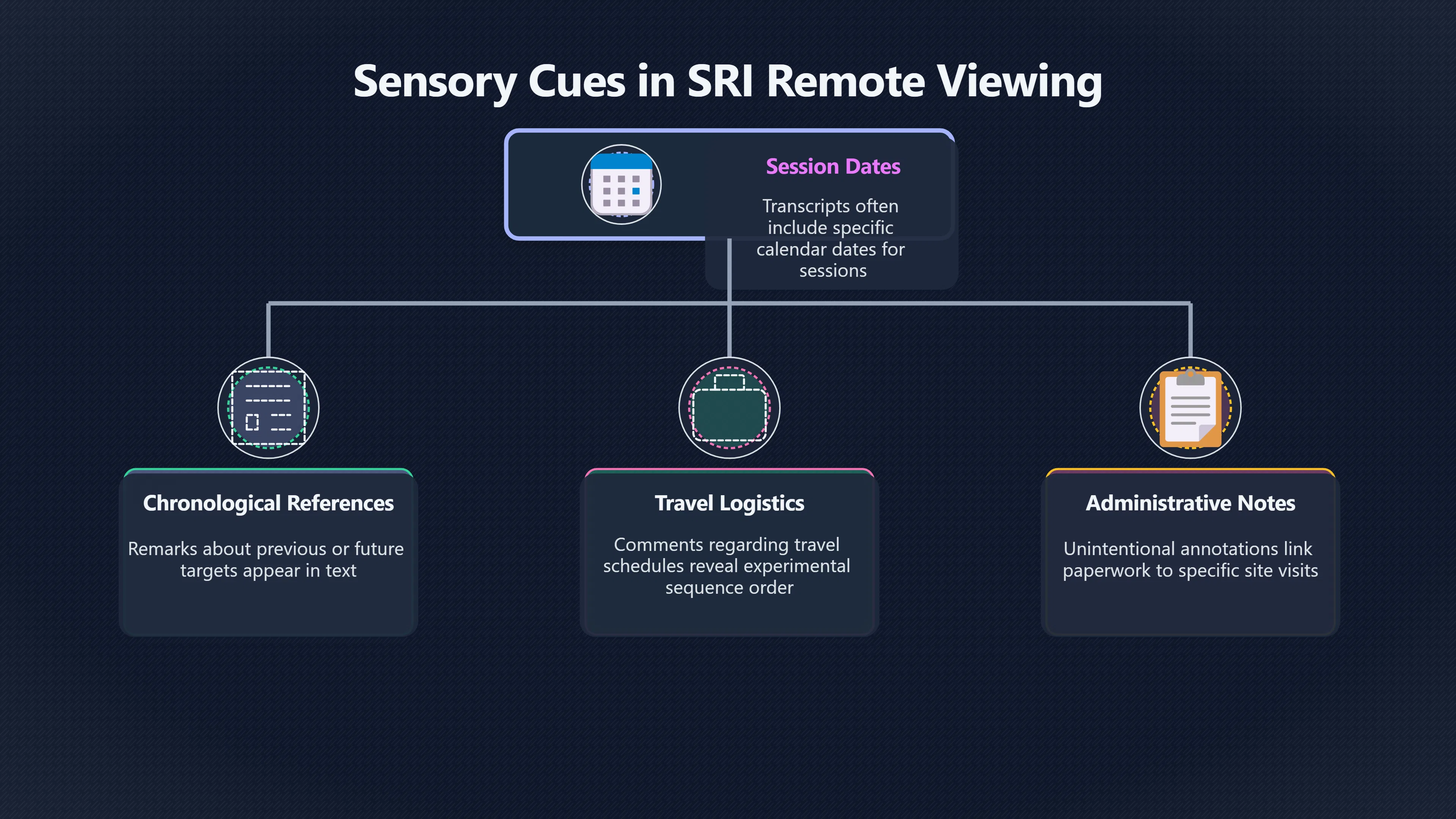
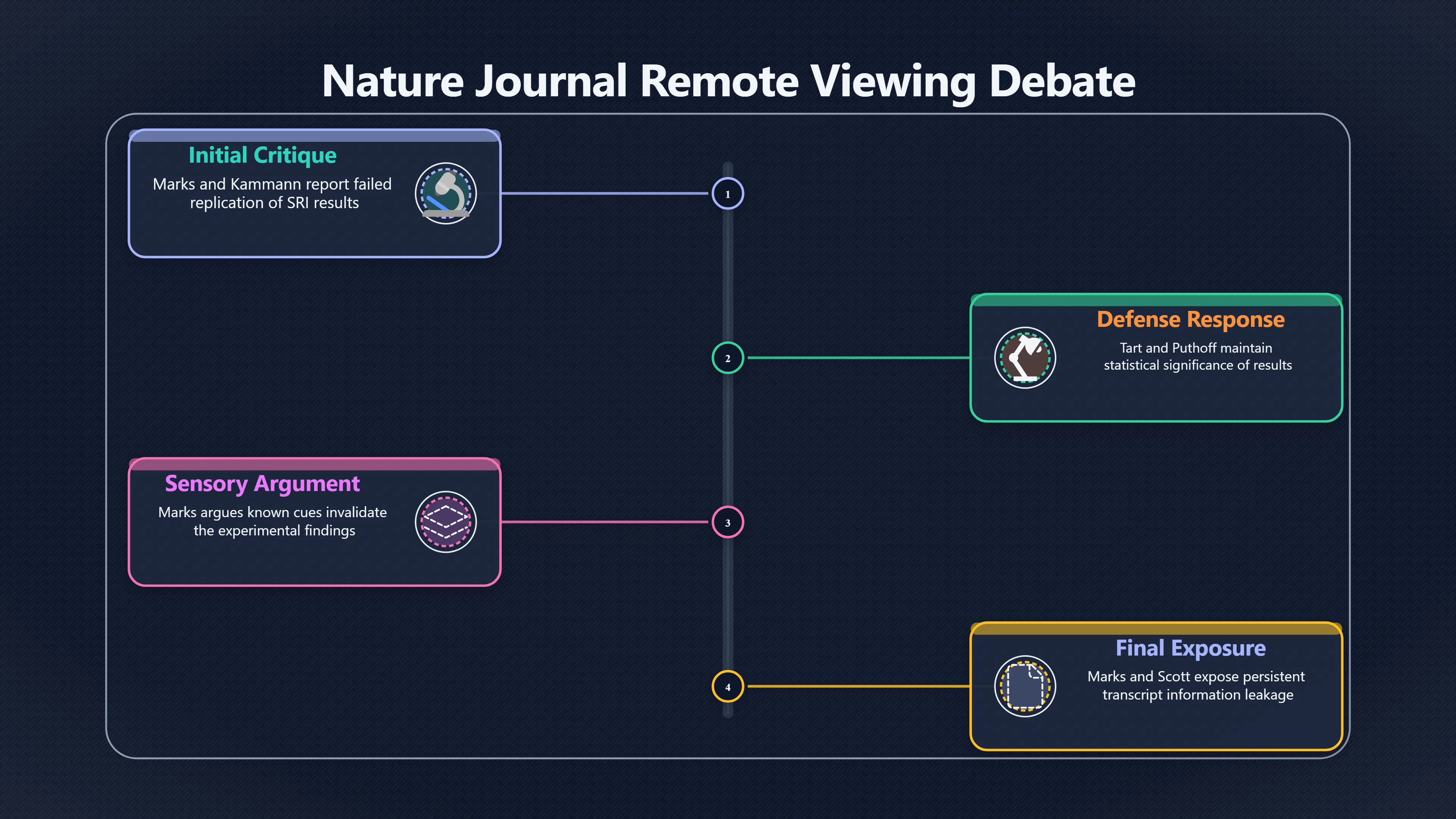
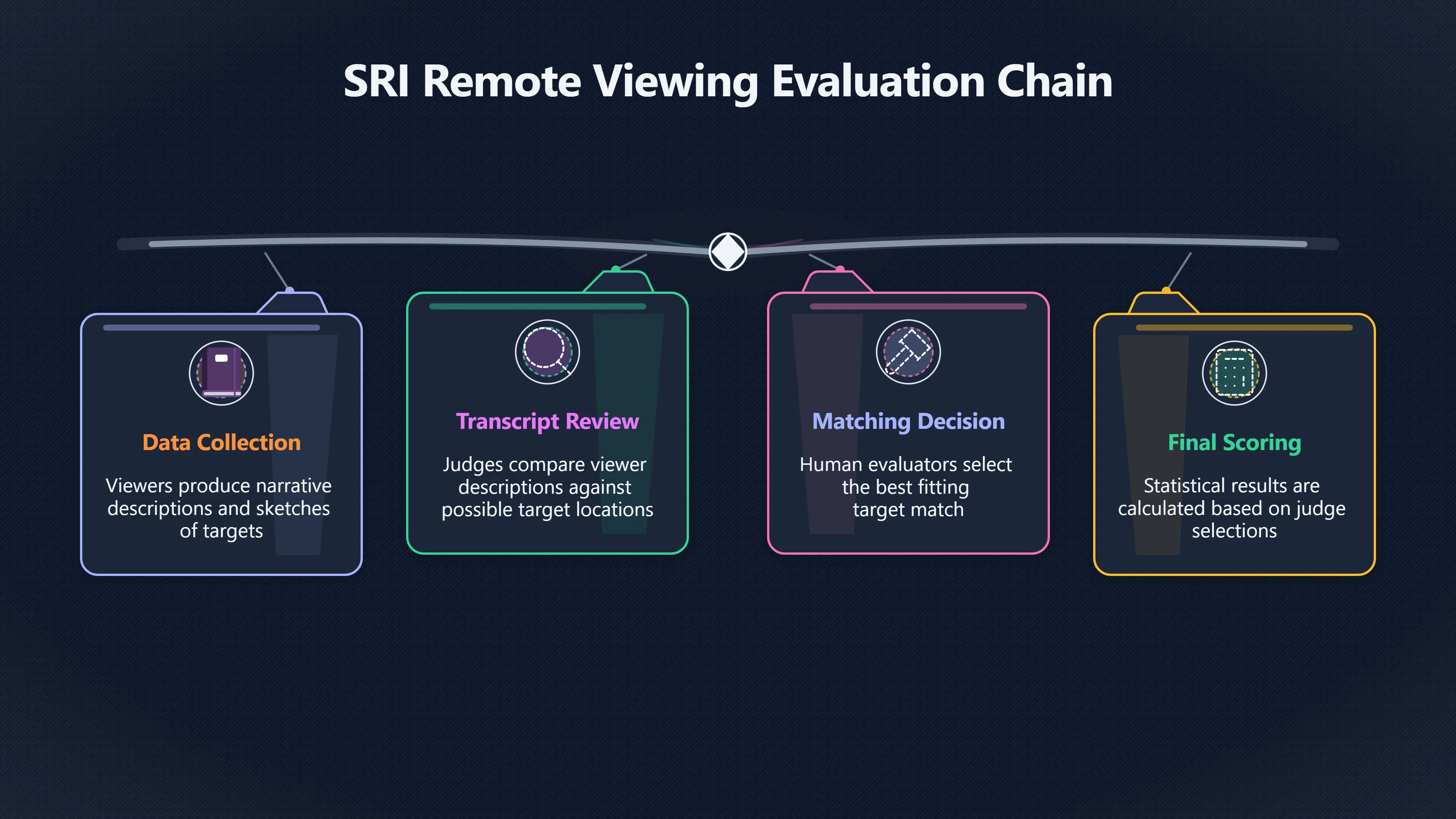
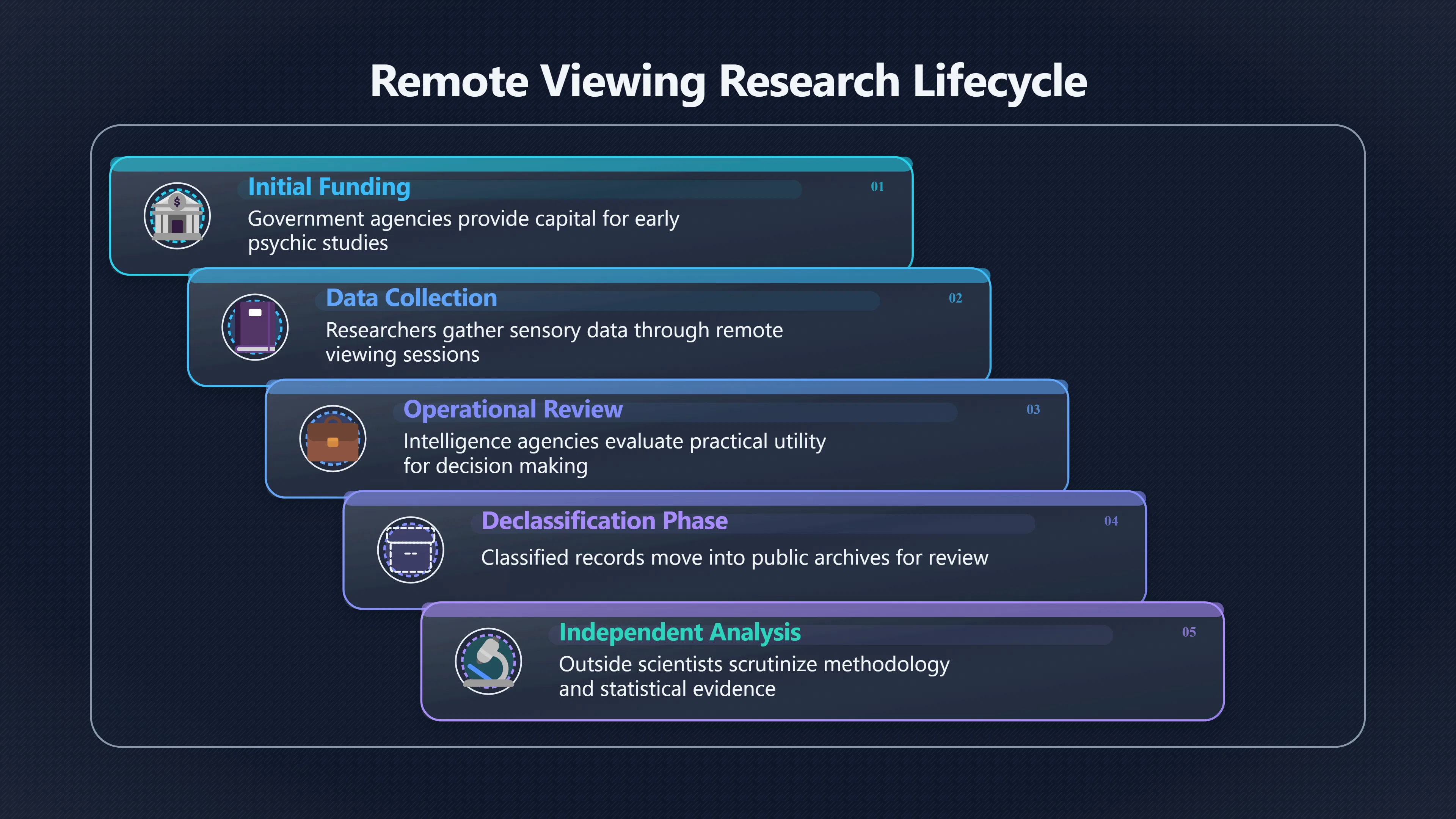
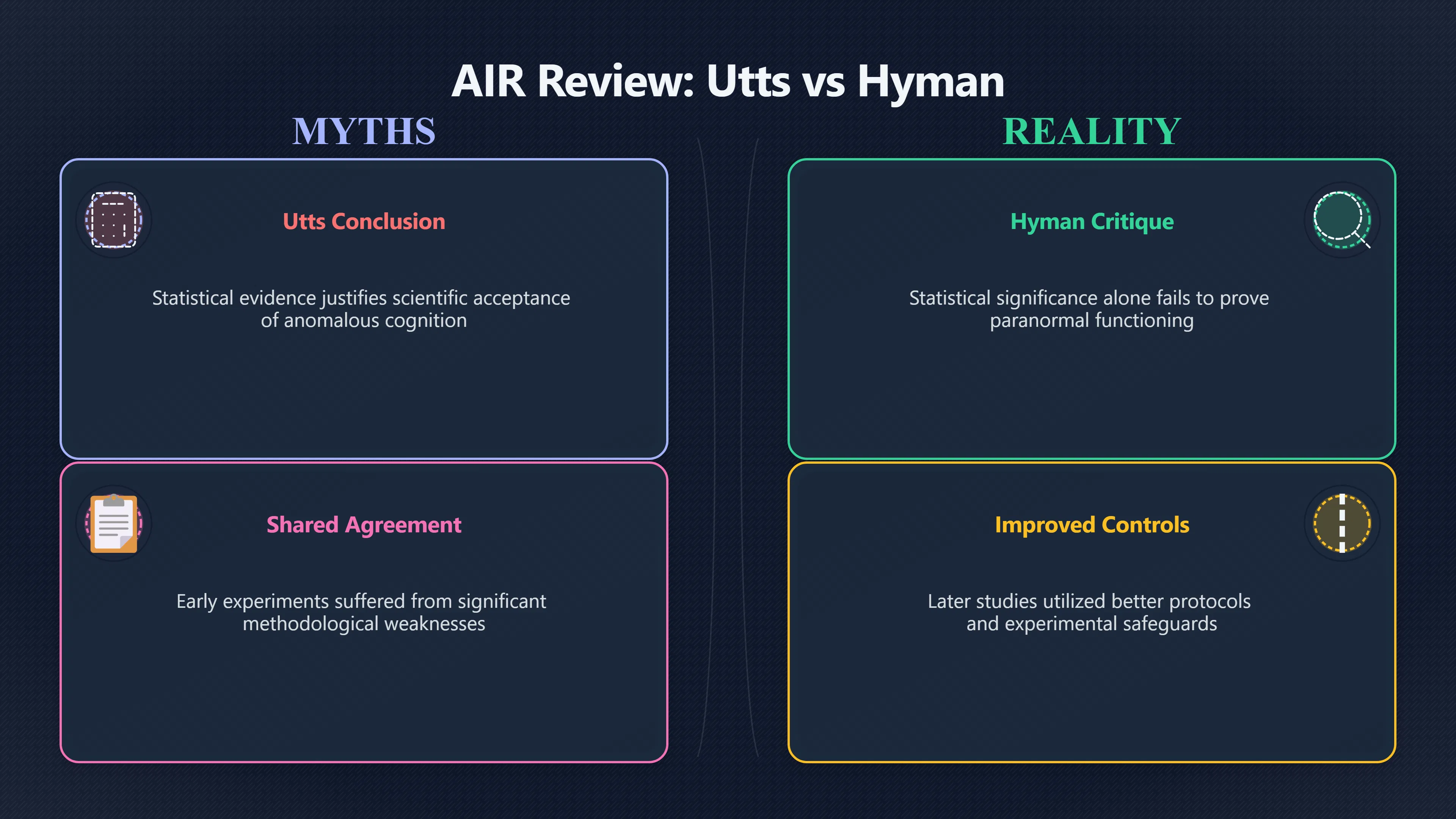
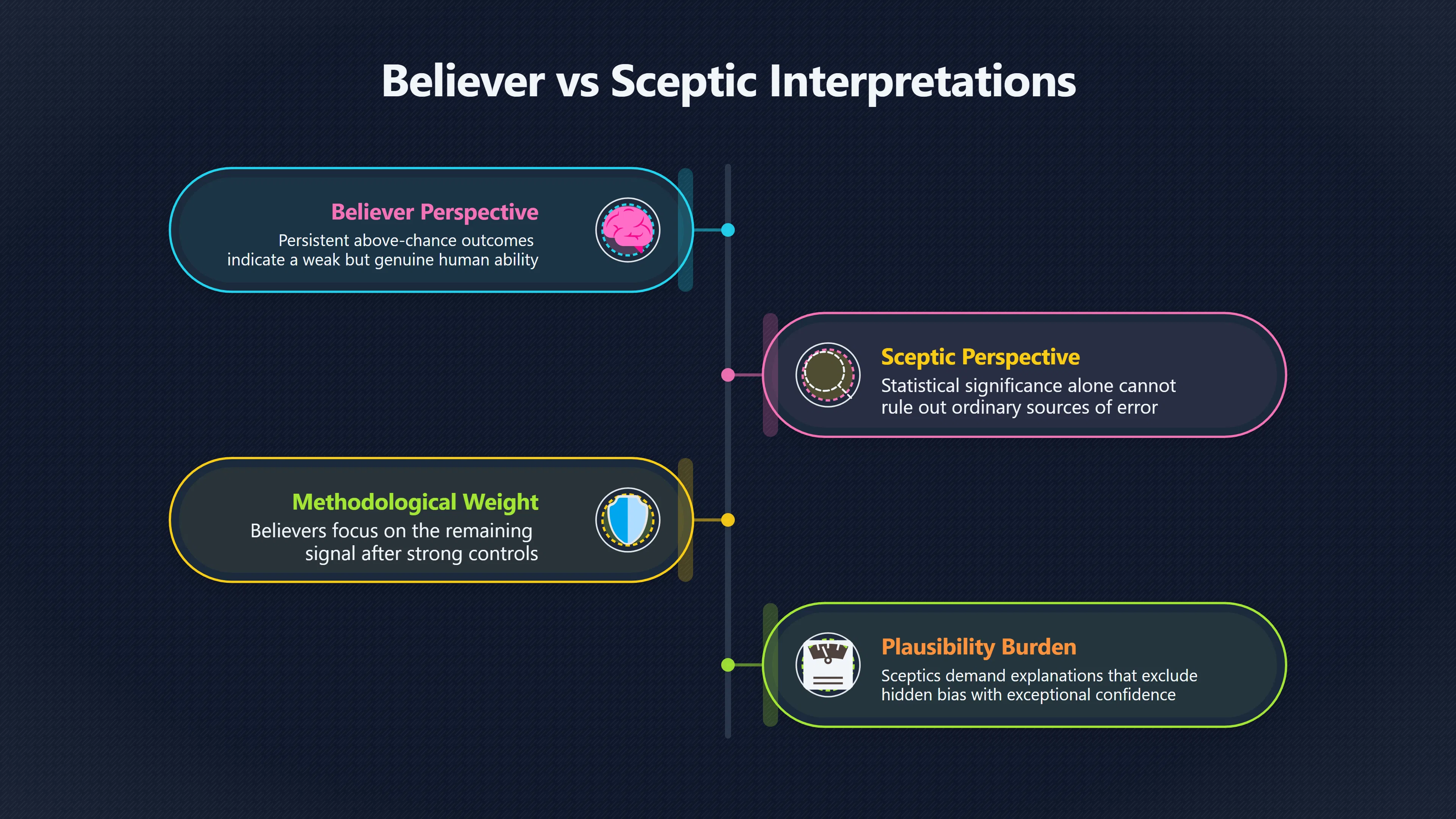
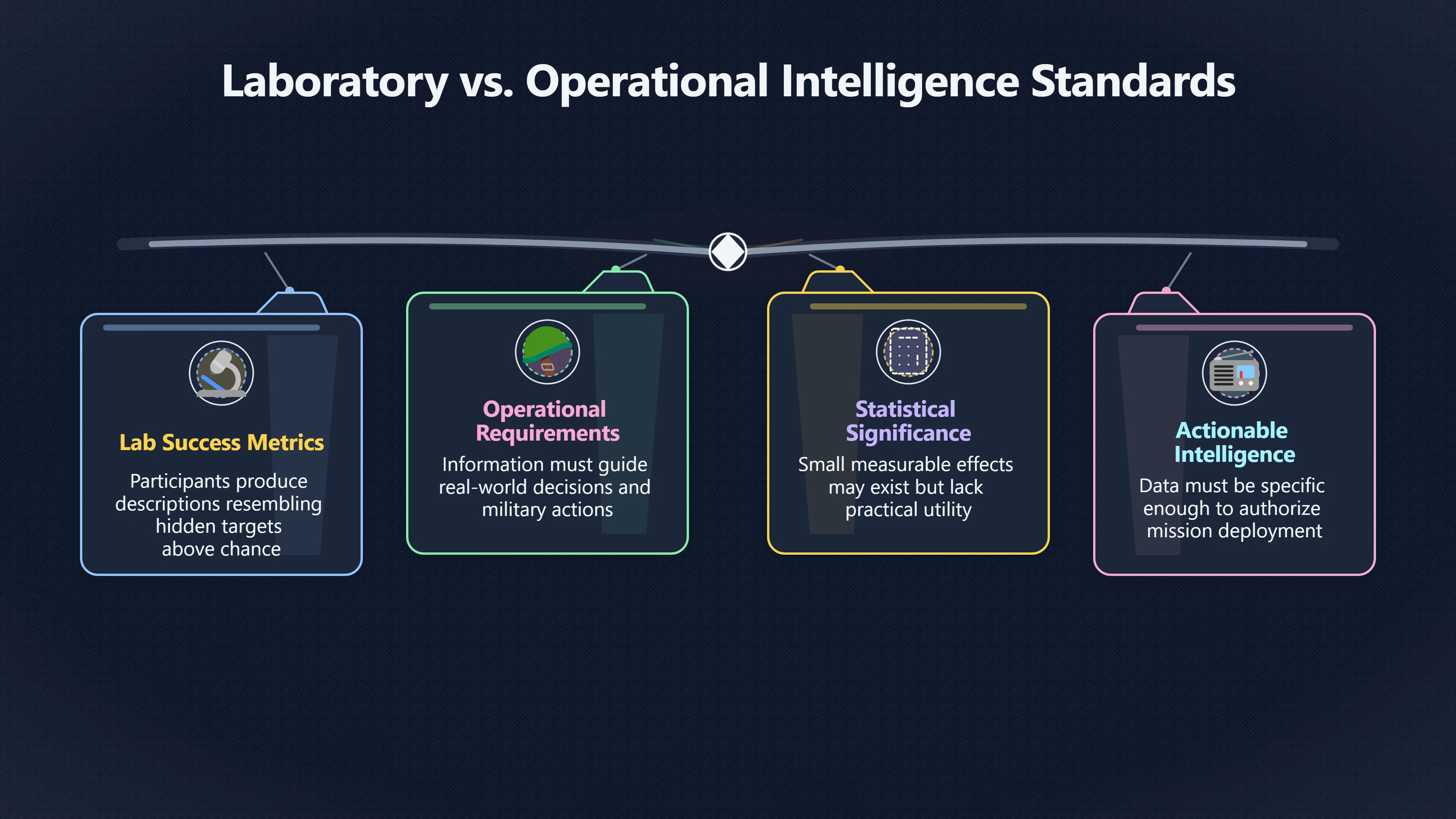
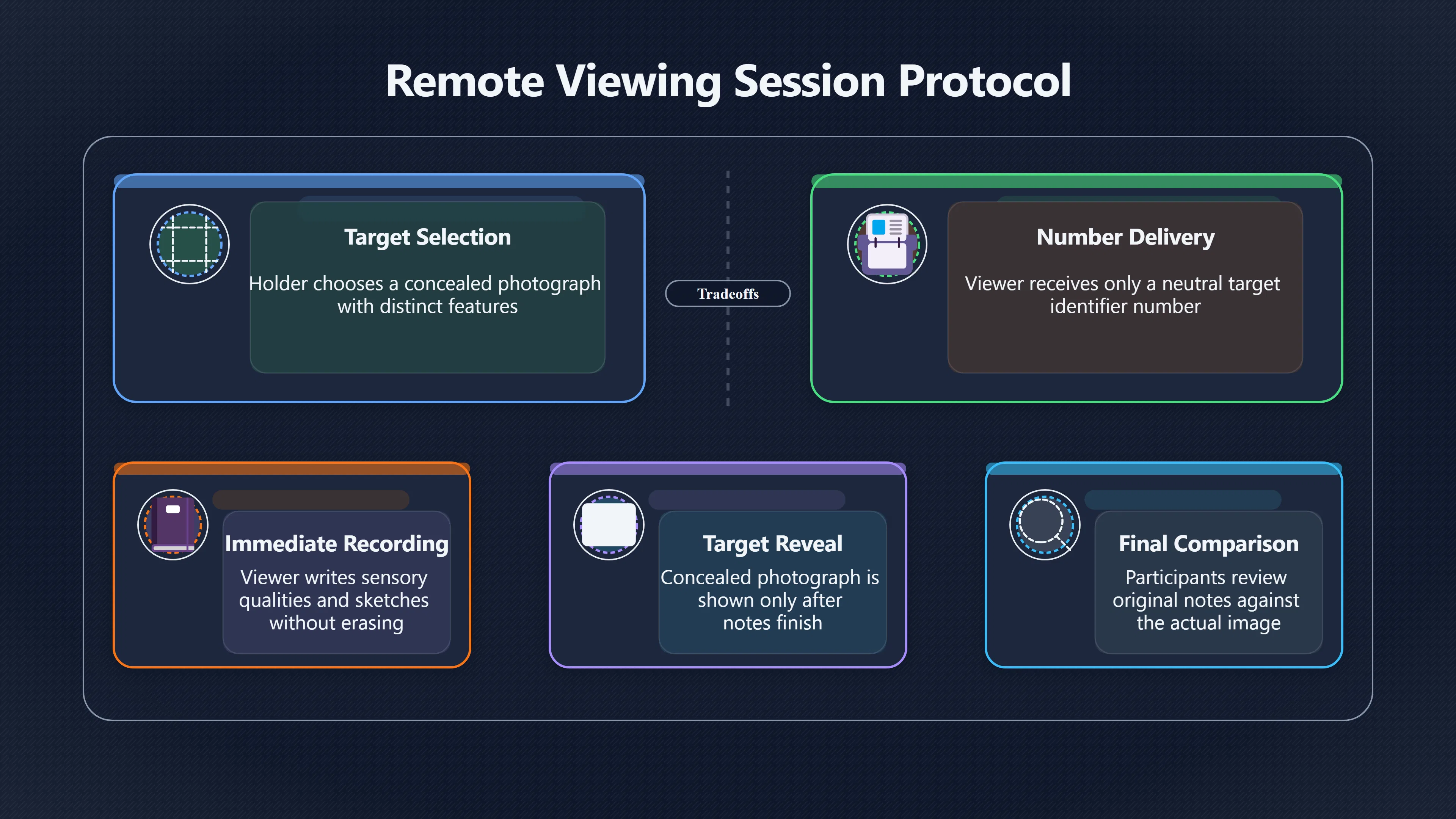
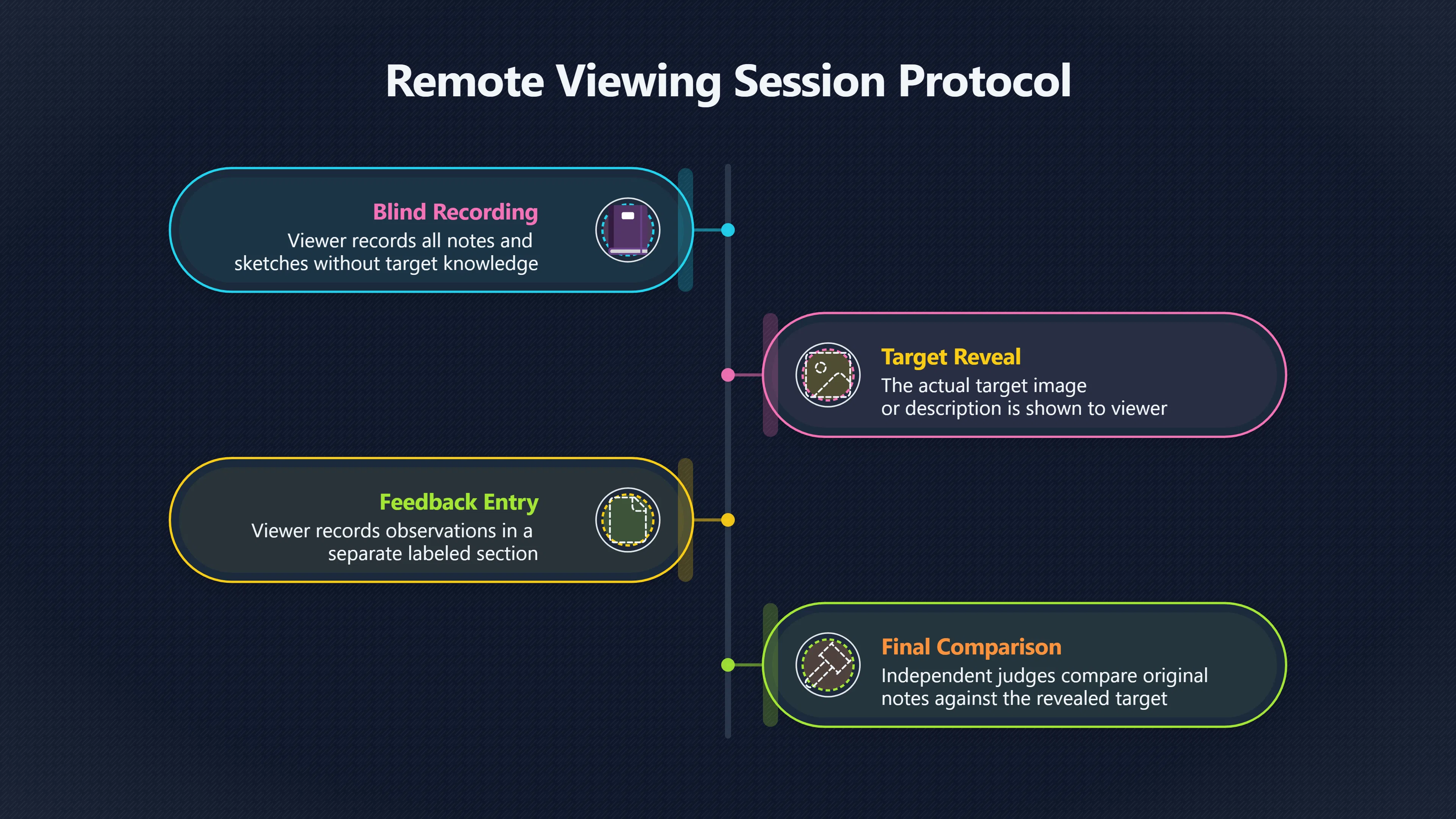
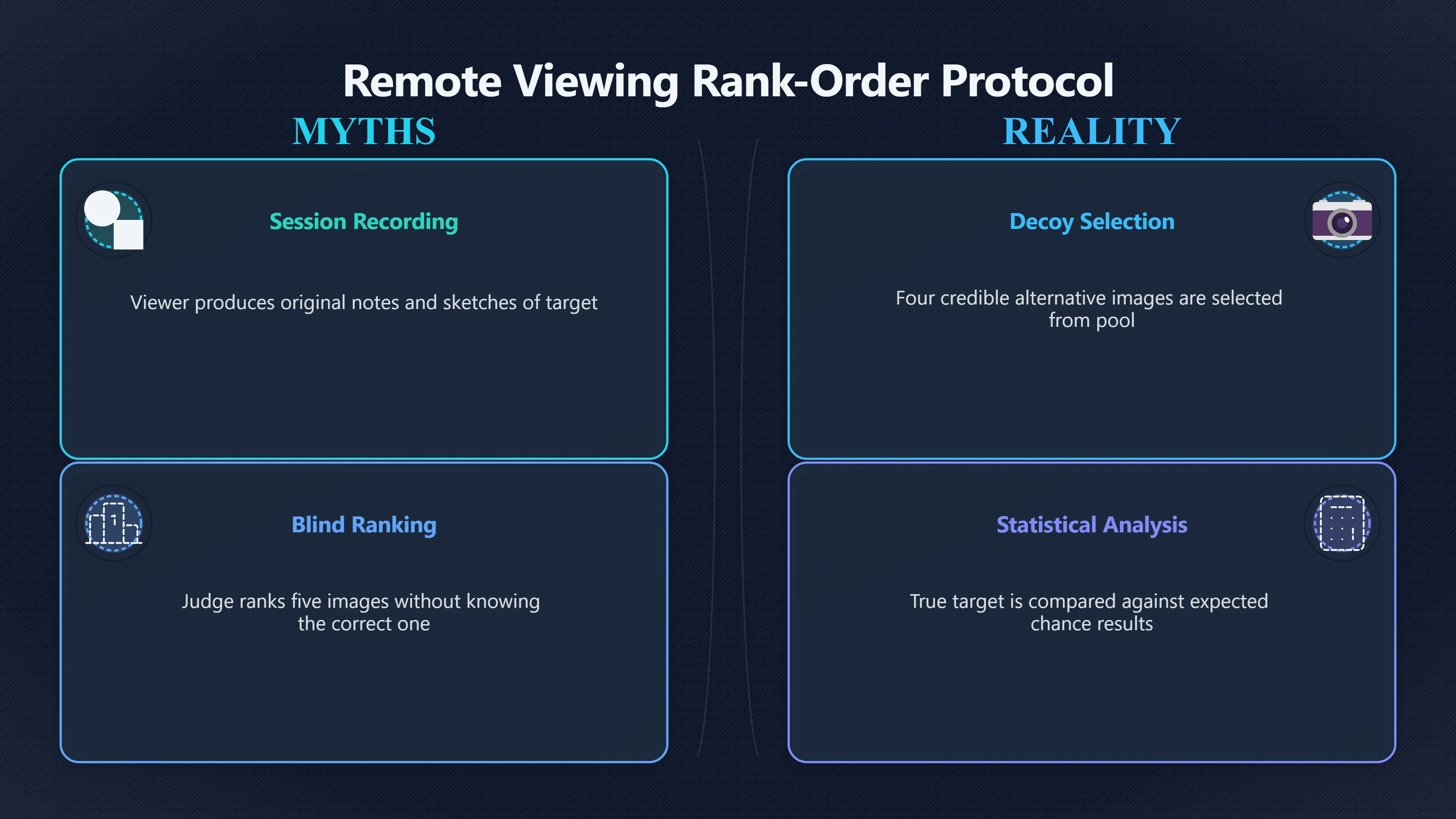
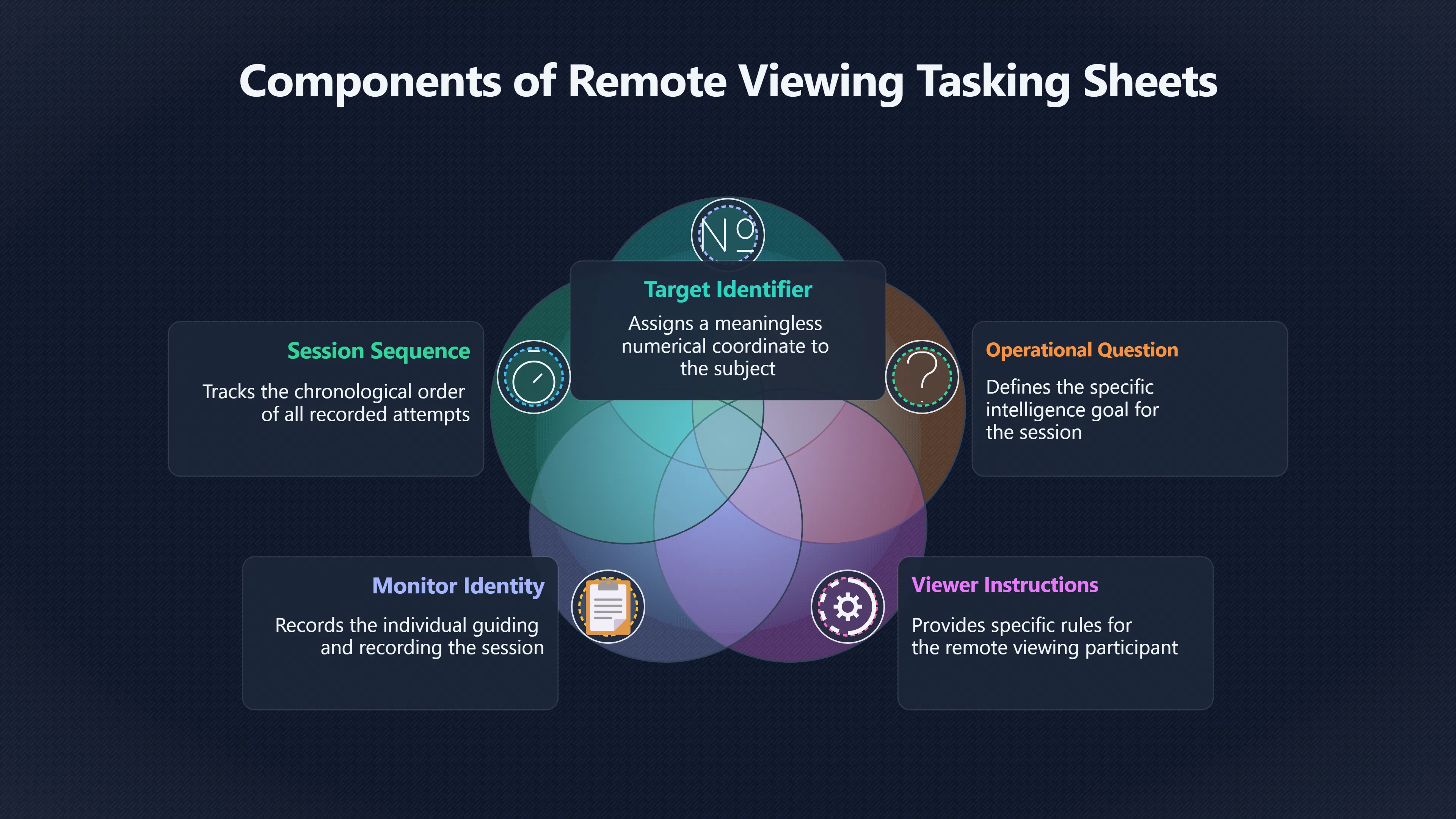
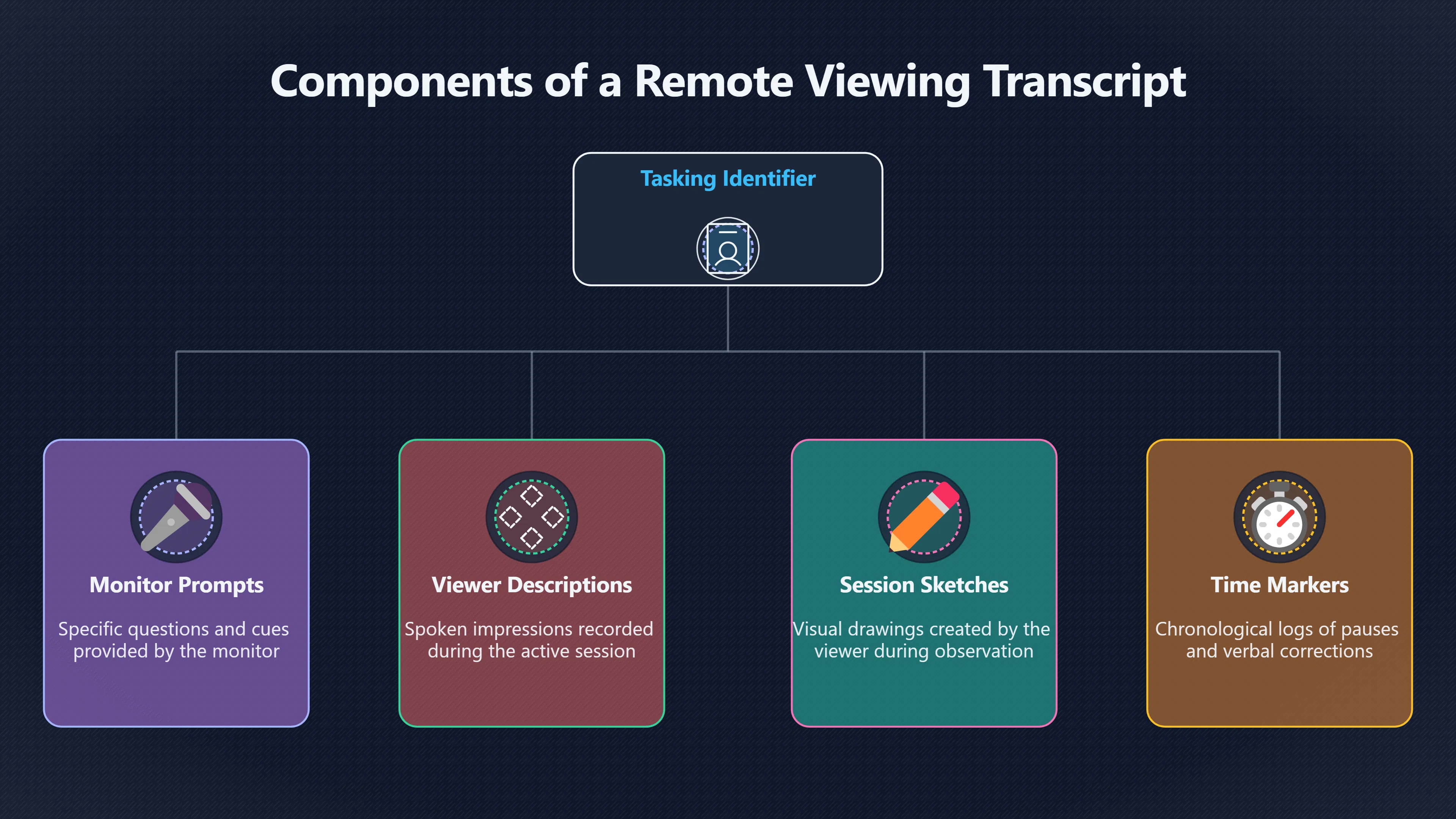
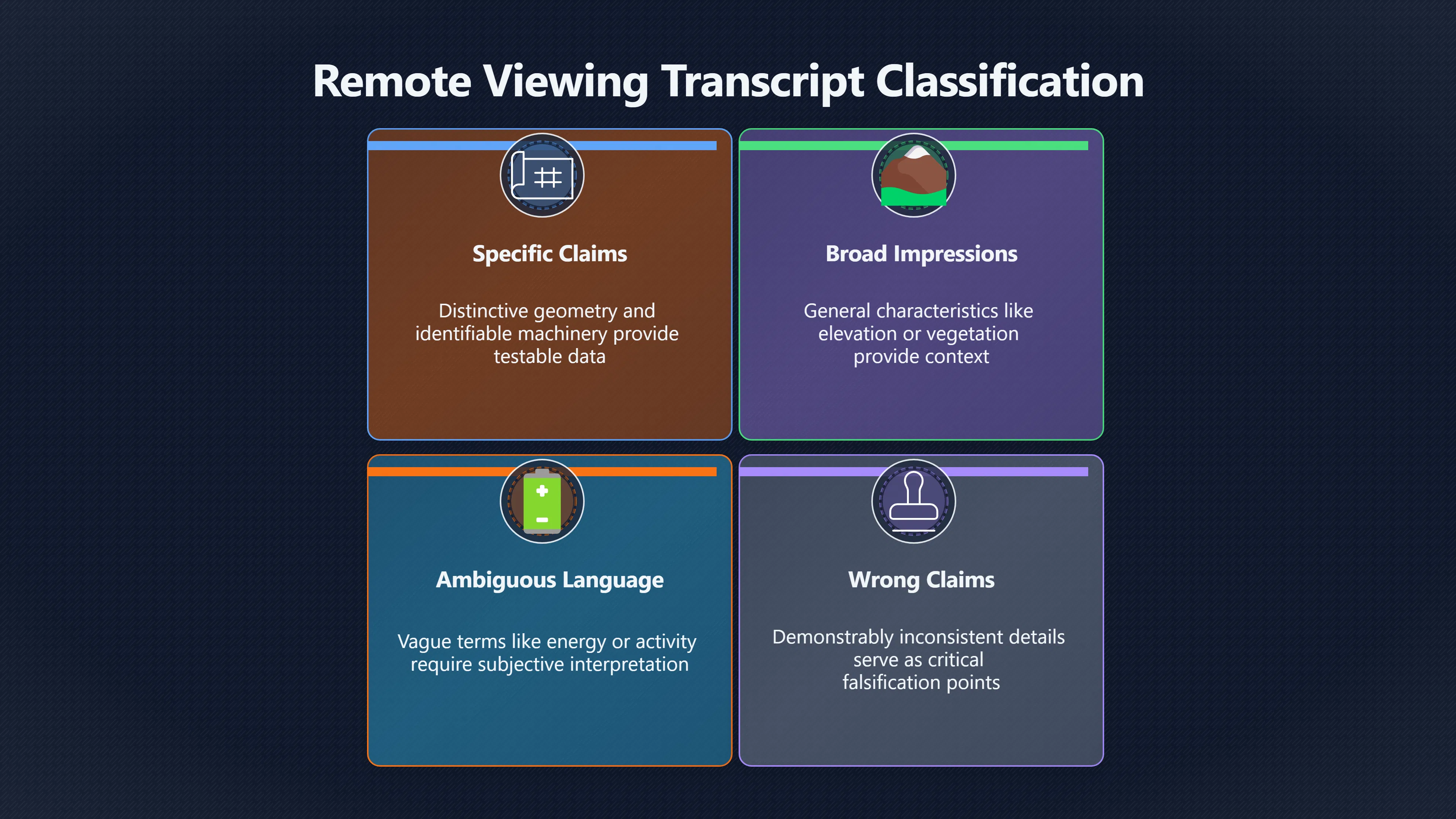
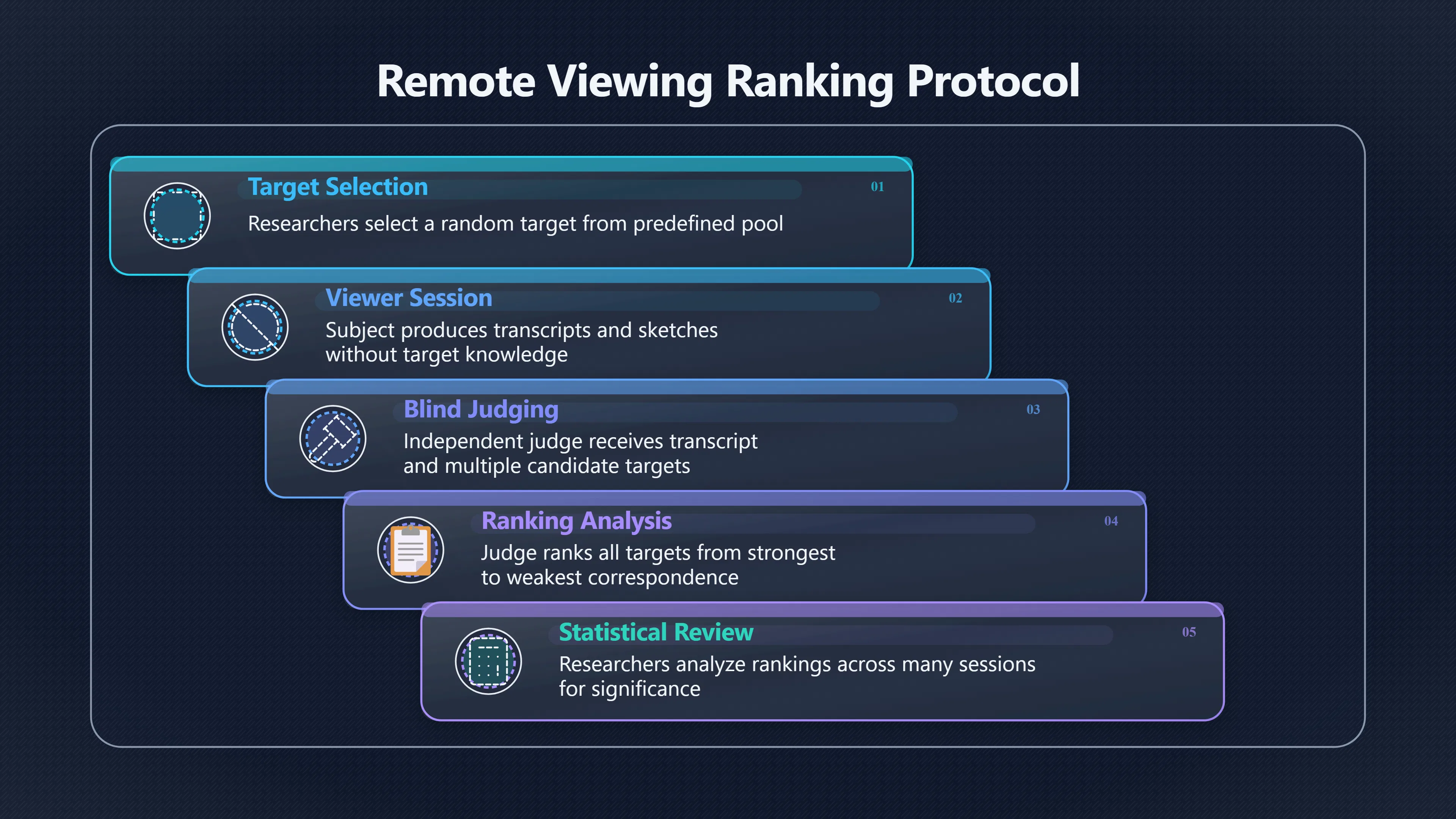
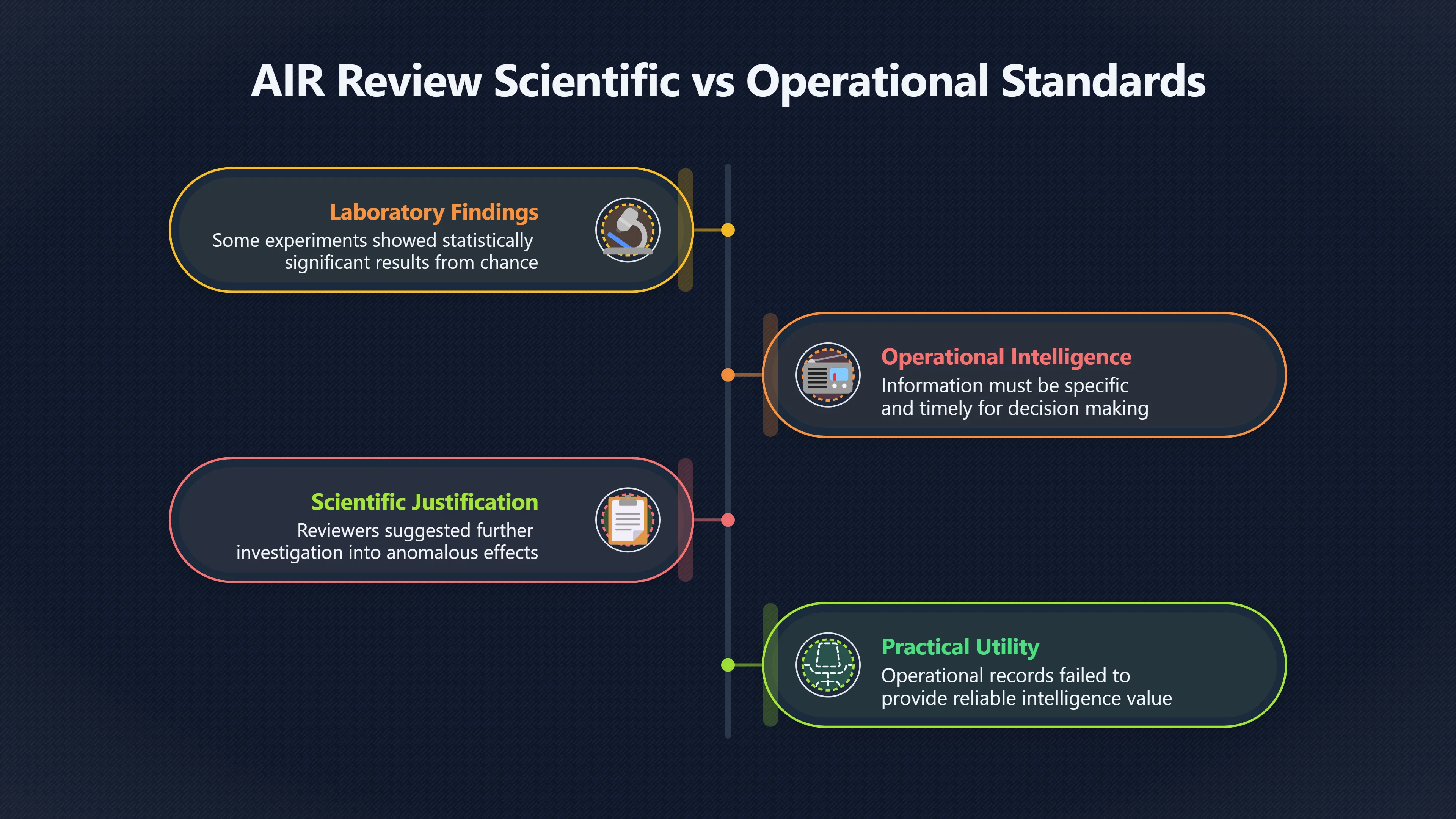
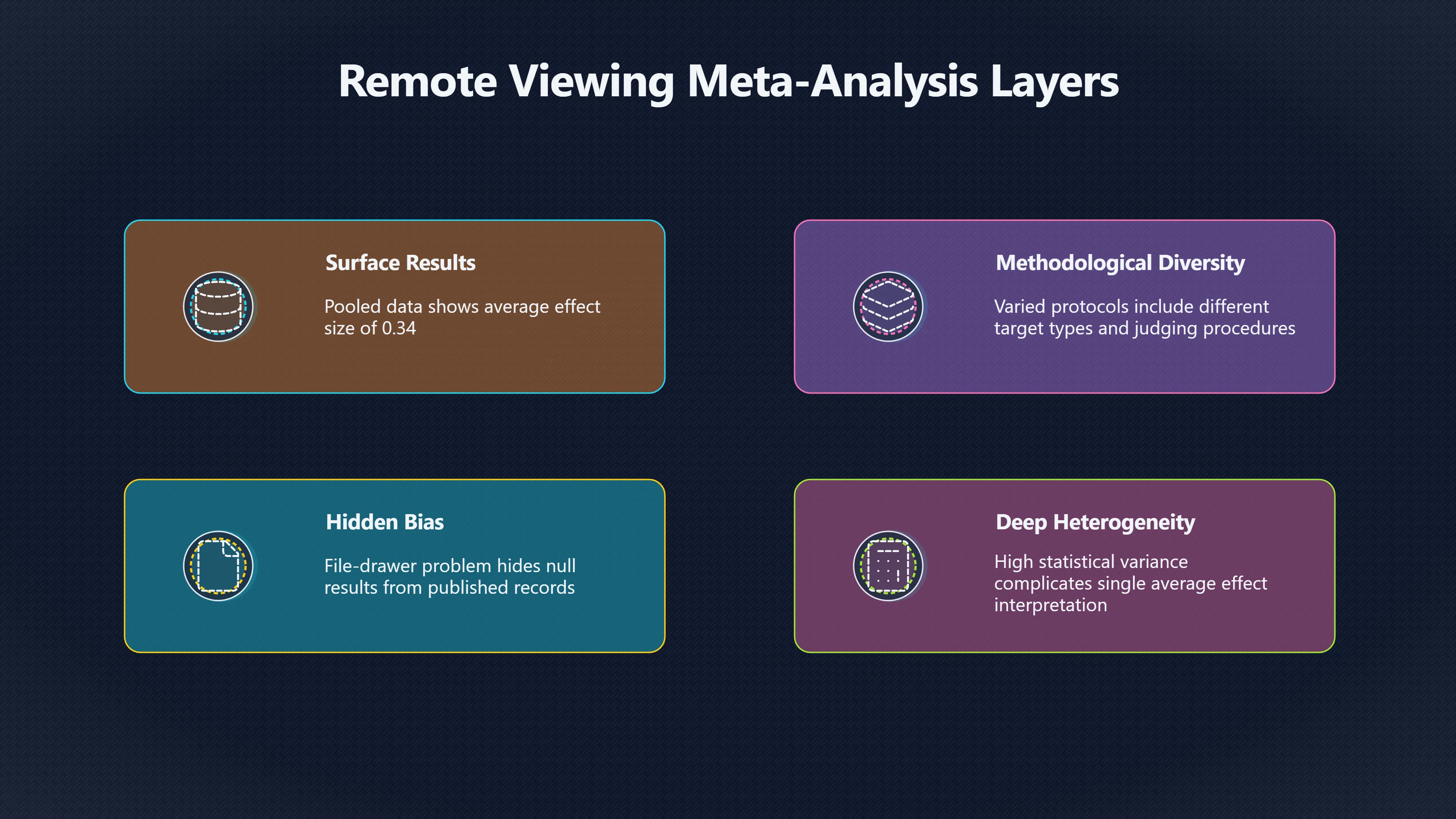
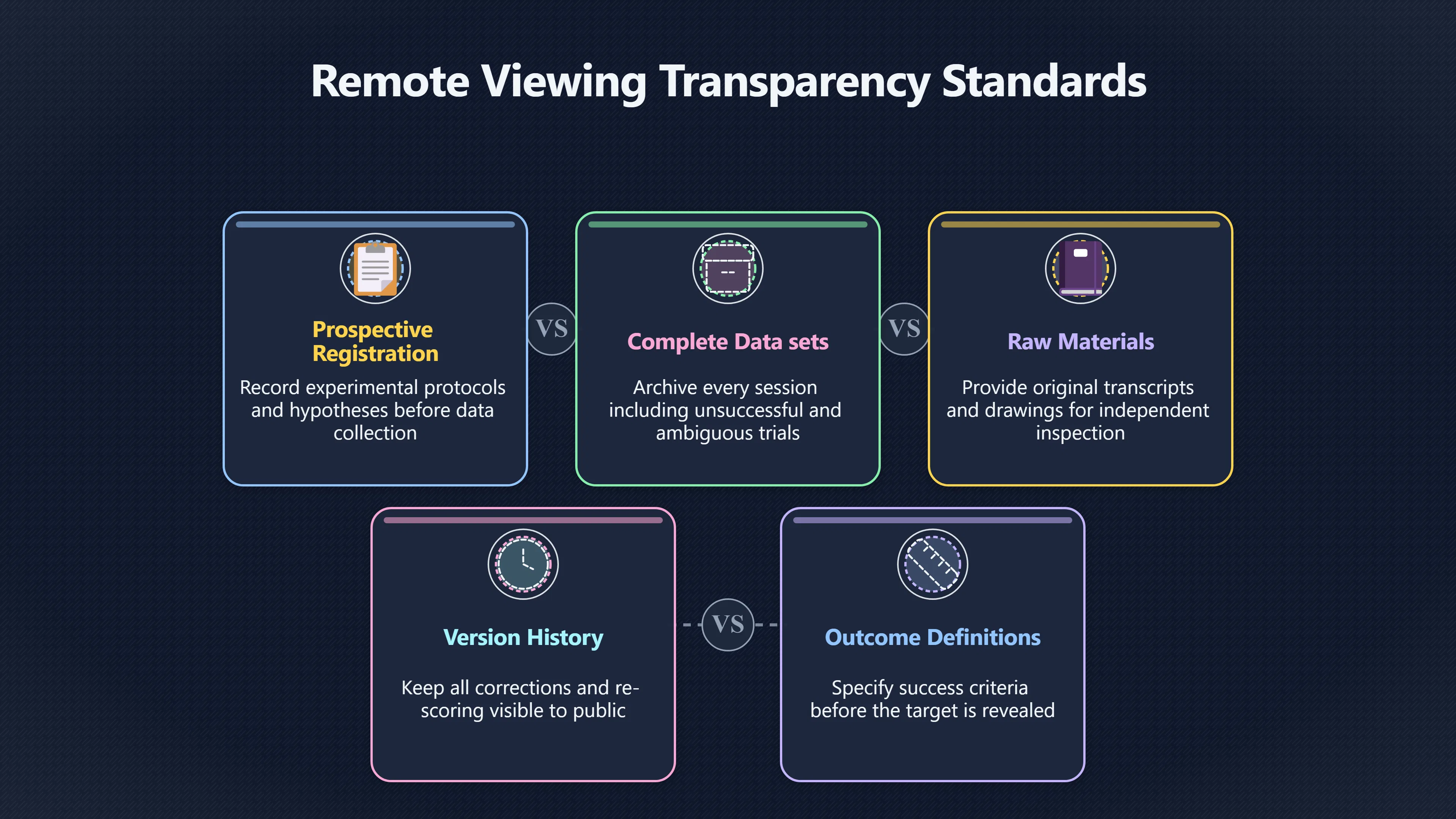
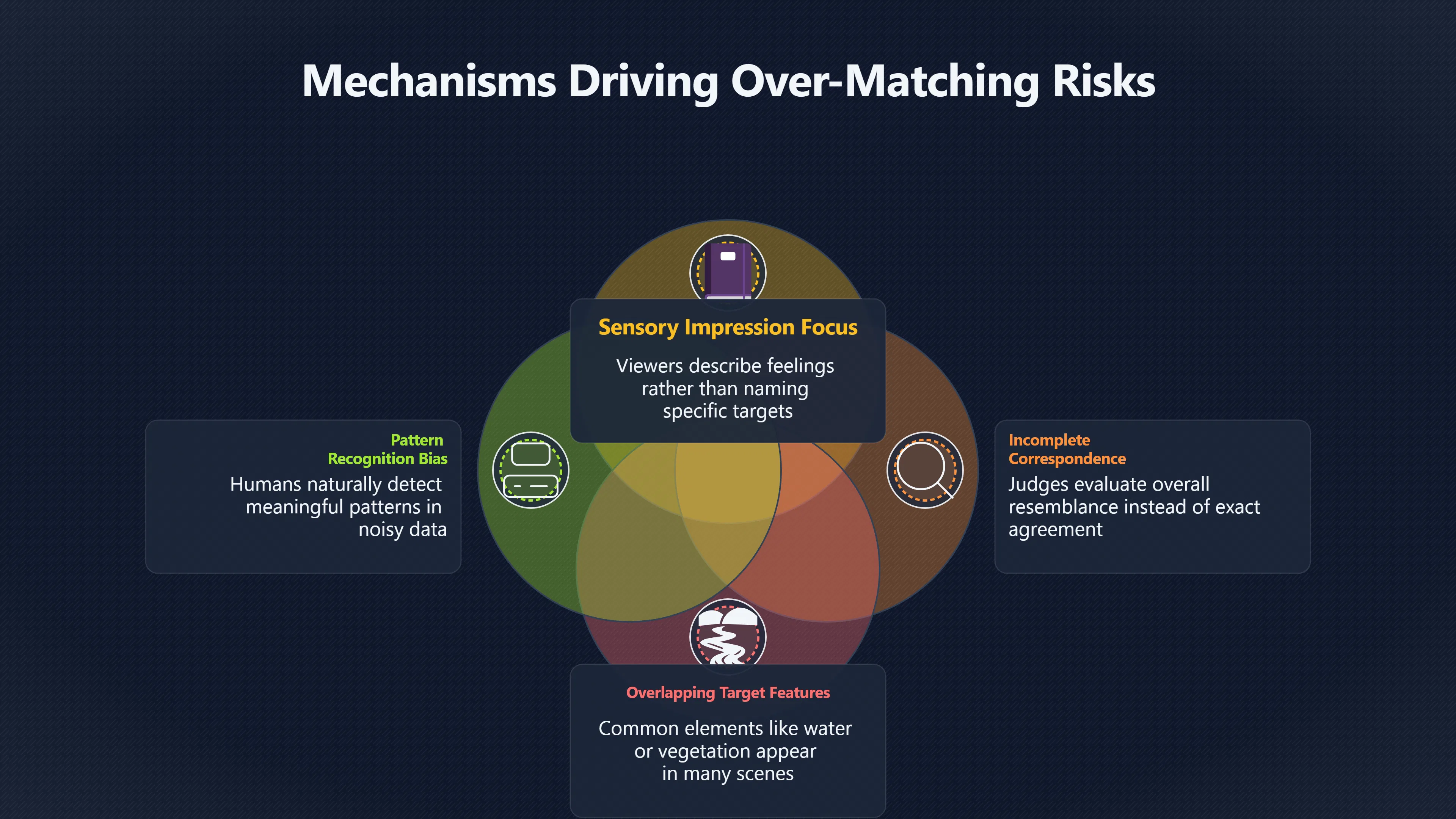
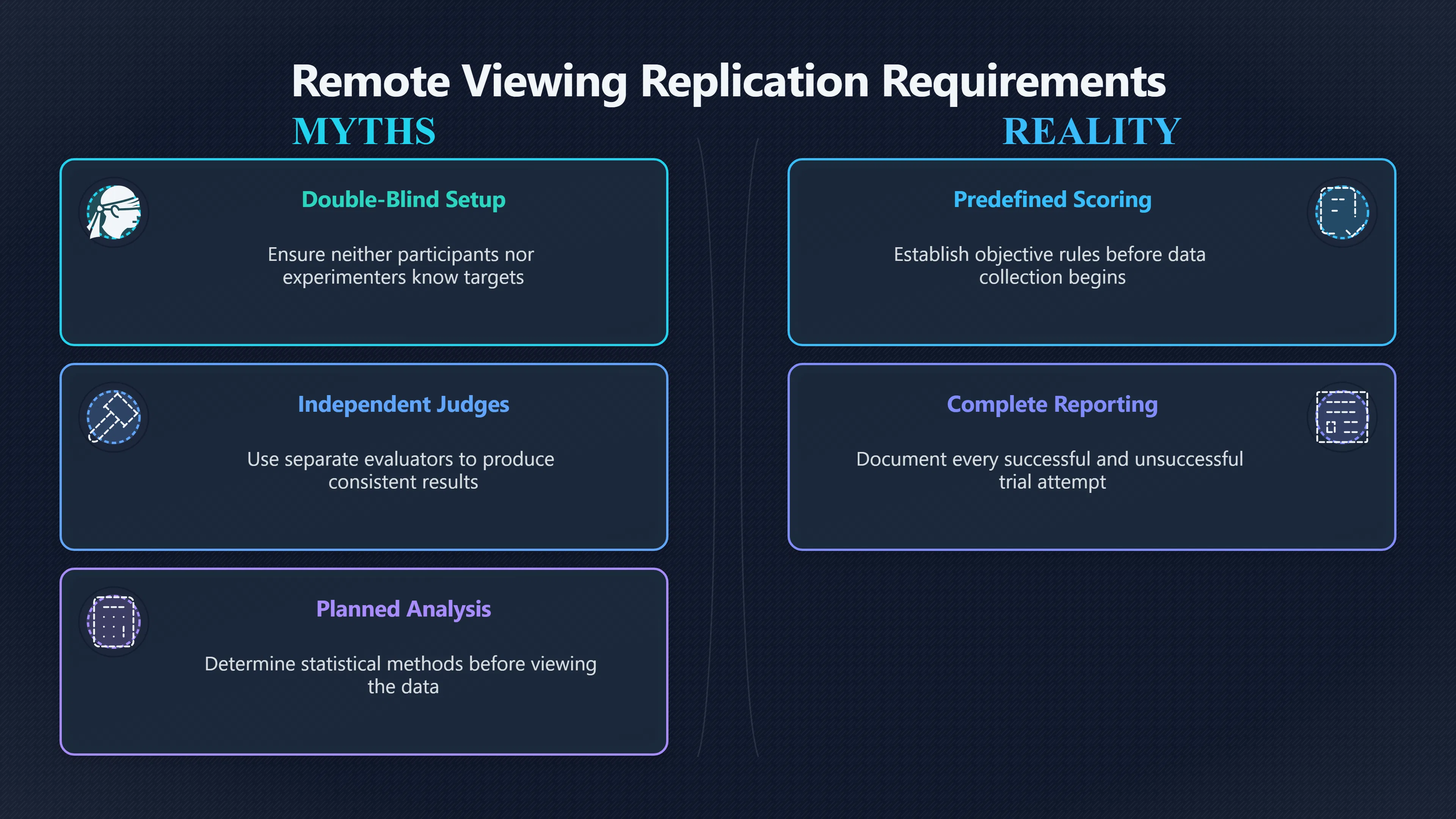
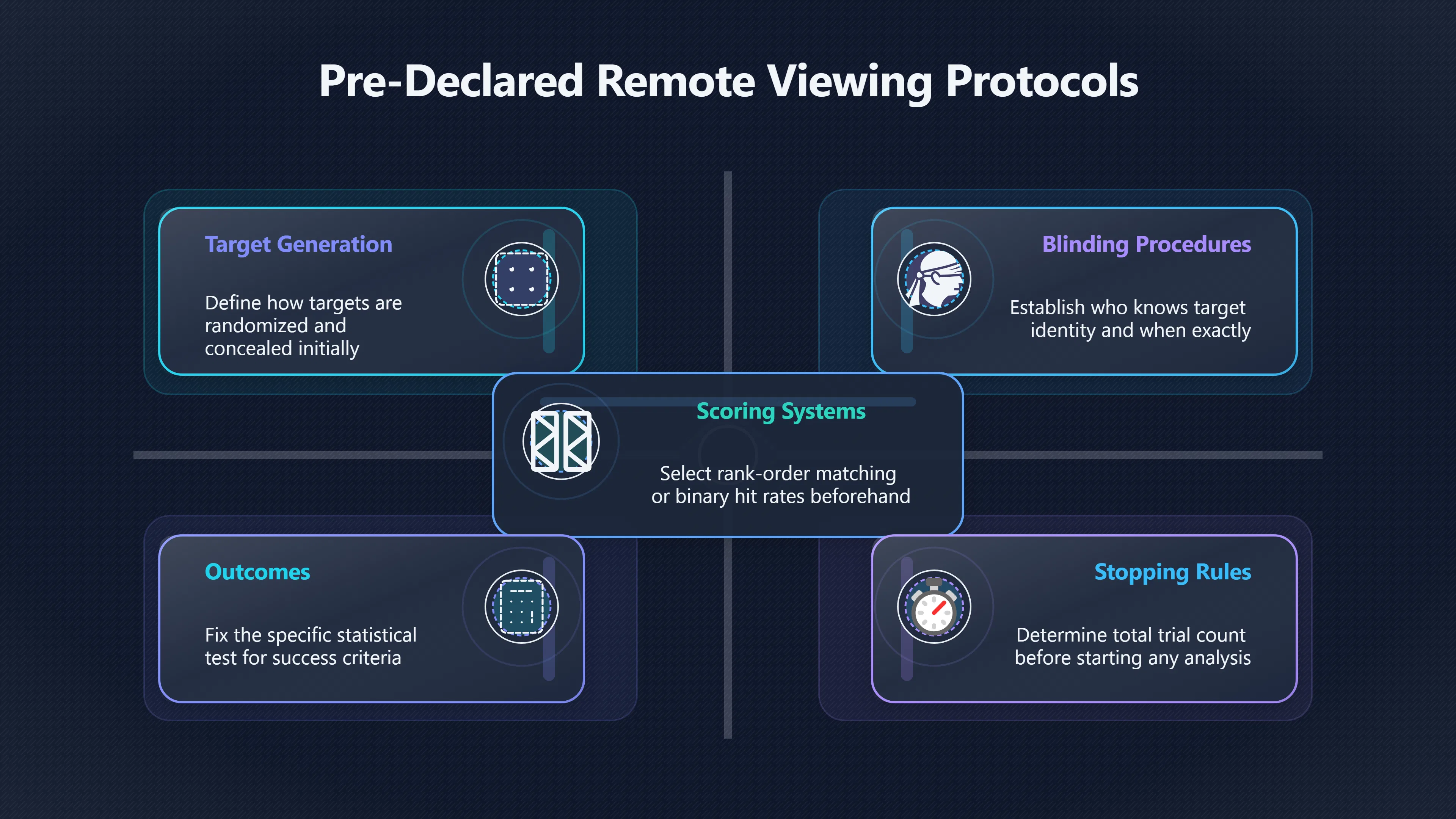
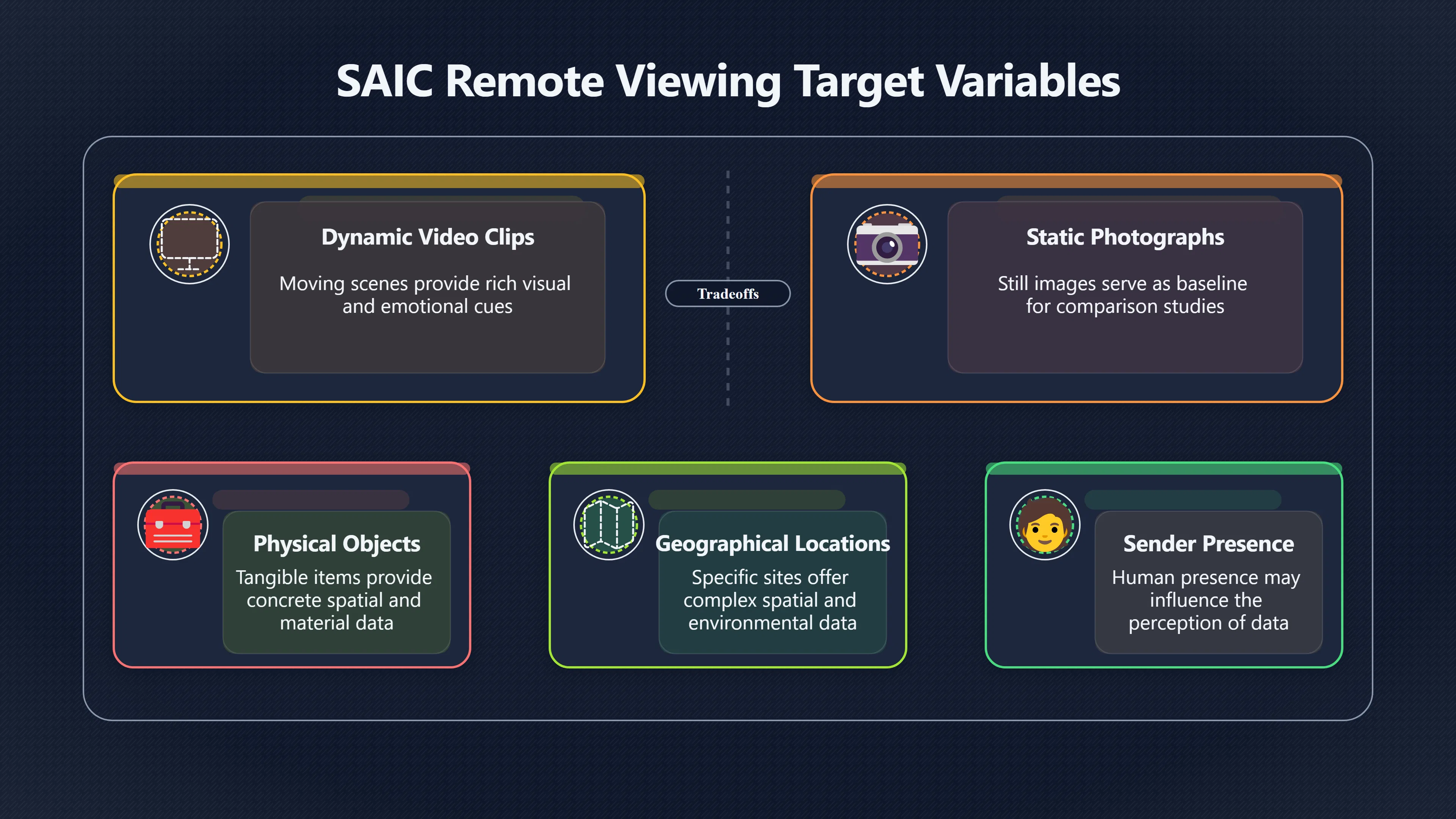
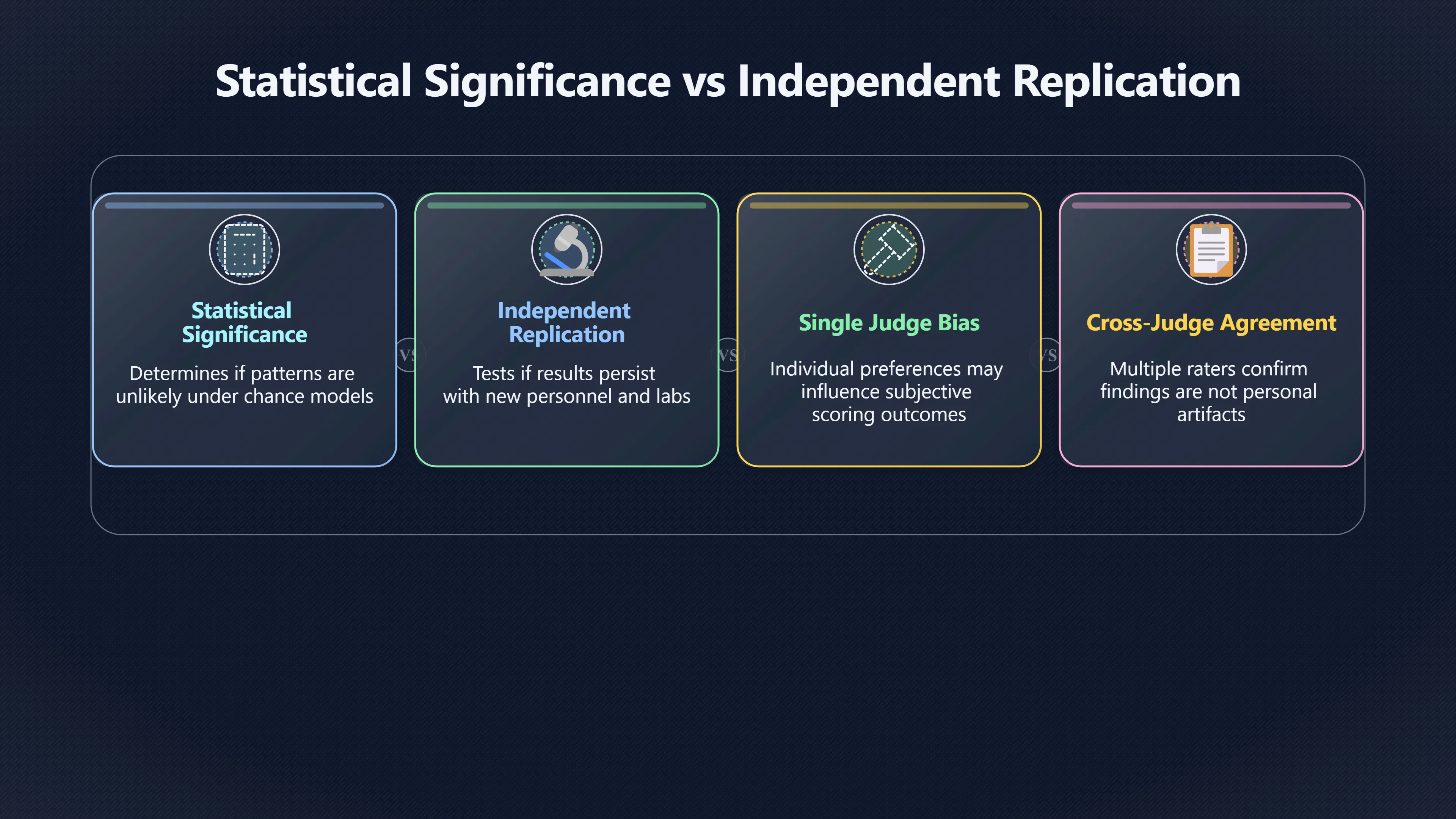
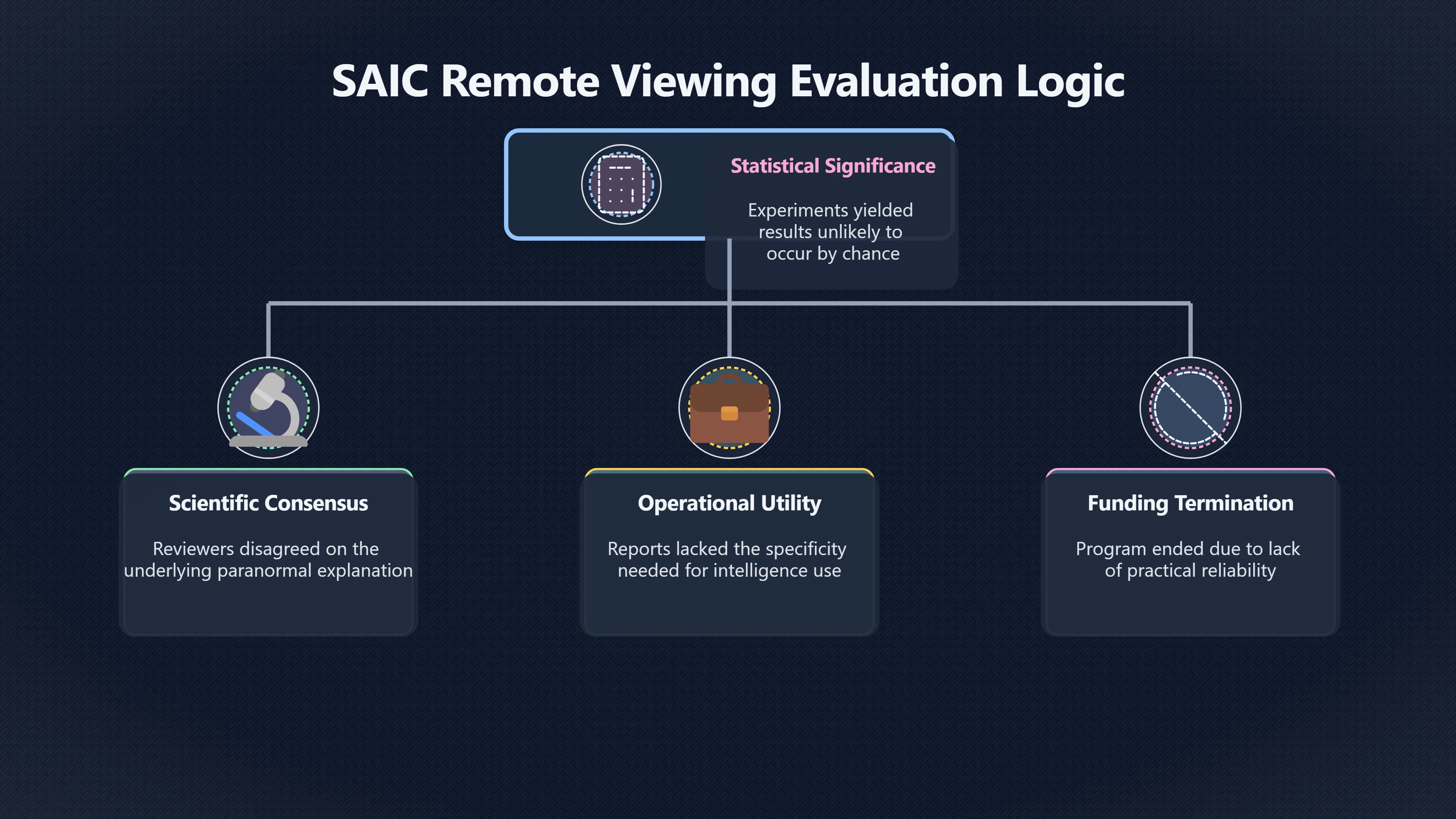
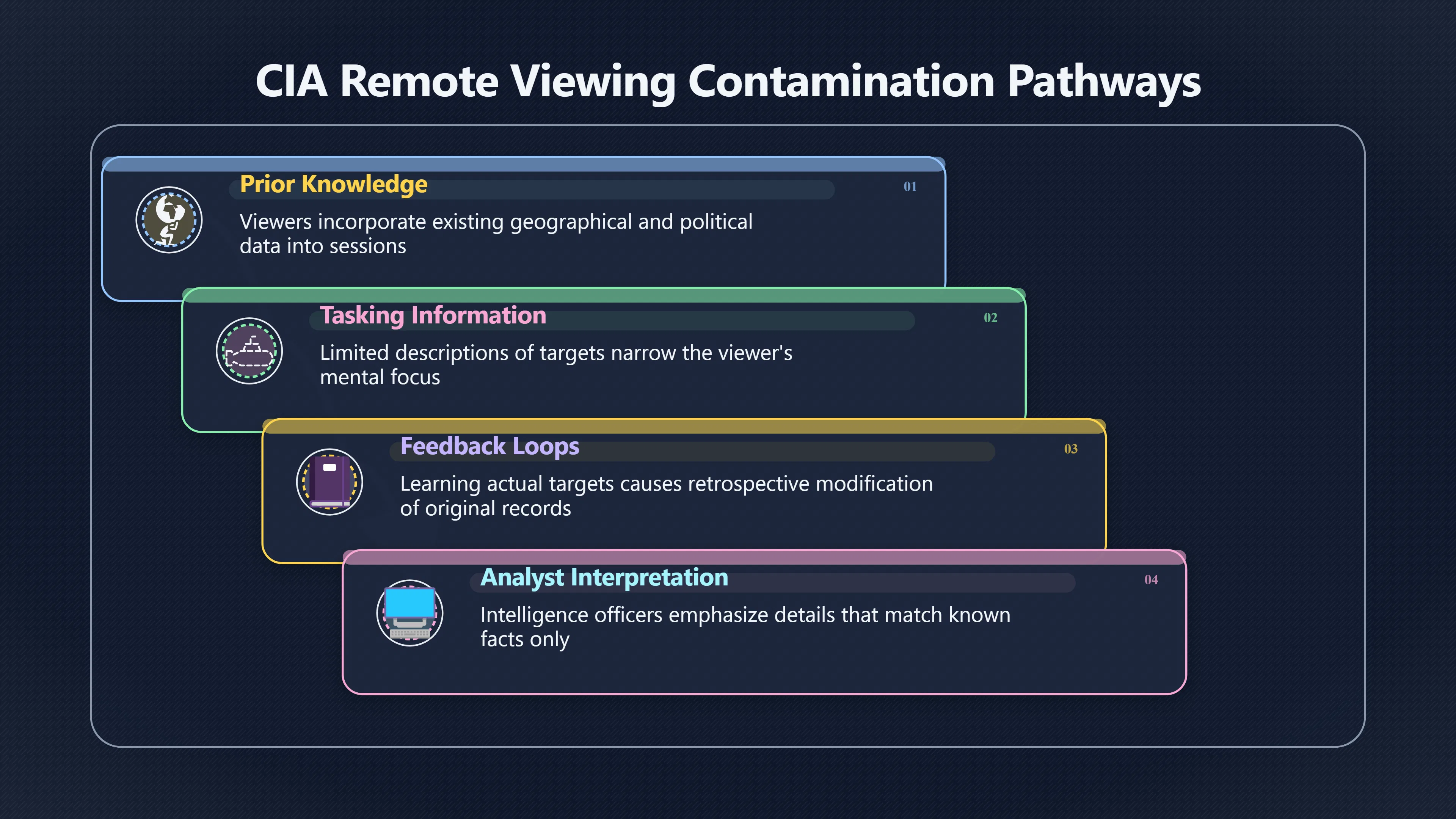
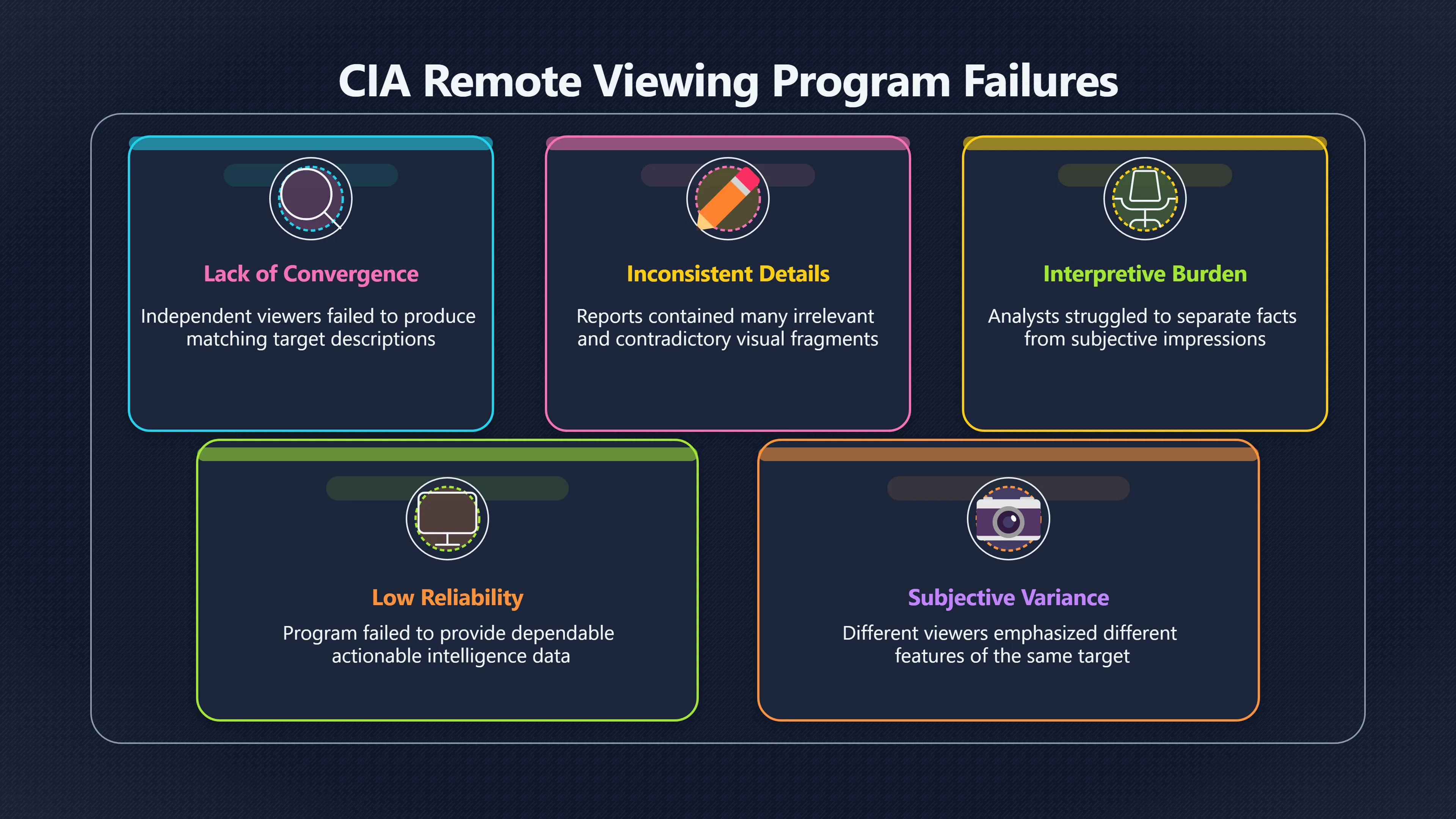
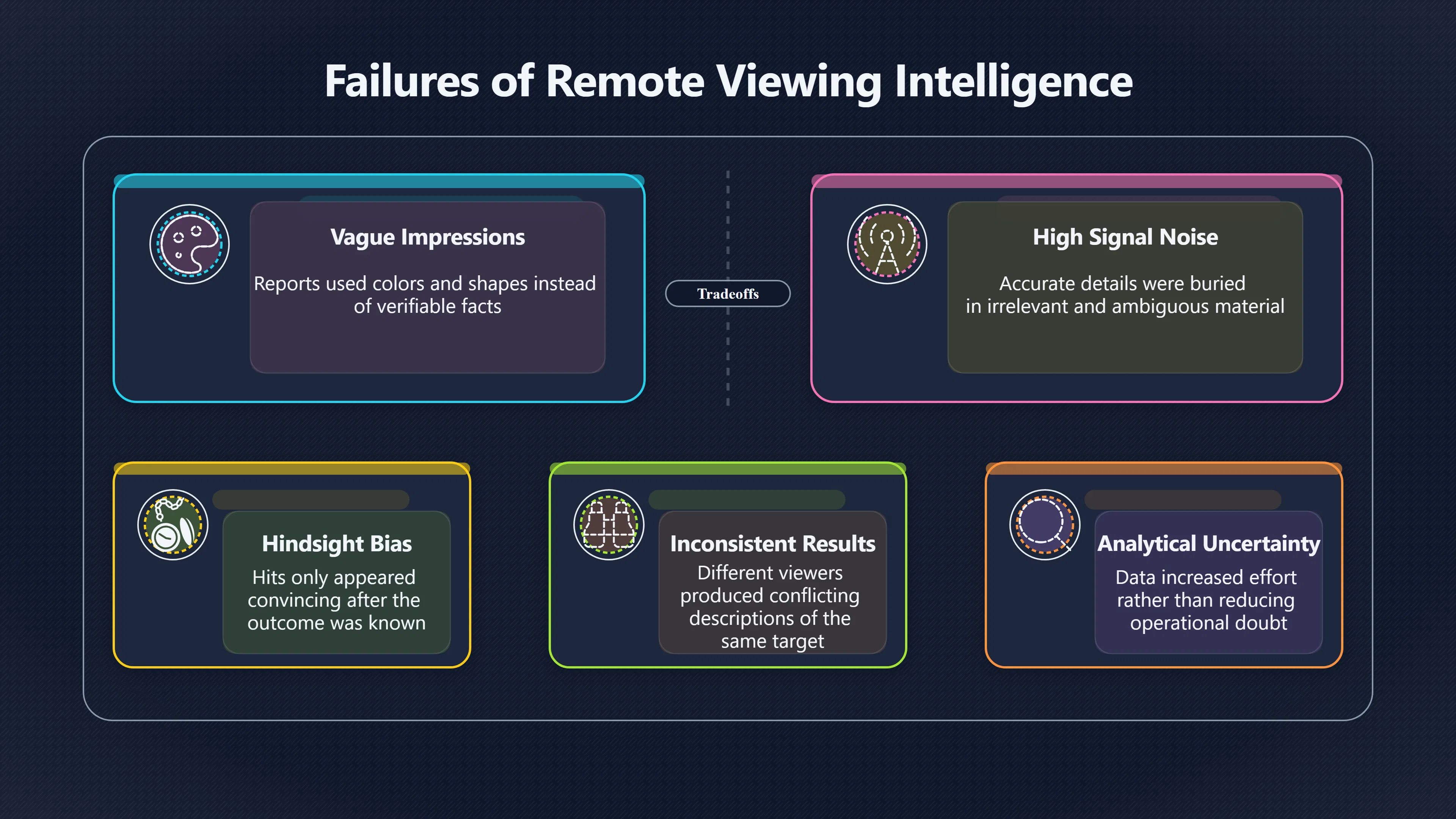
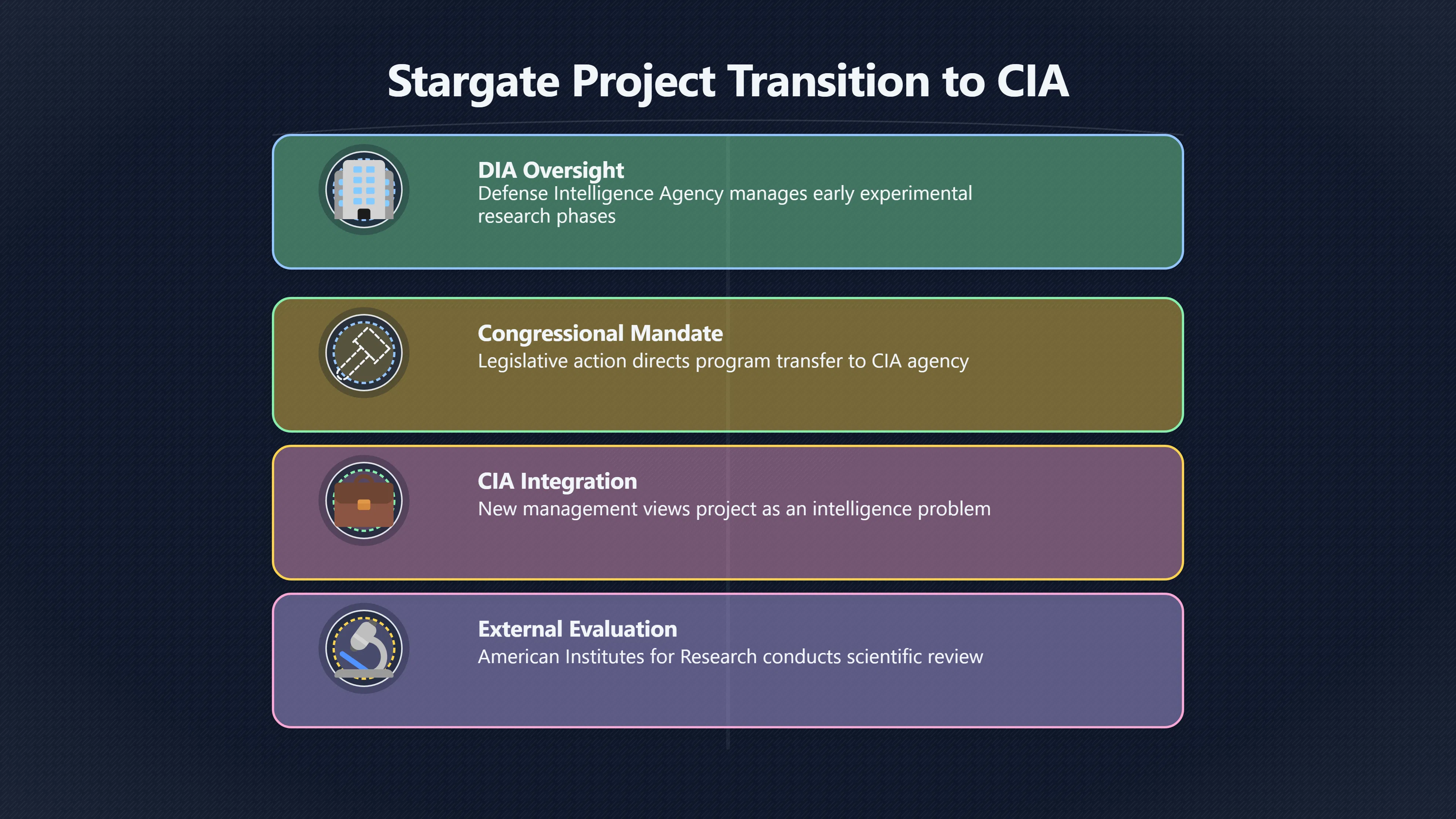
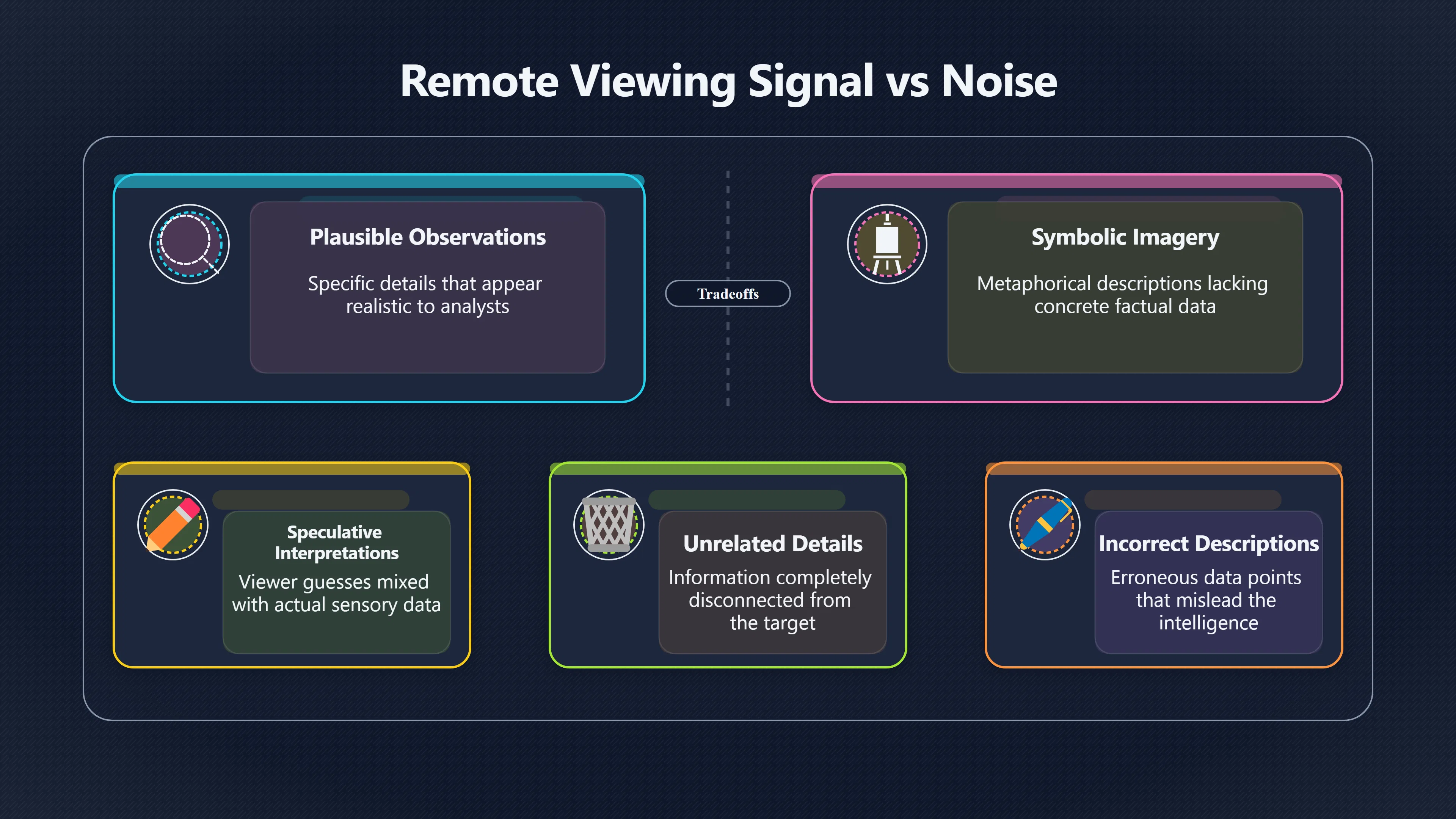
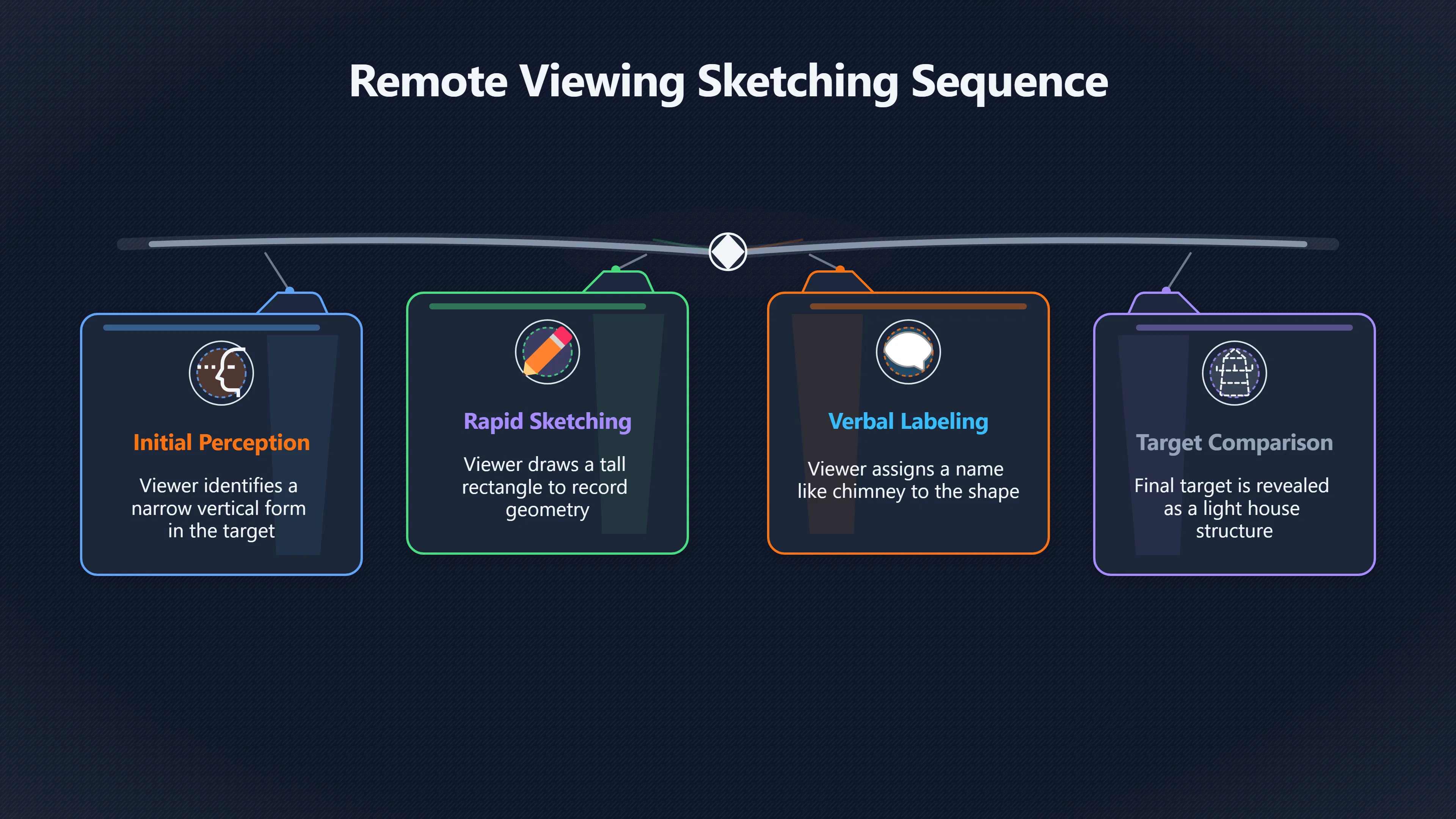
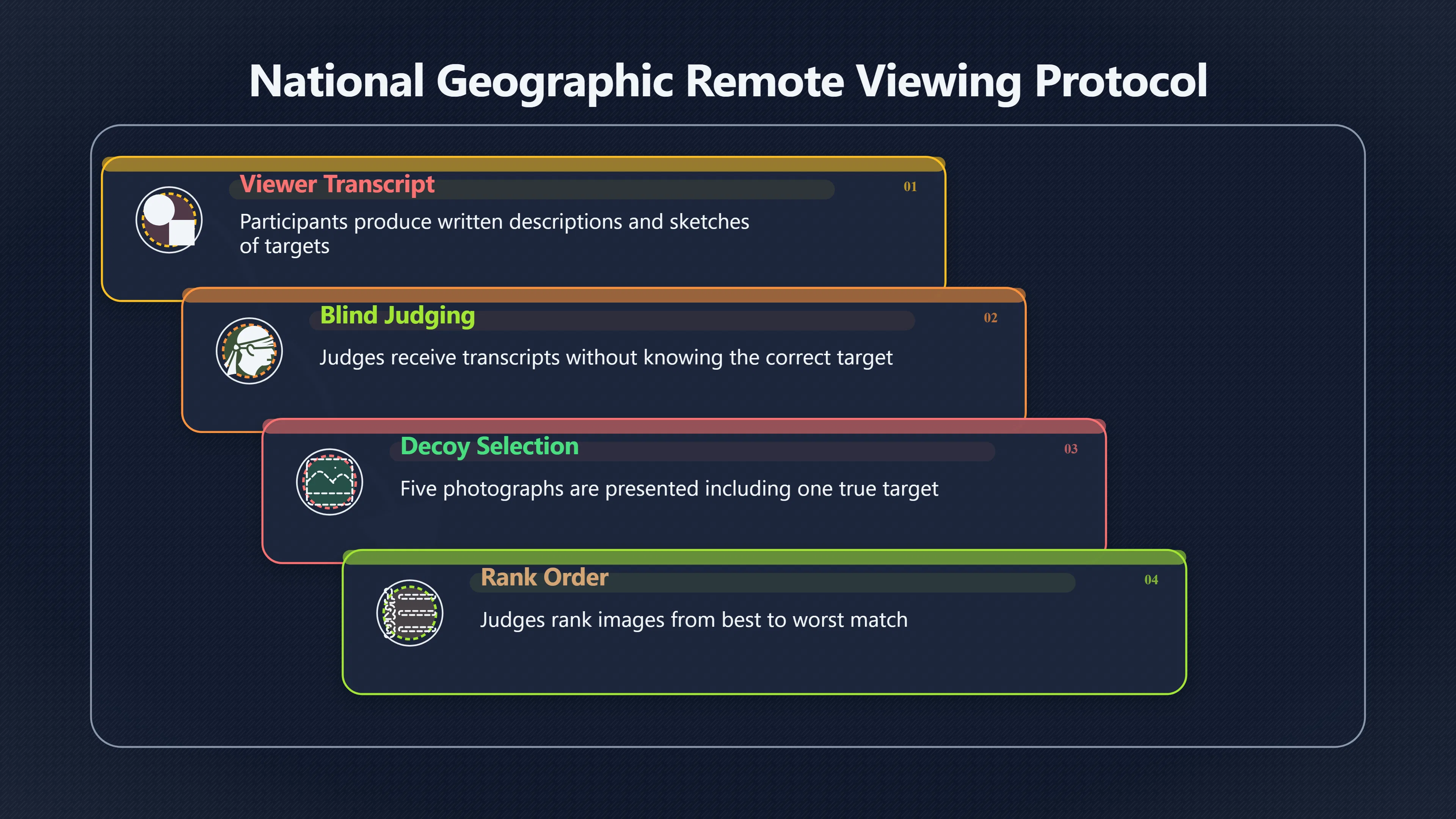
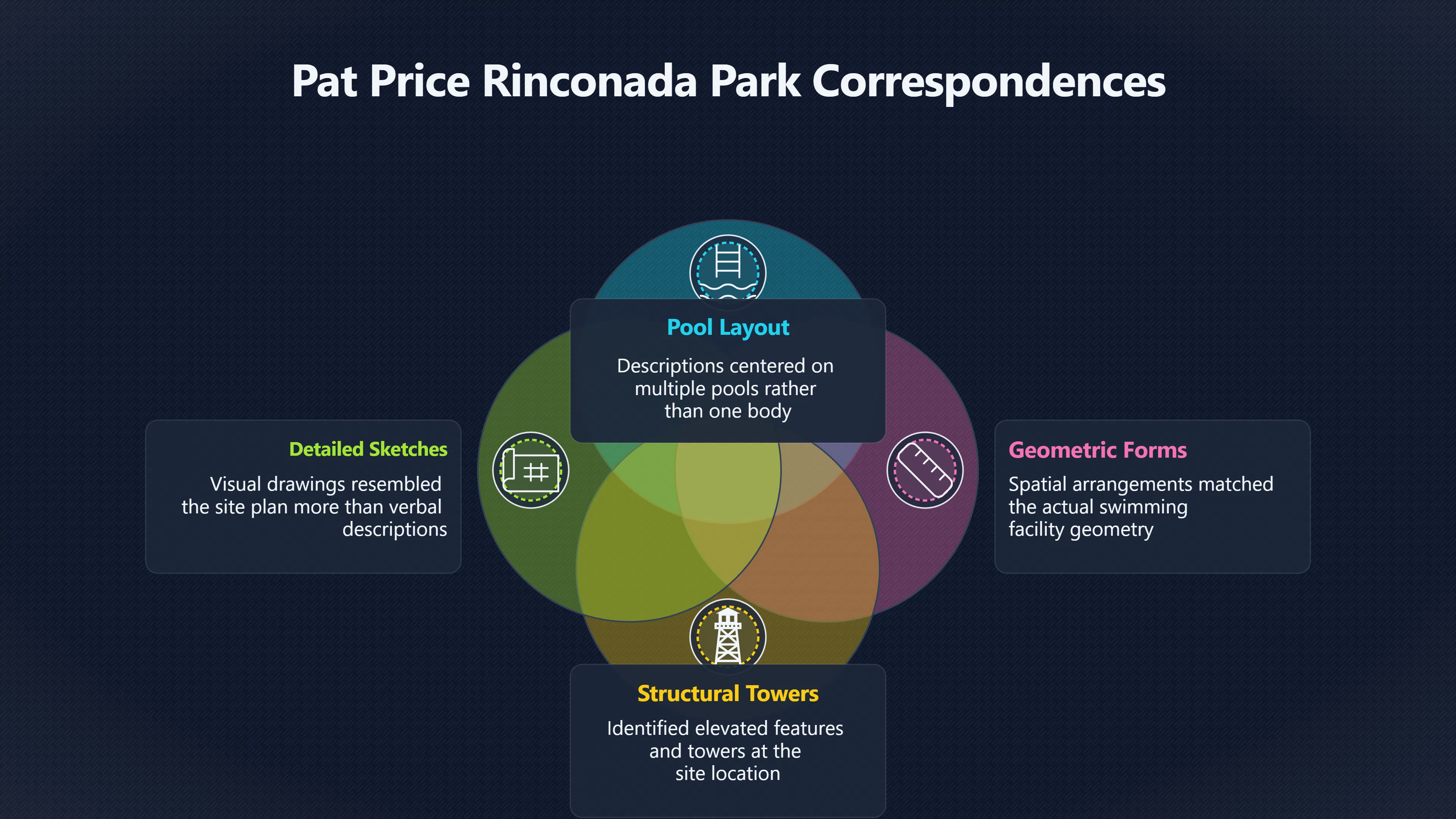
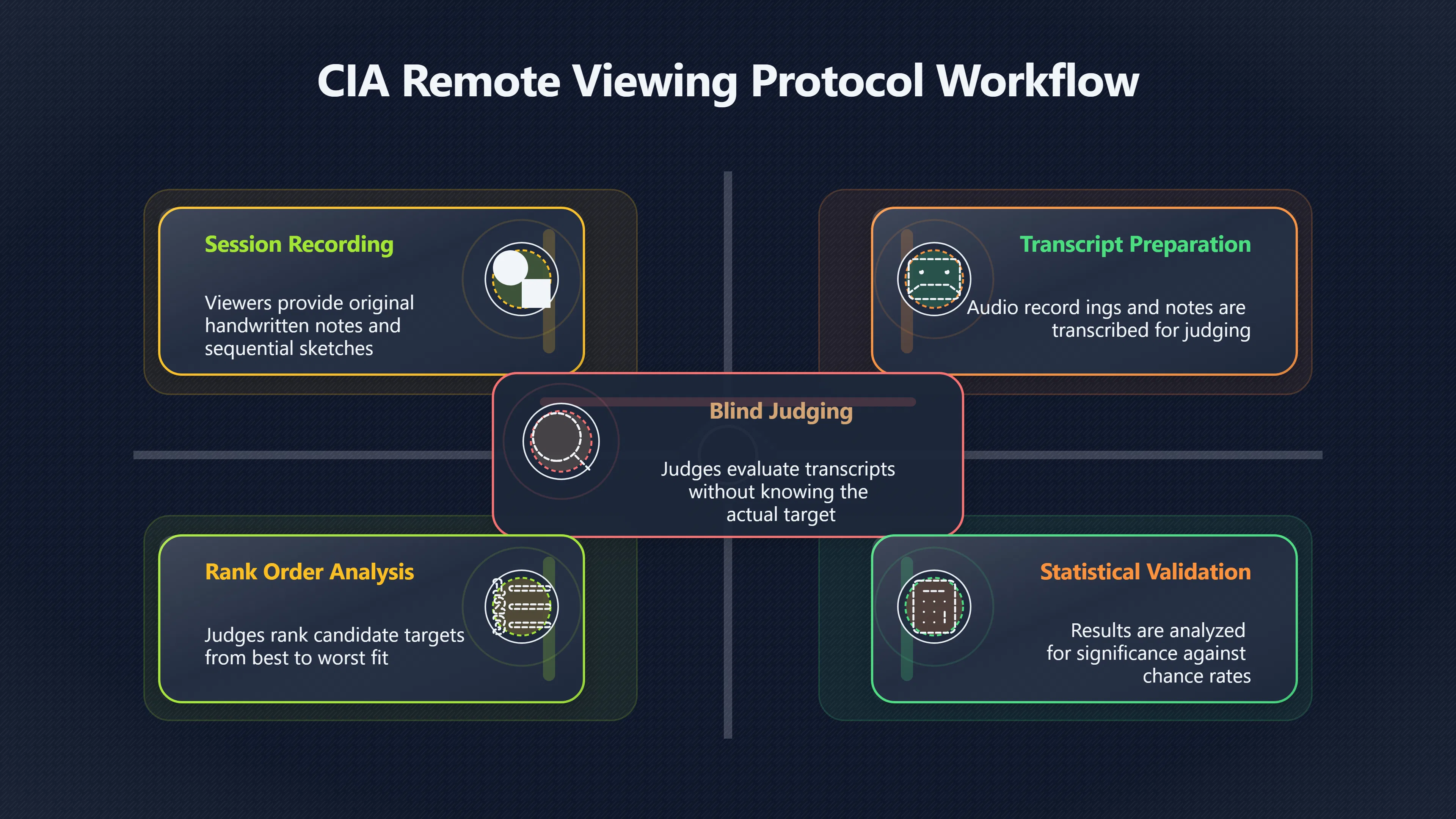
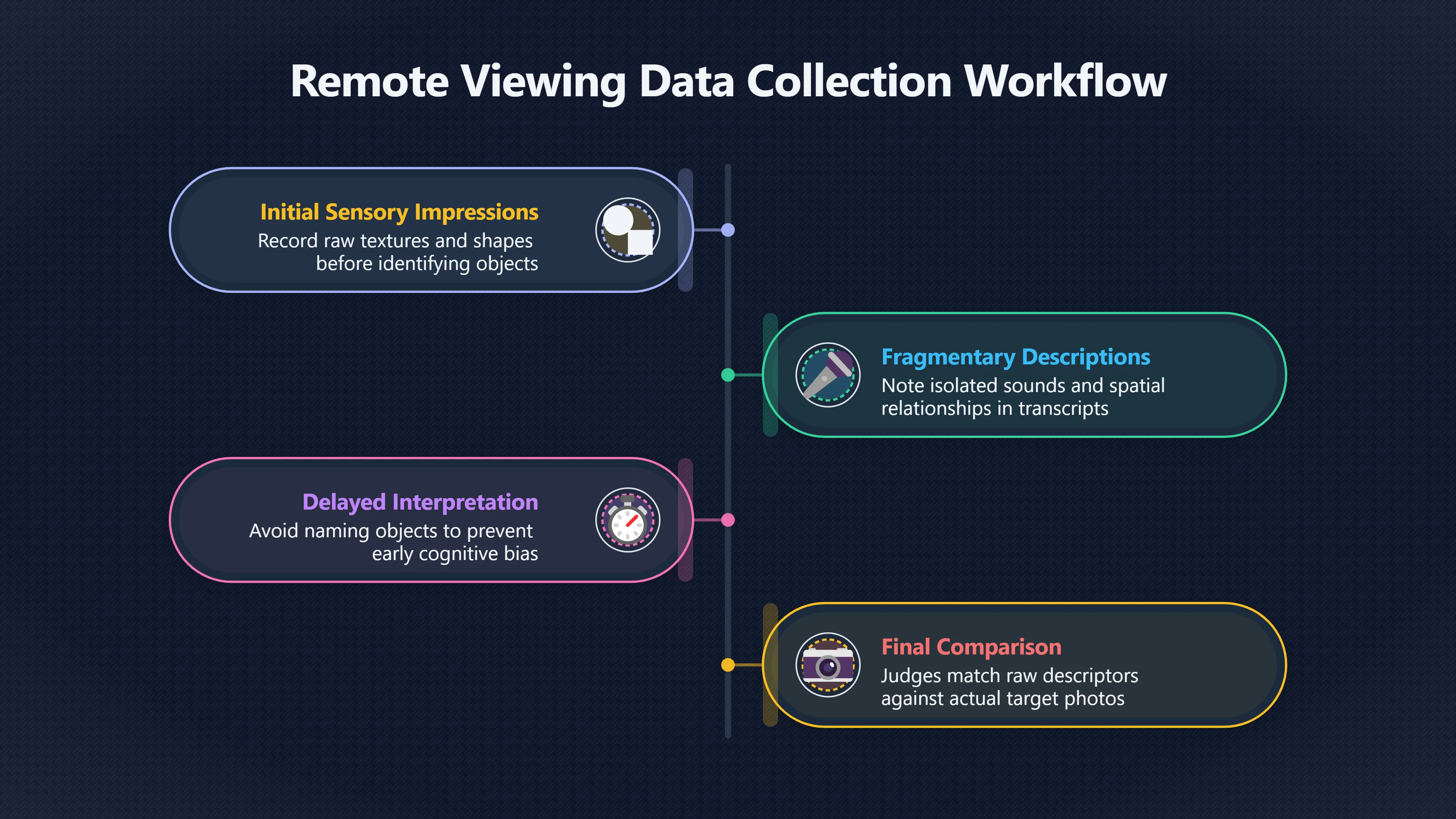
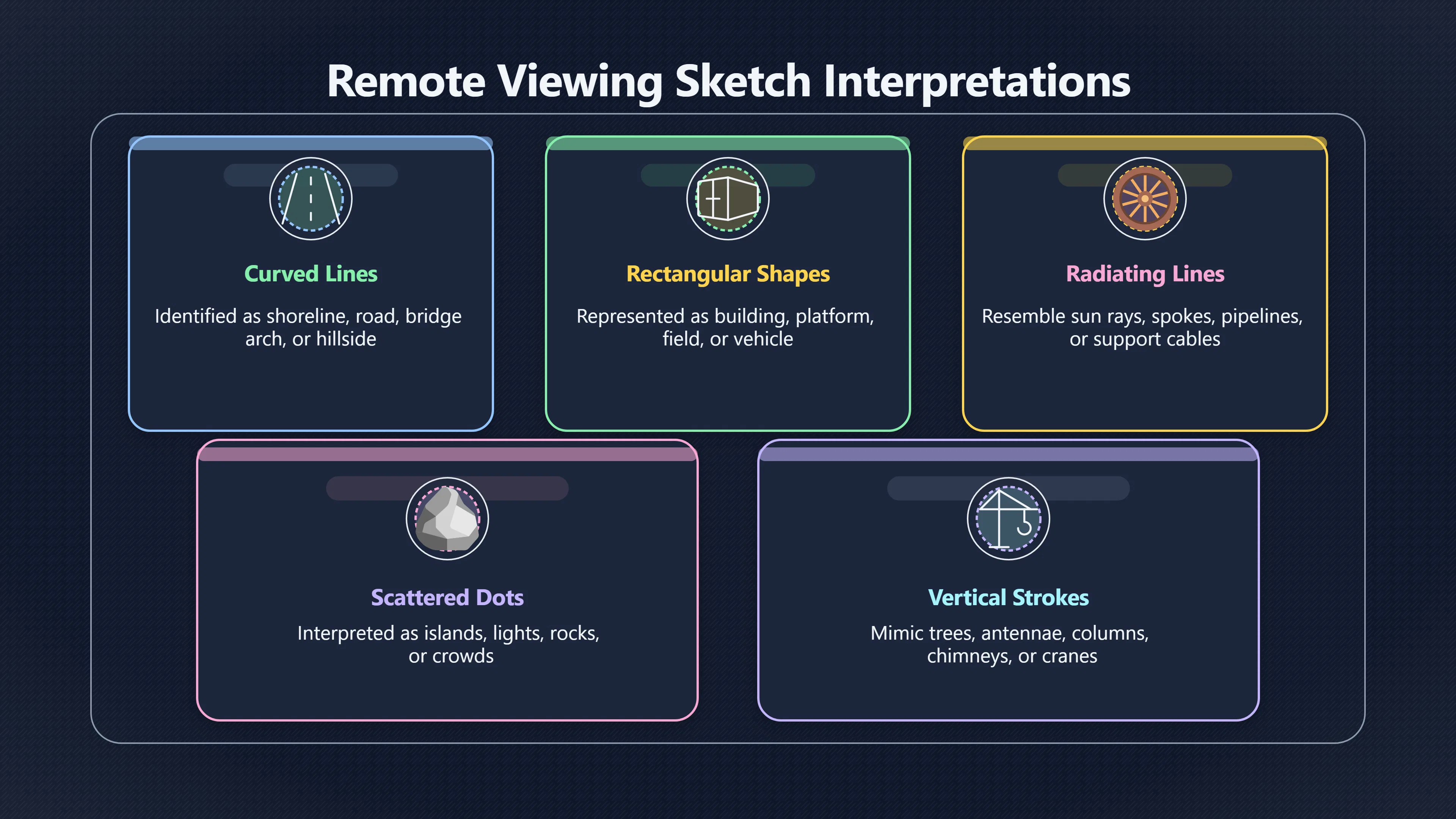
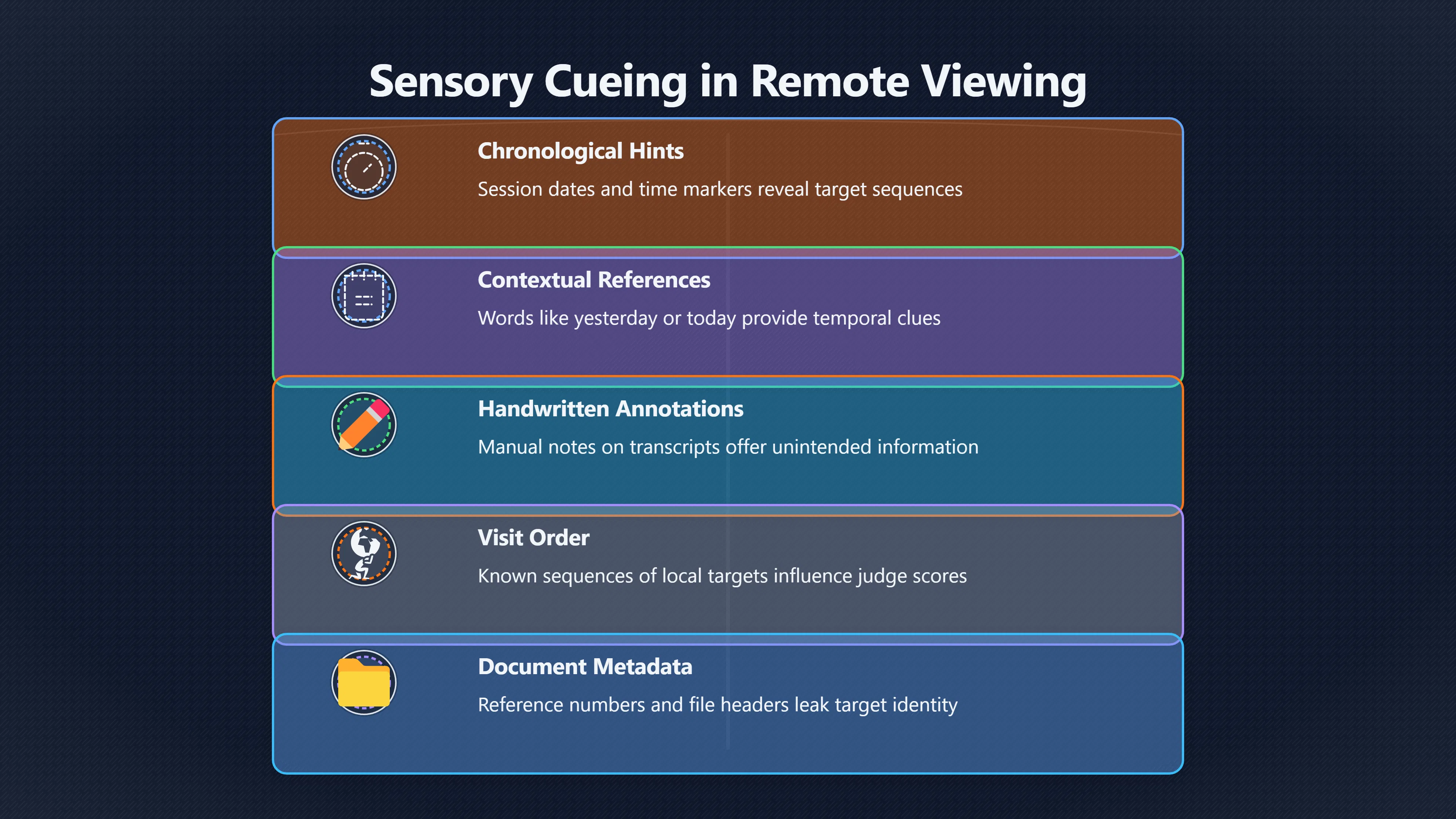
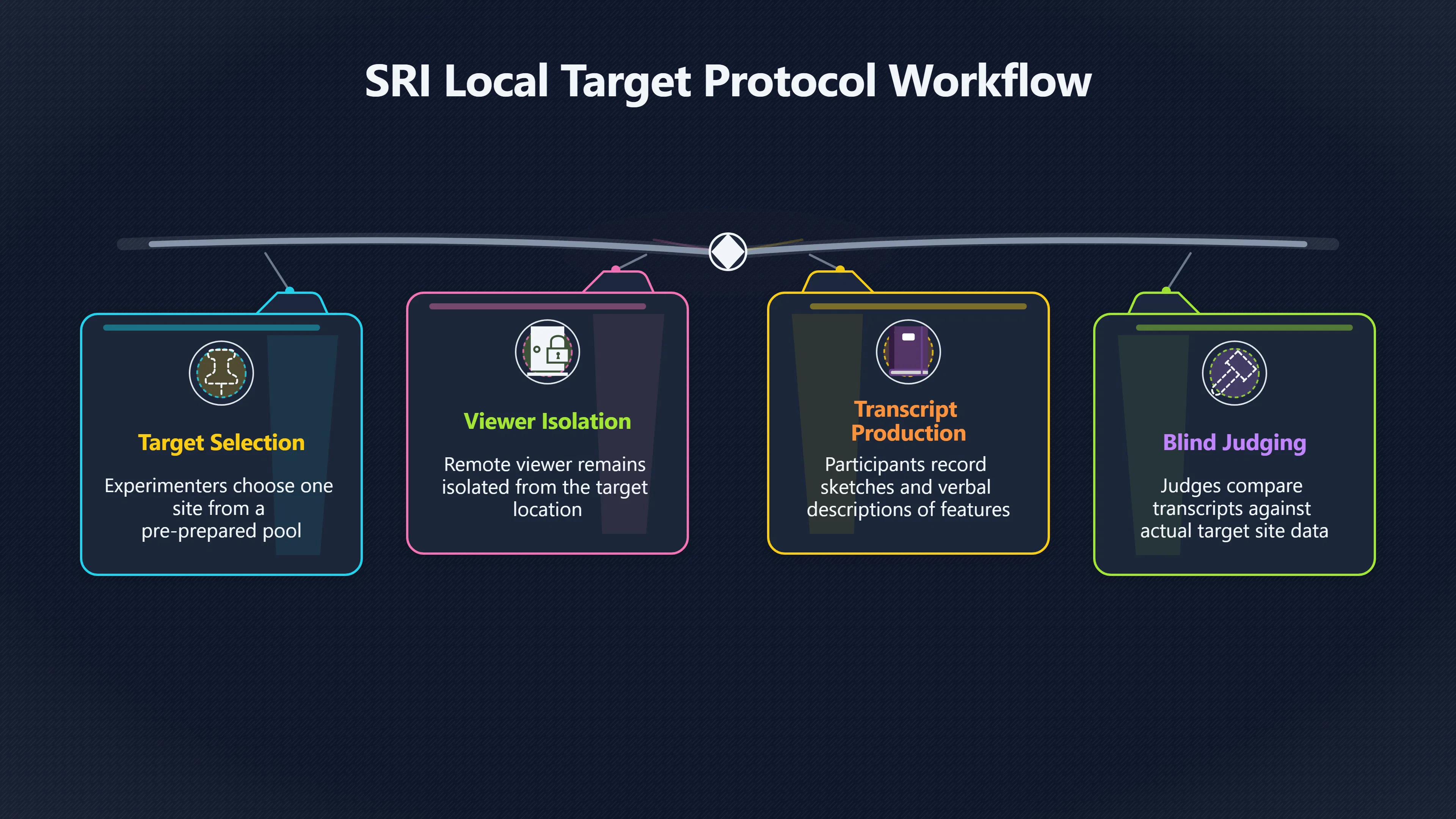
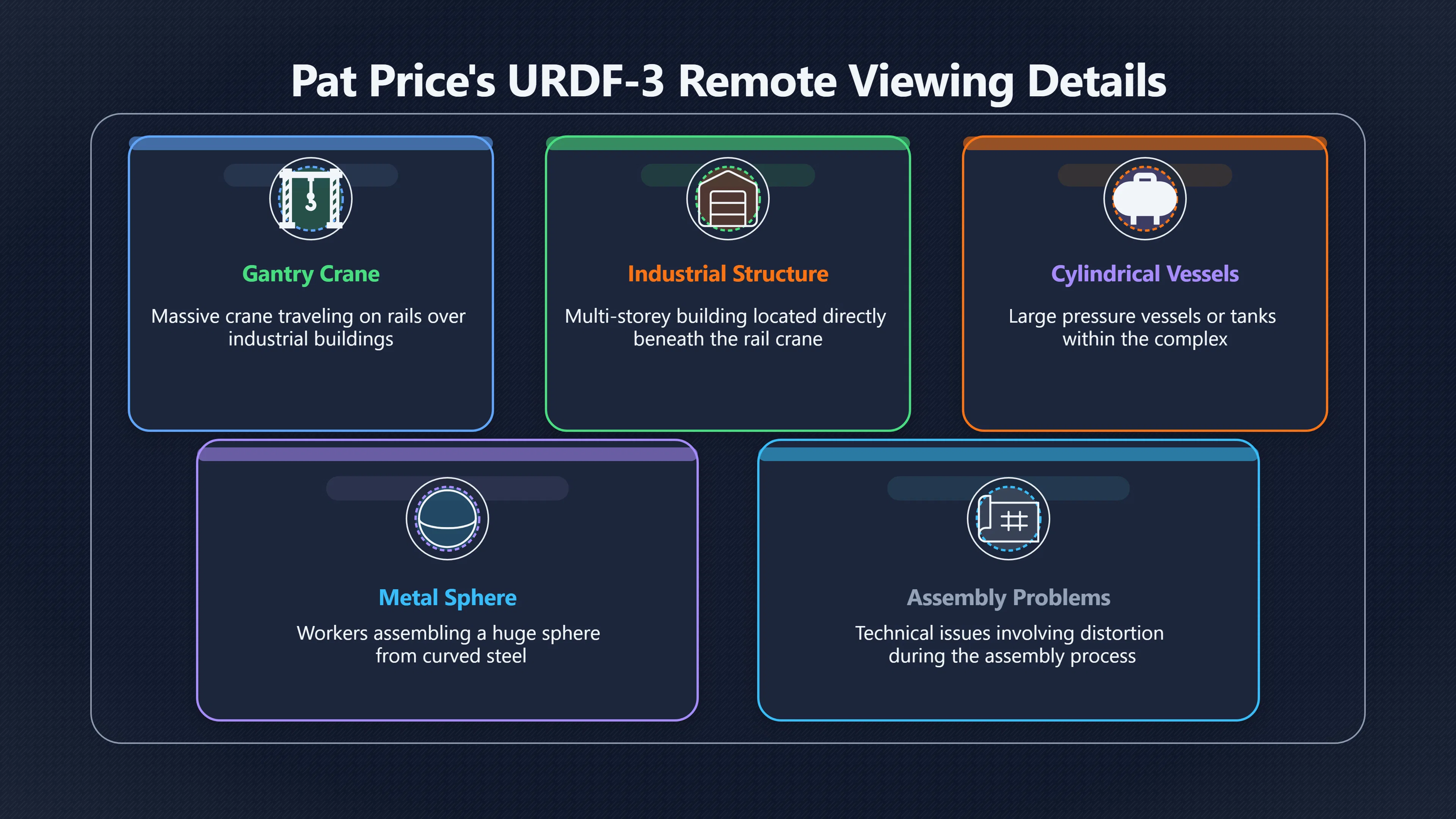
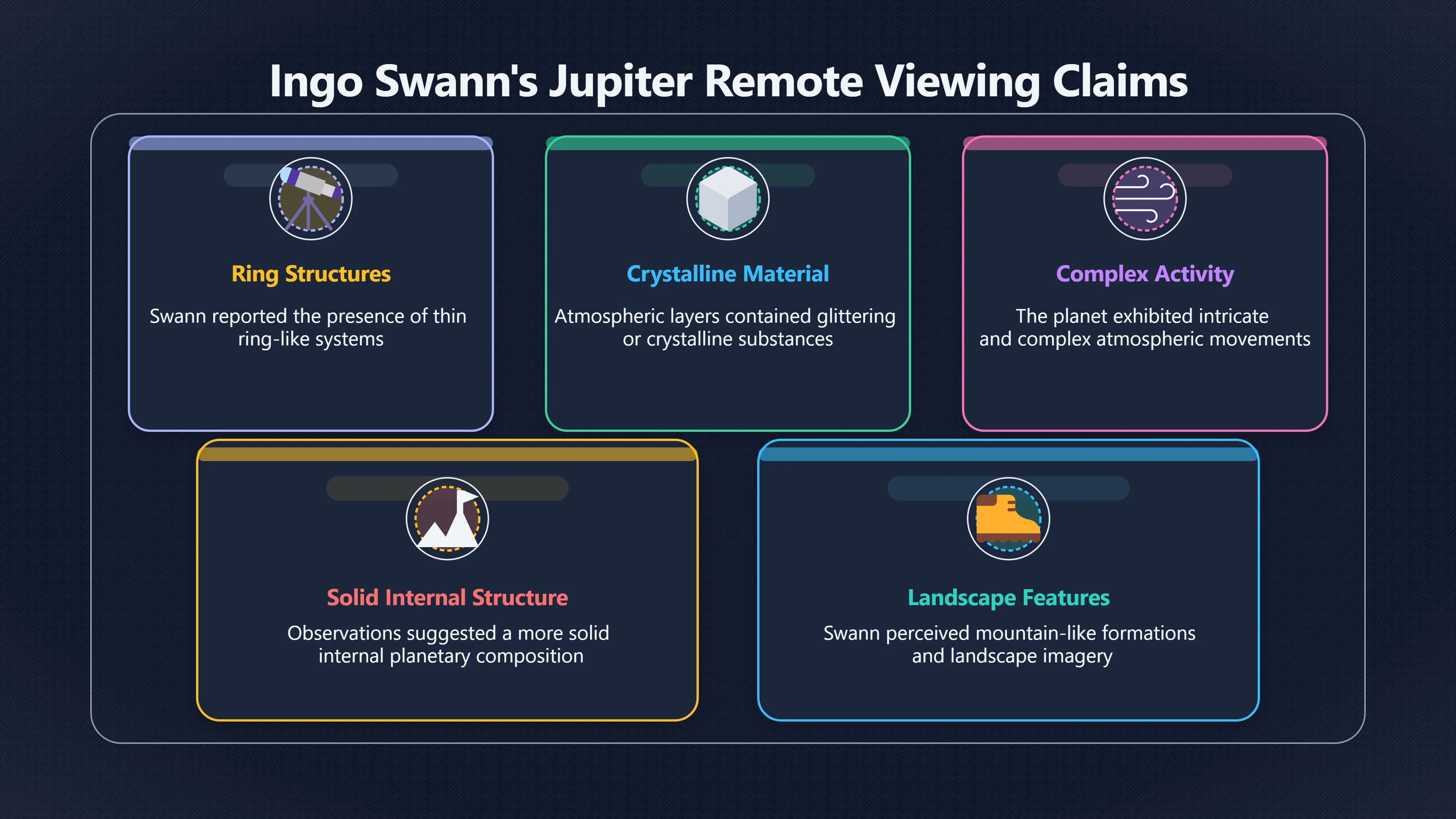
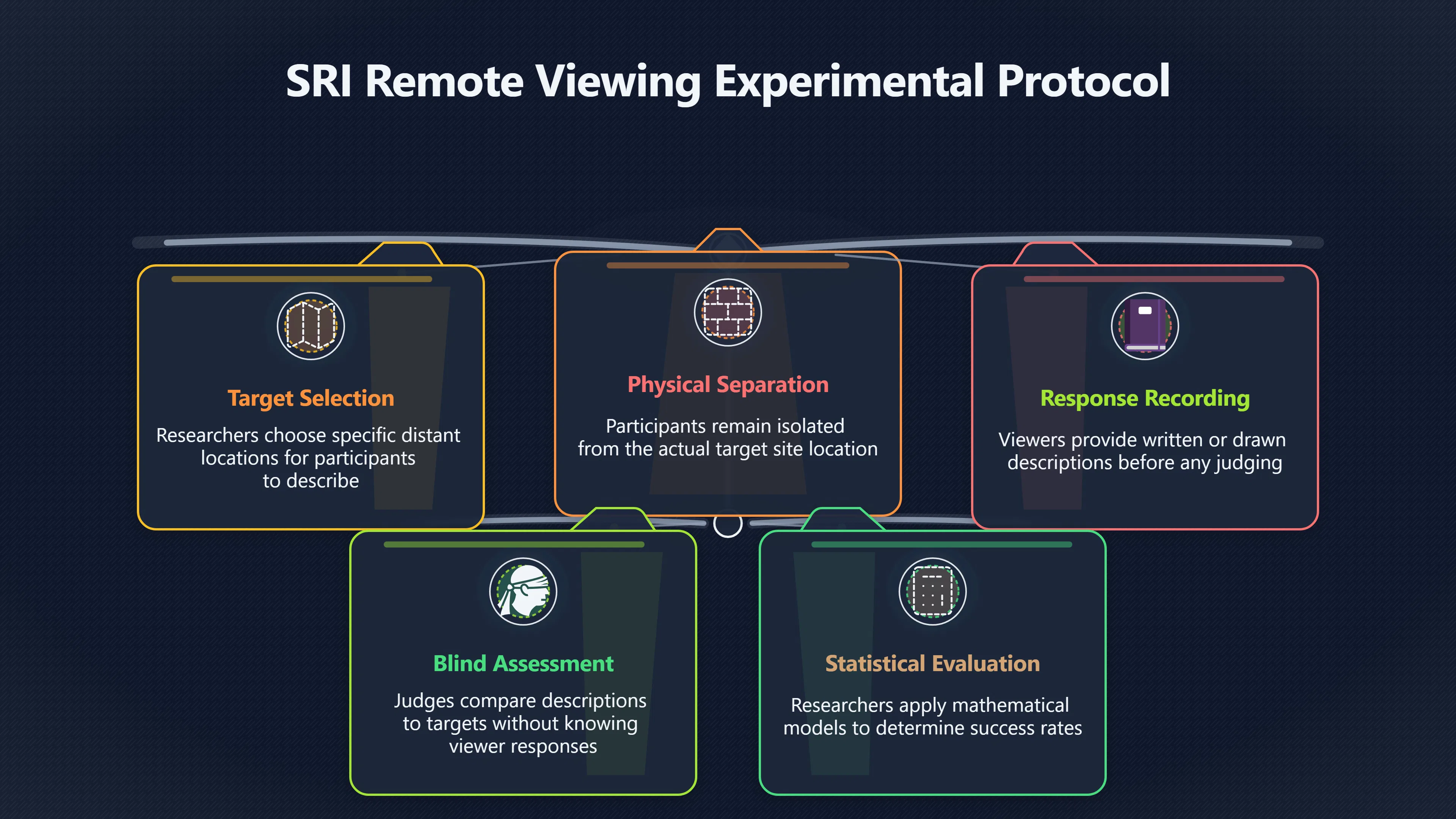
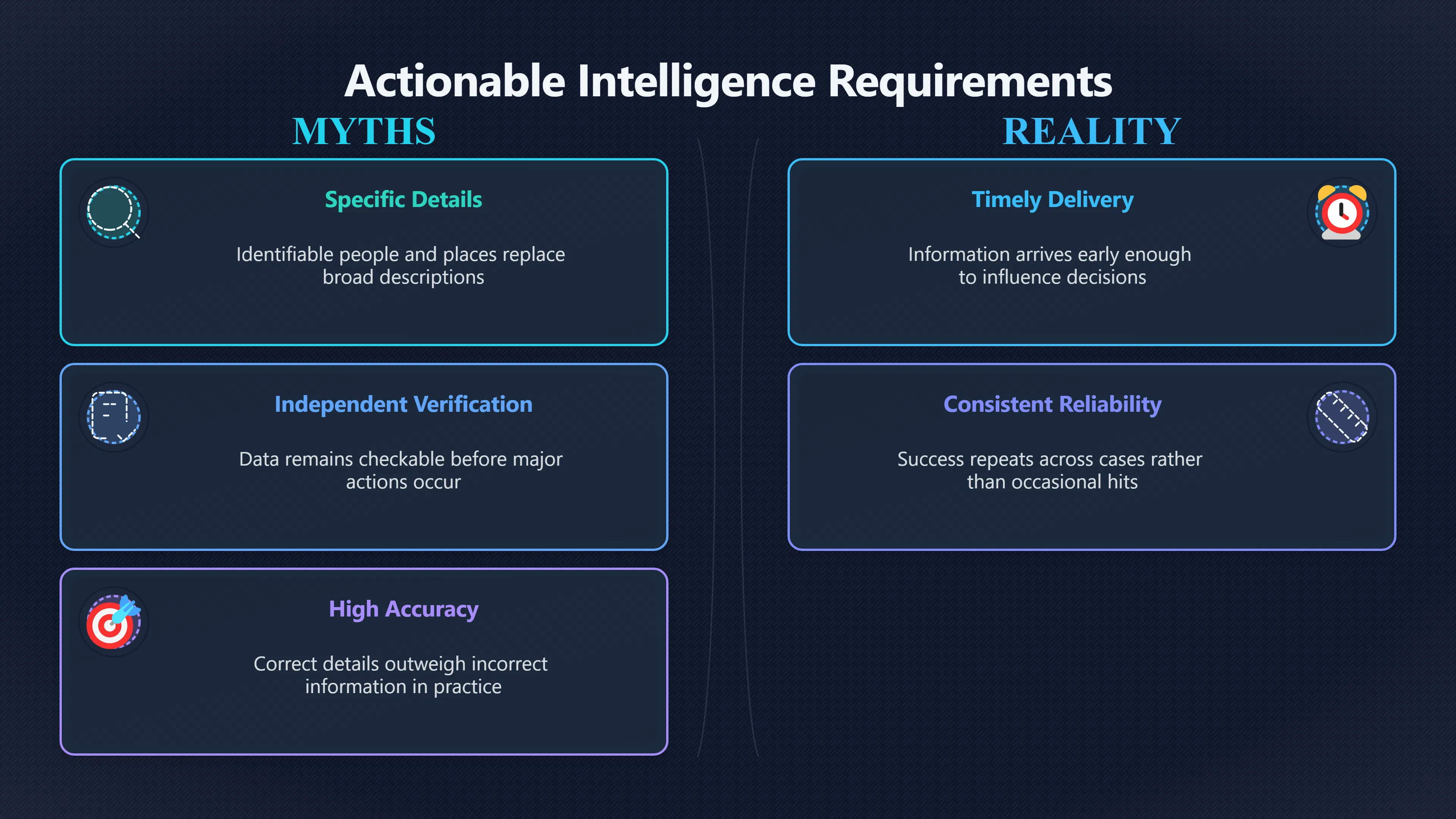
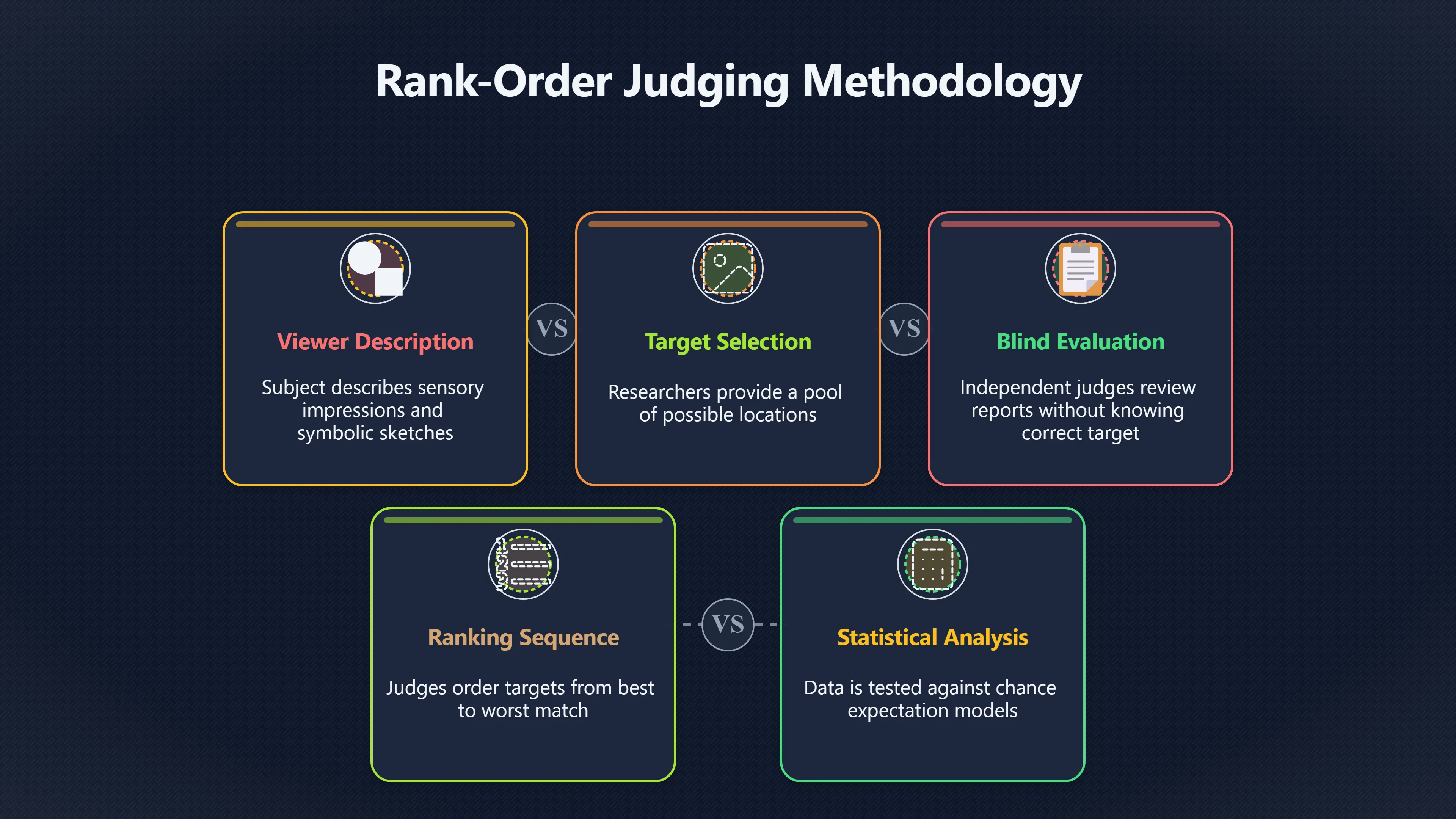
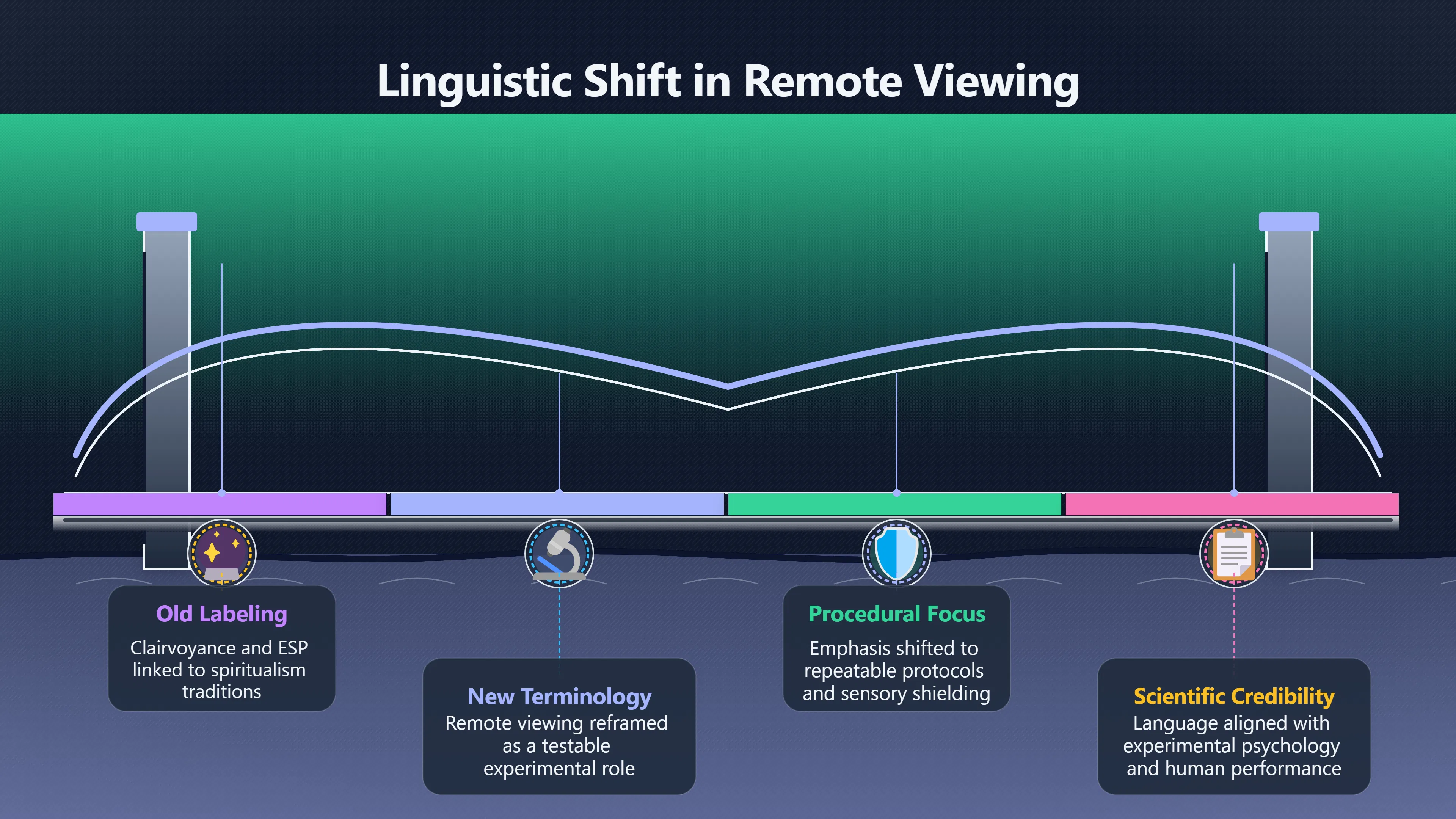
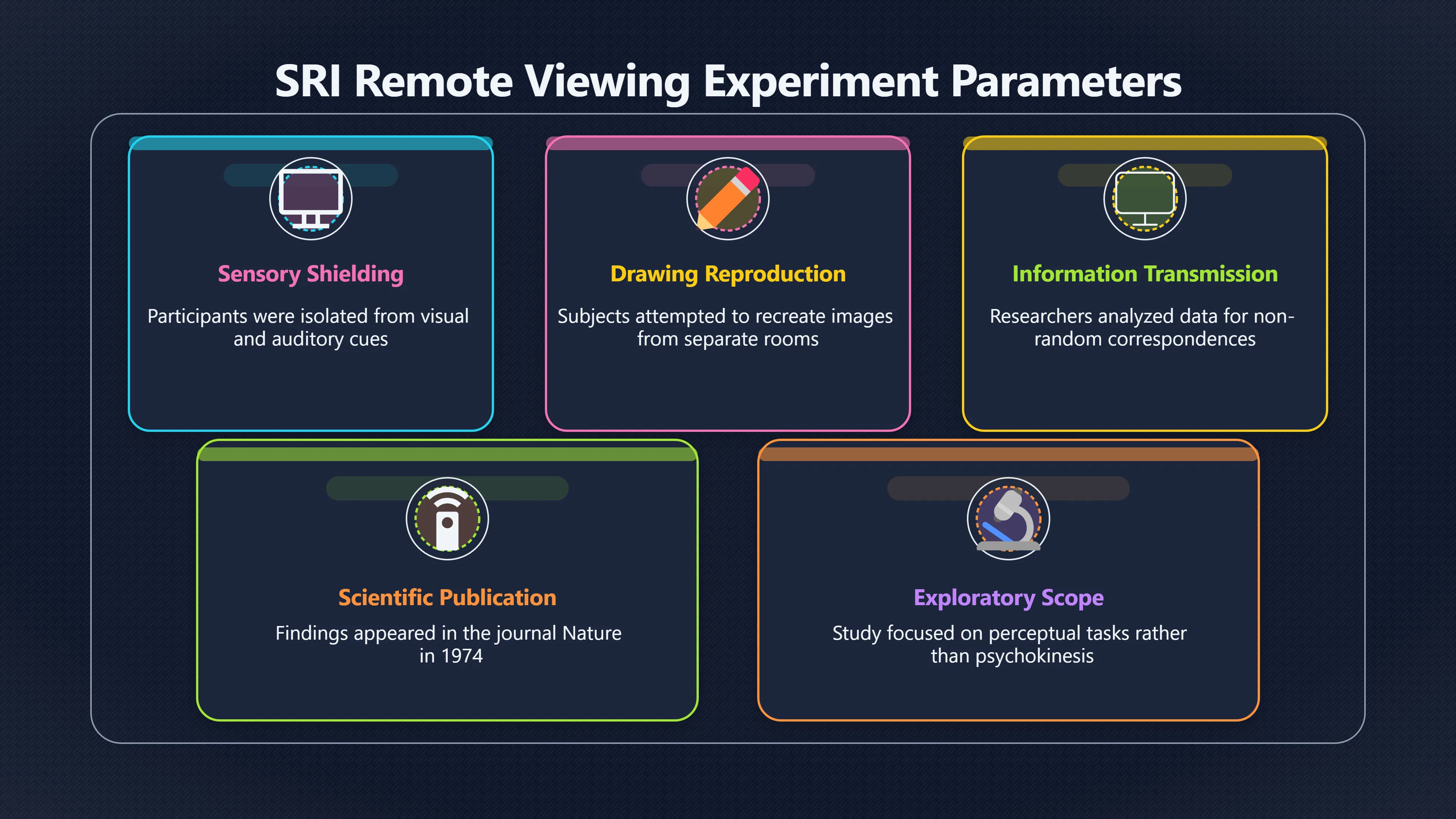
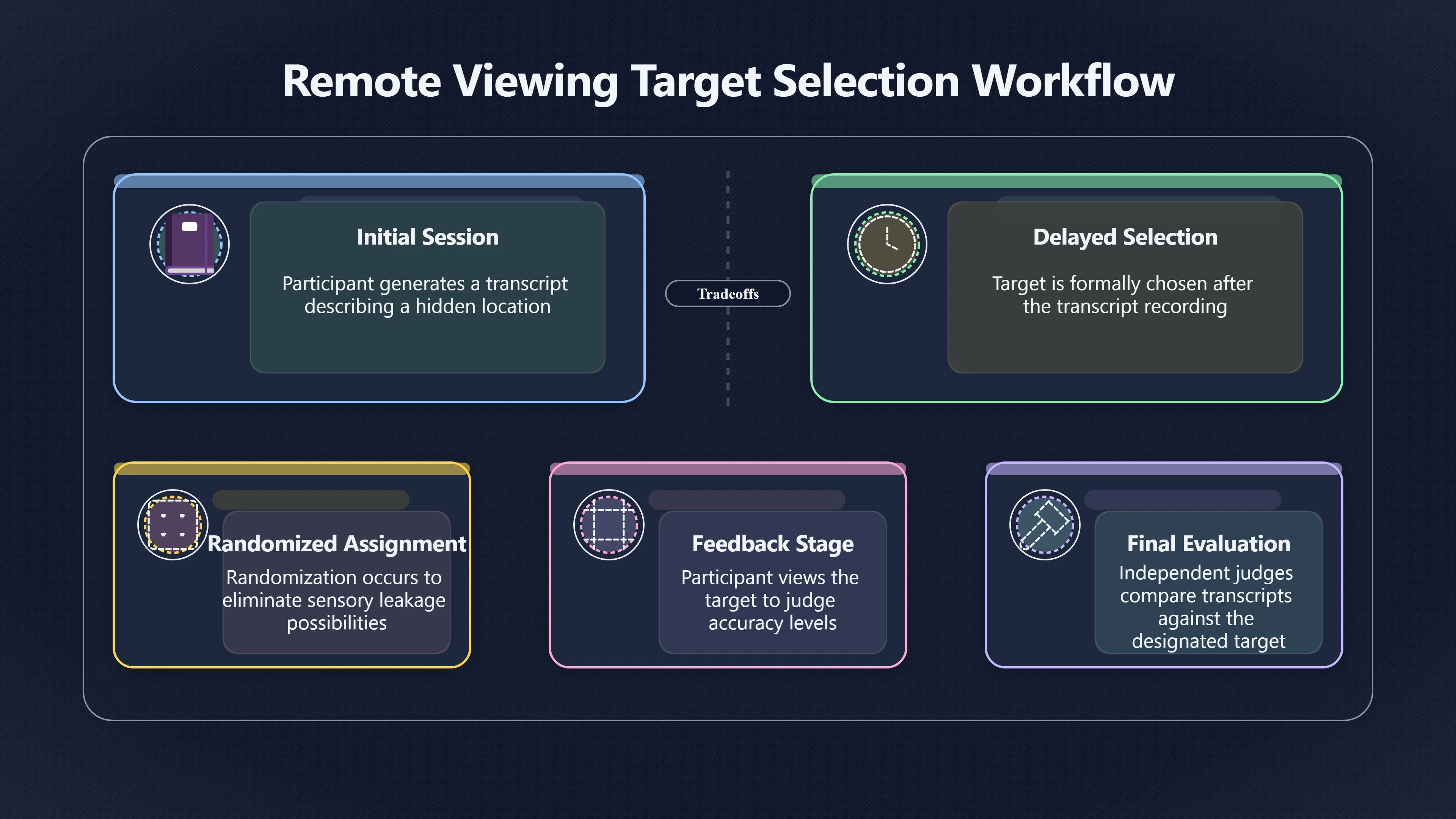
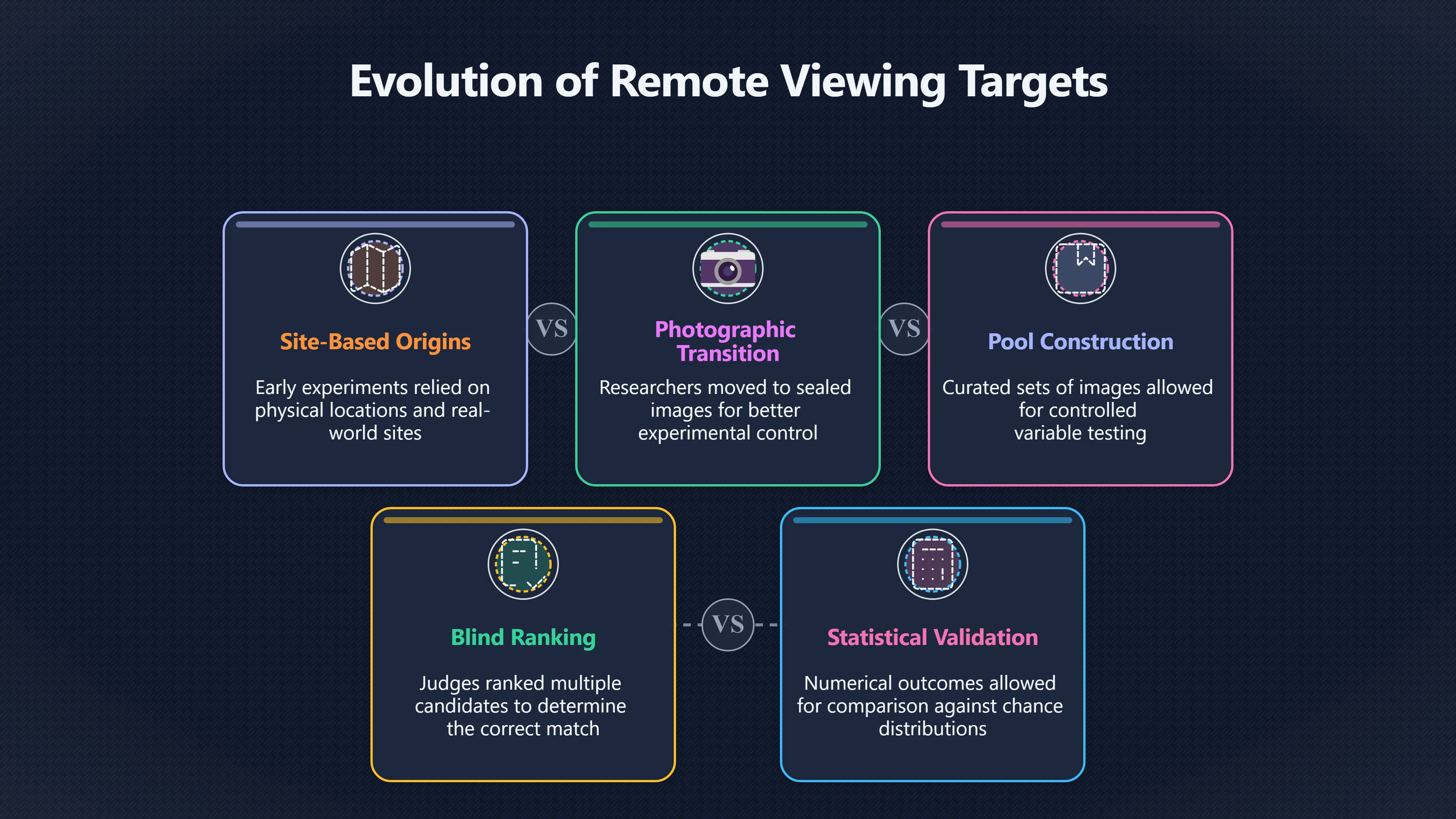
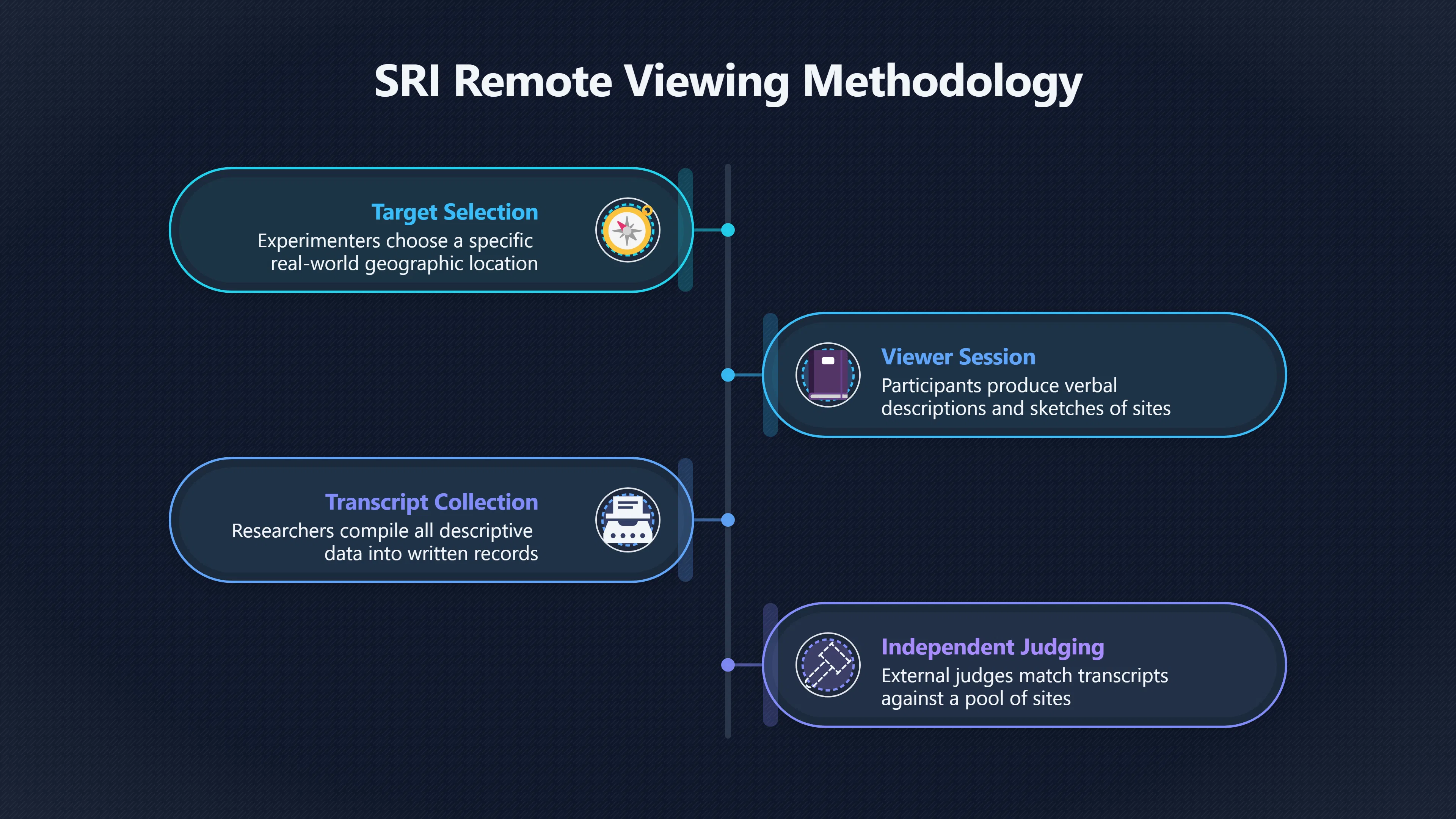
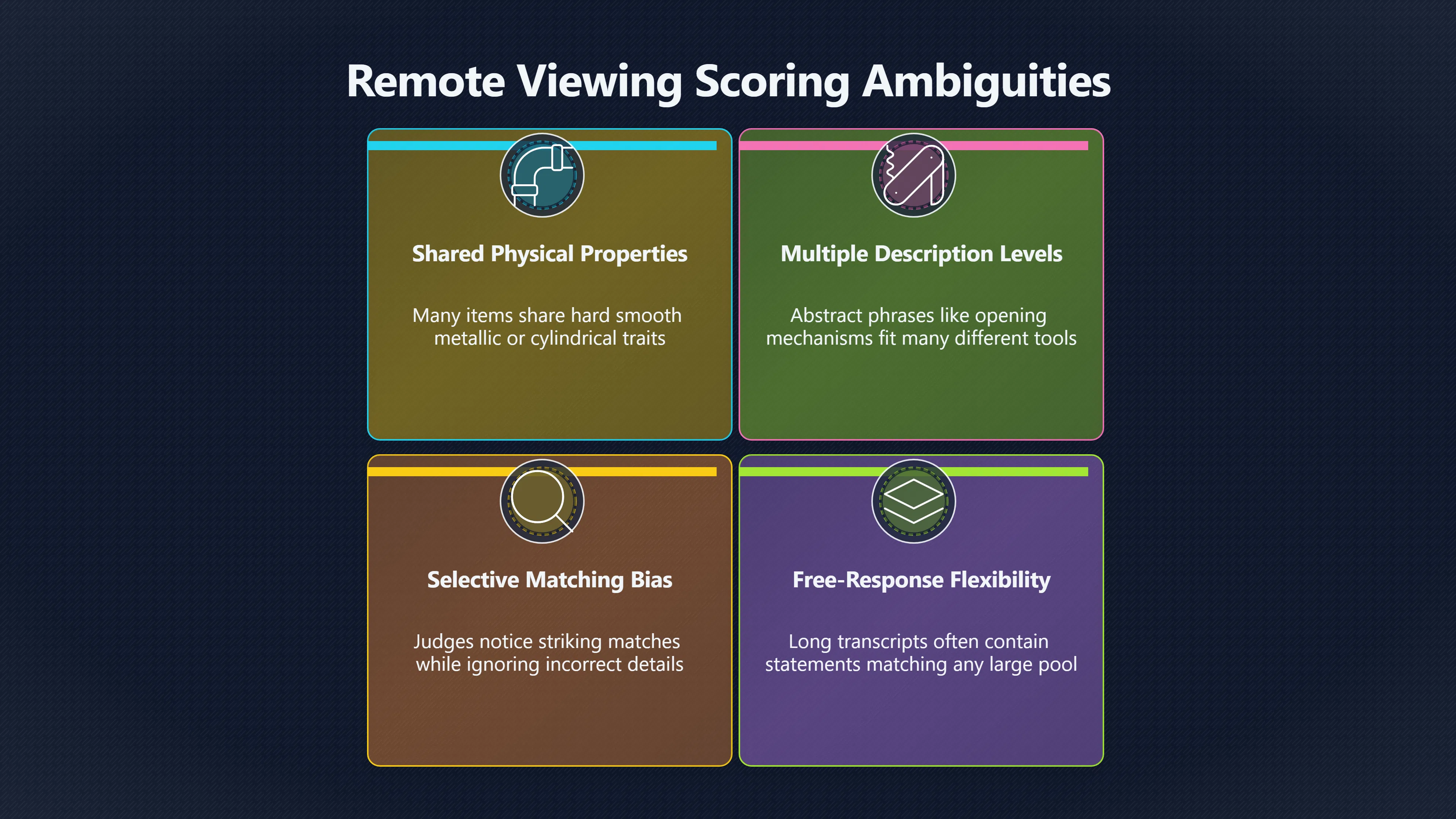
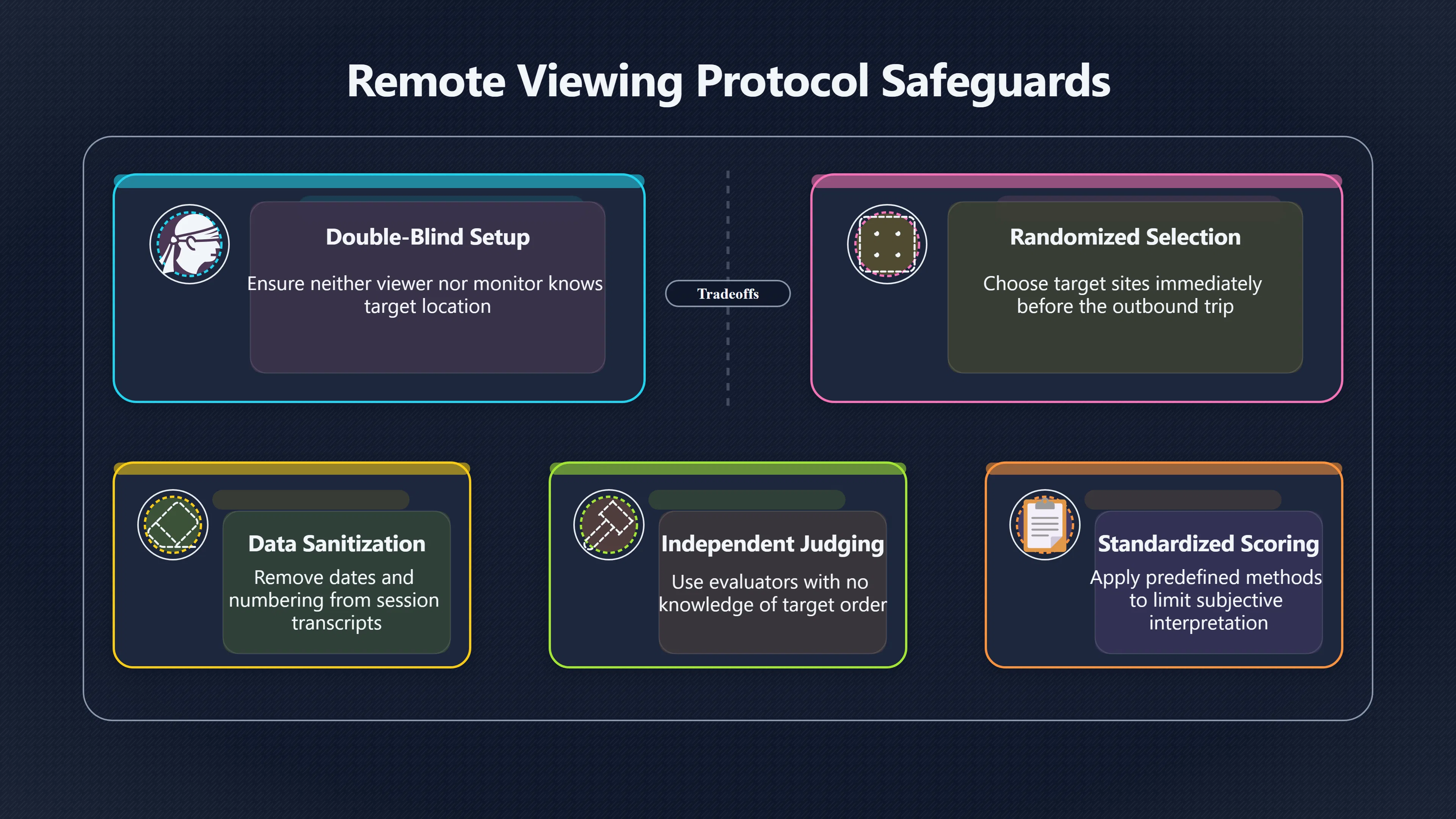
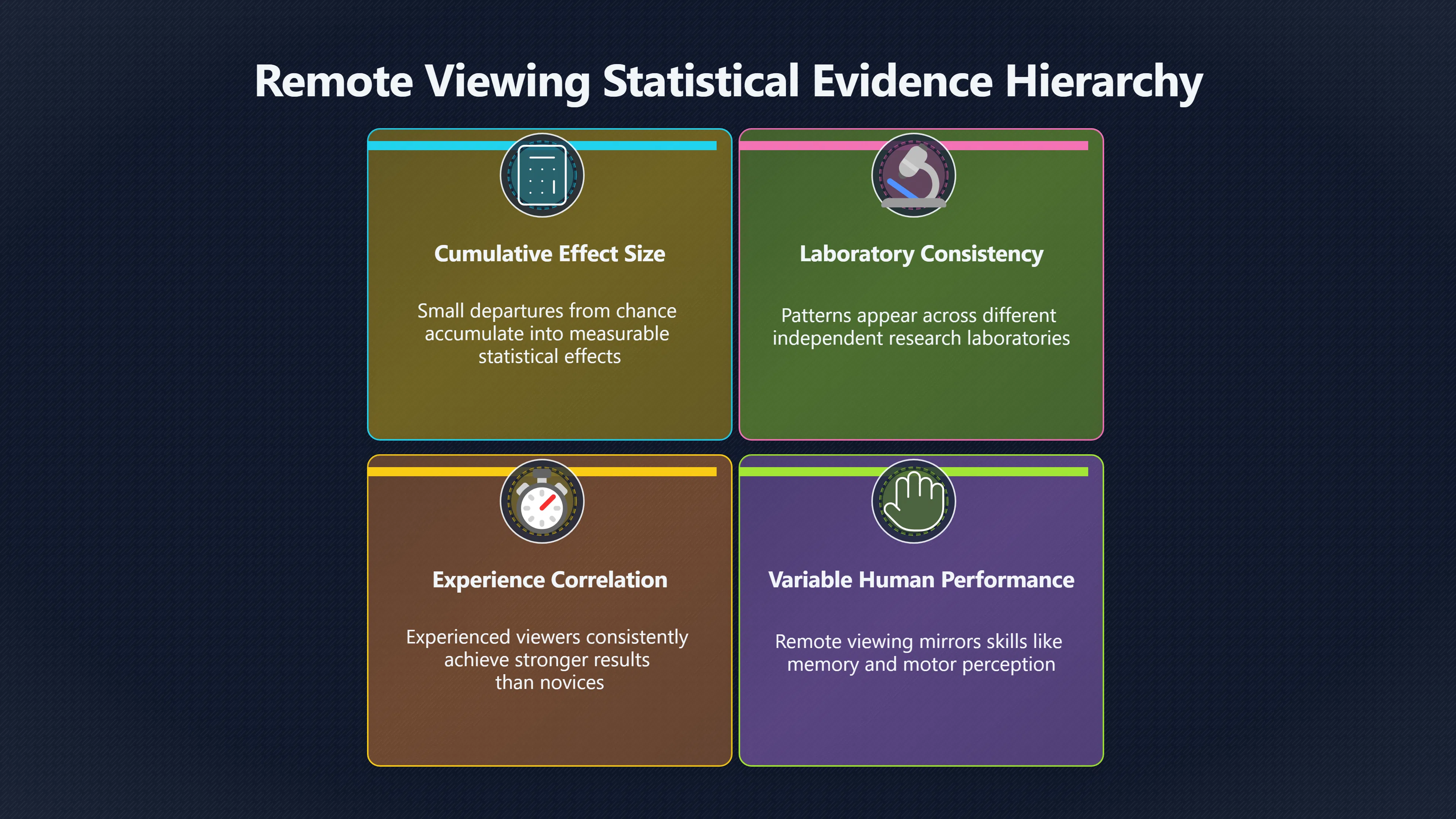
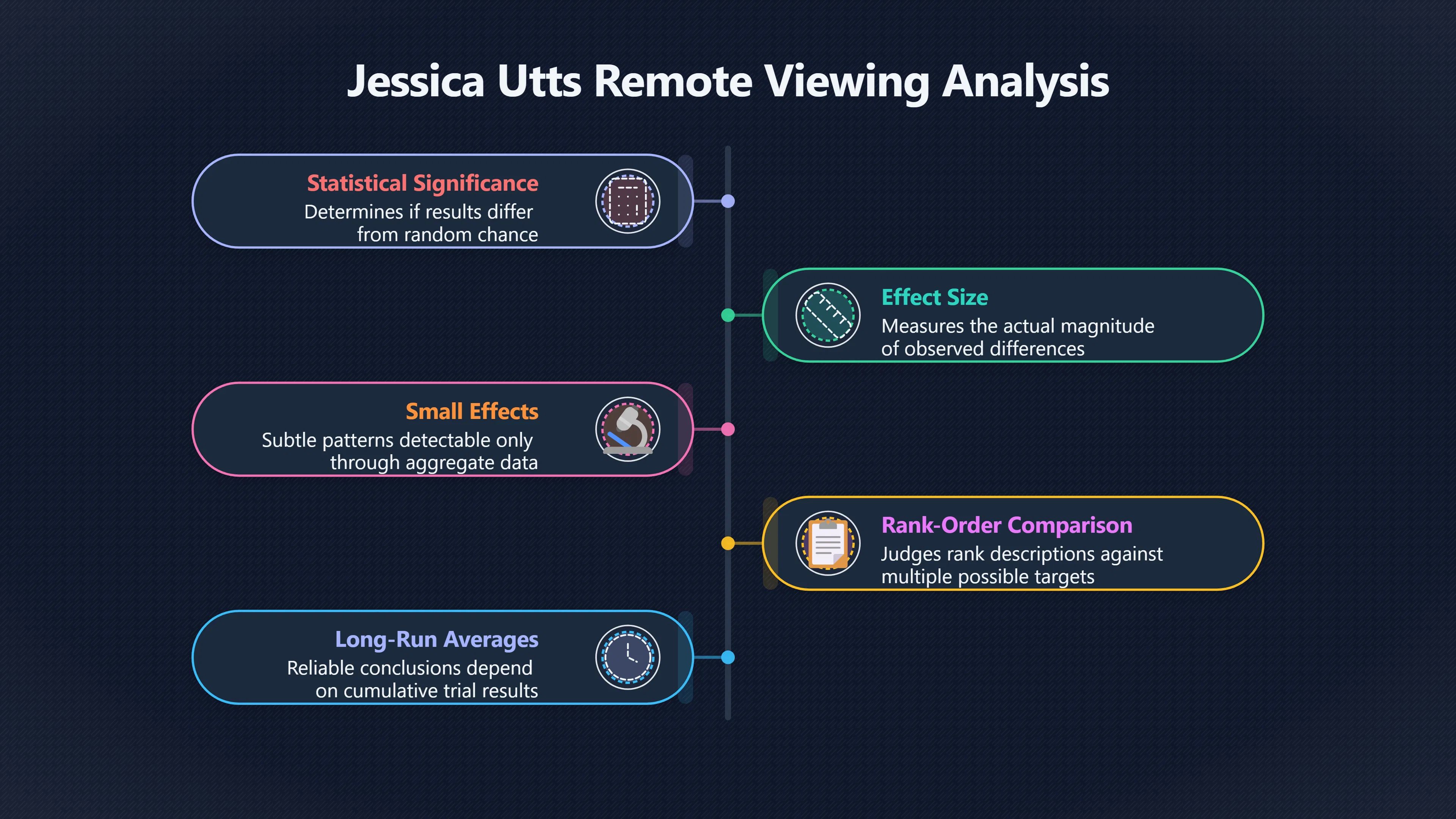
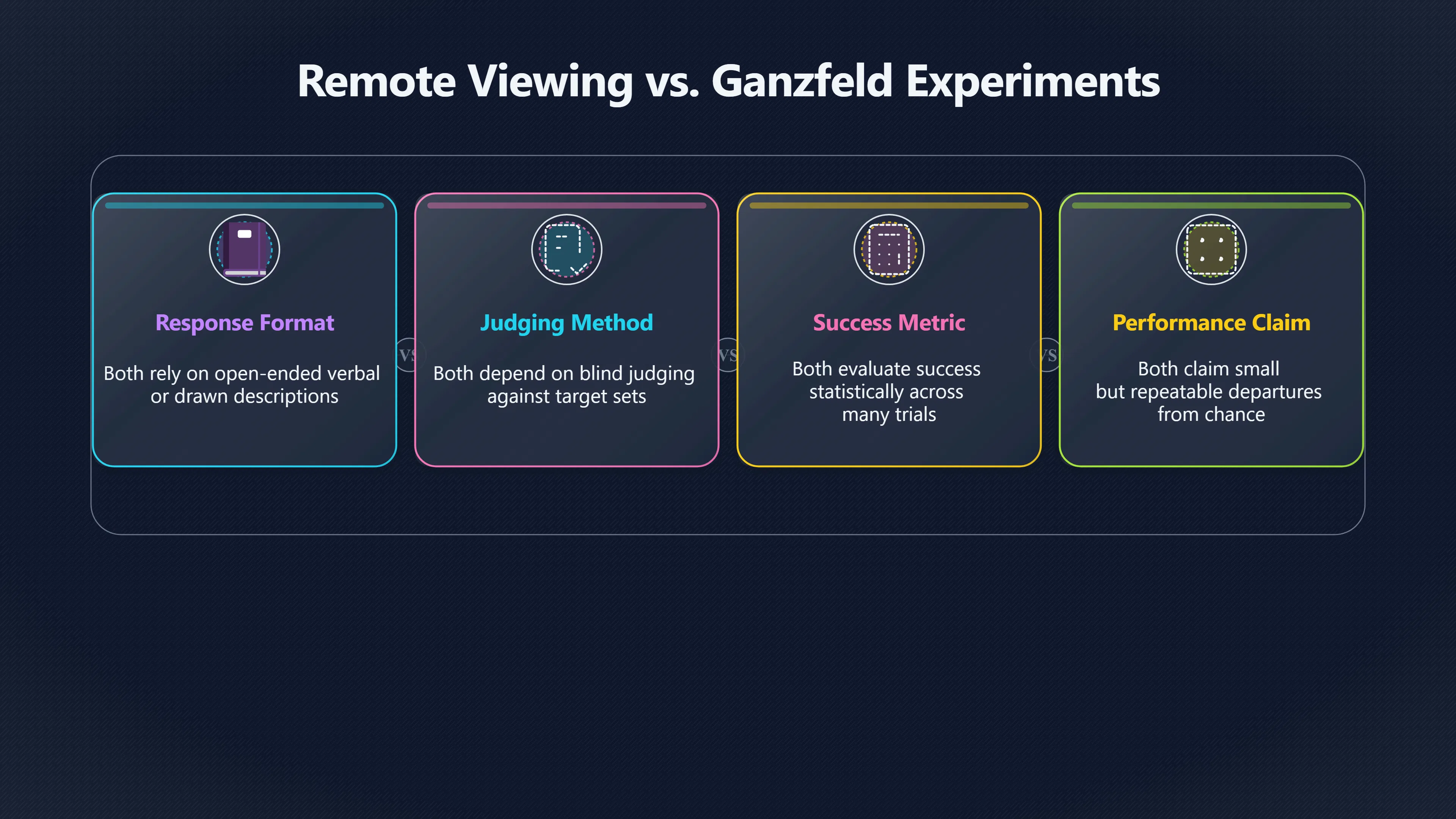
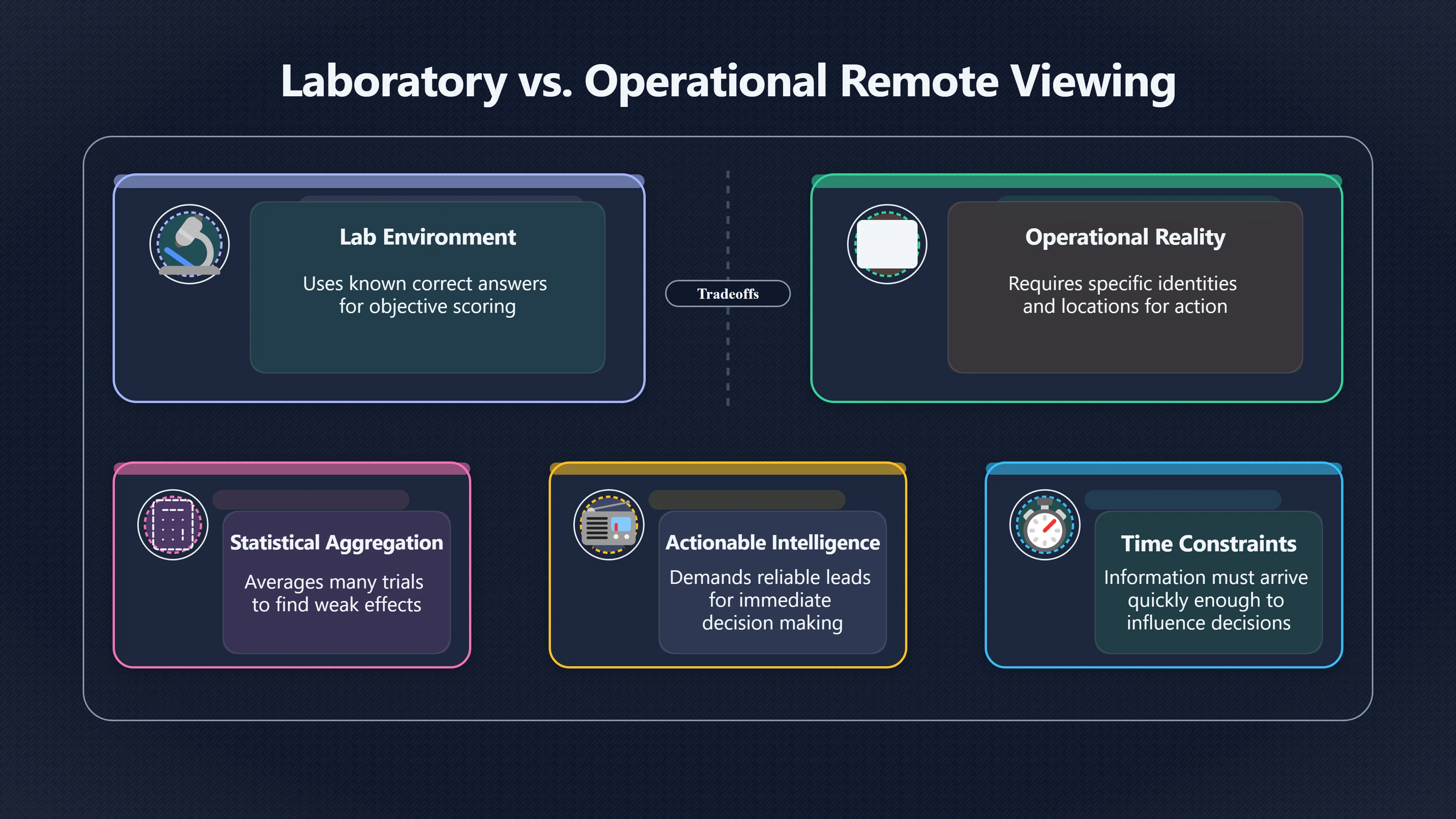
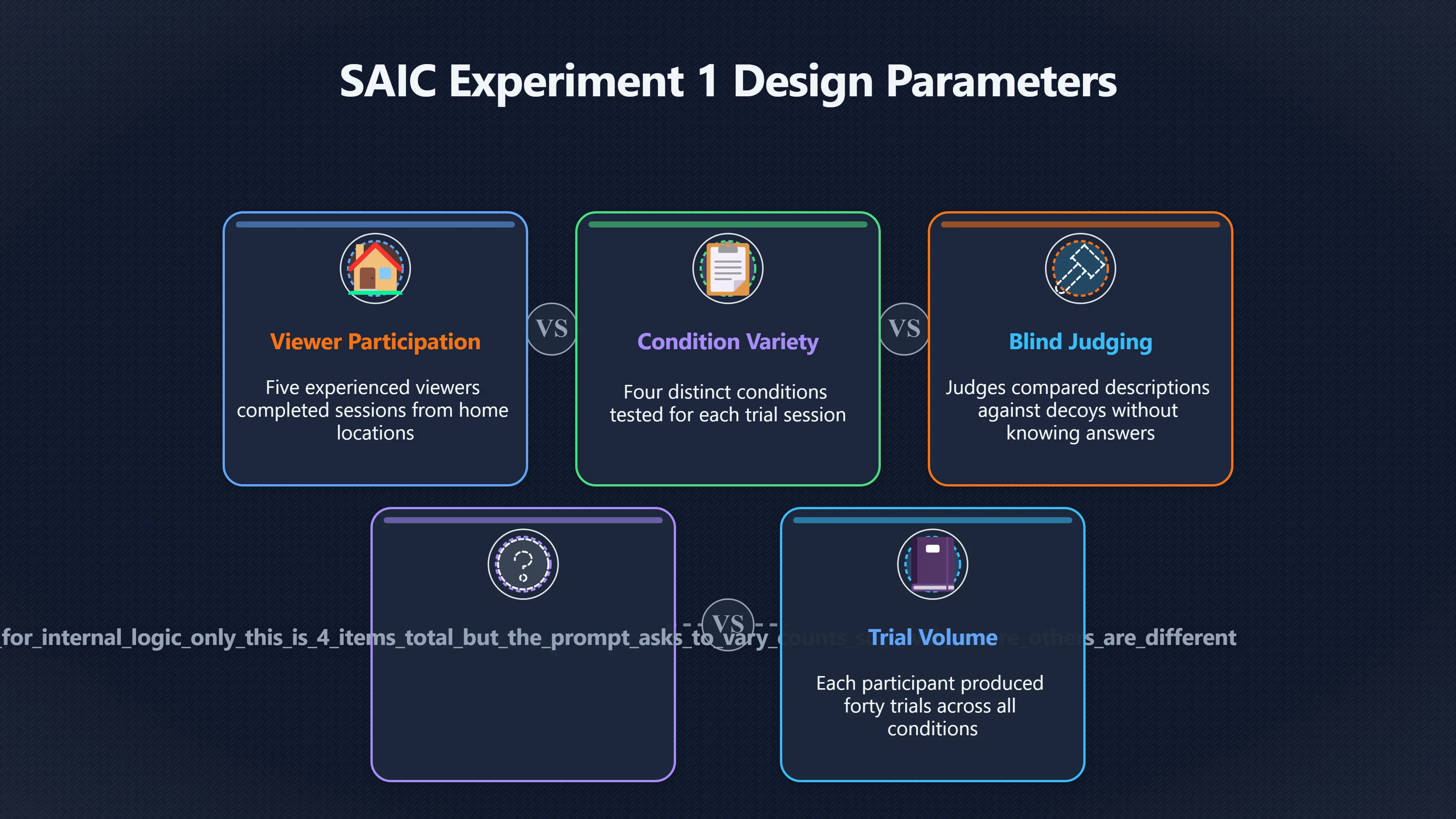
Expand all Collapse all Remote Viewing Did Psychic Spying Ever Really Work? Remote viewing is the claimed ability to describe a distant, hidden or future target without using the ordinary senses. 211 pages Read more 1995 Review What the Famous Review Really Said The 1995 review found disputed lab claims but no reliable intelligence value from operational remote viewing. 7 pages +Show subtopics Read more Utts Claim How a Positive Finding Still Lost Funding Utts judged the best experiments persuasive, but that favourable reading did not rescue remote viewing as a funded intelligence tool. Read more End Users What Did Intelligence Users Say Went Wrong? The operational review asked intelligence consumers whether remote-viewing reports helped them, not just whether sessions sounded interesting later. Read more AIR Review What Did the 1995 Review Actually Examine? AIR examined research claims, end-user feedback, interviews, and operational records rather than simply voting on whether remote viewing was real. Read more Lab vs Field Why Lab Hits Did Not Mean Spycraft Worked The 1995 review treated unusual lab scores and useful intelligence as separate claims, and that split changed the programme's fate. Read more Replication Why One Expert Still Said Not Proven Hyman did not deny unusual results, but he argued that replication, theory, and bias controls were still too weak for the strongest claim. Read more Actionability Why Vague Accuracy Was Not Enough A remote-viewing report could sound partly right yet still fail if it lacked the specific details needed for decisions. Read more Anecdotes Why the Best Stories May Not Be Evidence Striking remote viewing stories are memorable, but anecdotes rarely show how many misses and vague statements were ignored. 7 pages +Show subtopics Read more Blind Judges Could a Stranger Pick the Target? A transcript that convinces someone who knows the target may fail when a blind judge must identify the target without hints. Read more Semipalatinsk The Hit That Hid the Misses The famous Soviet-site story shows how a striking detail can survive in memory while incorrect or unevaluable material fades. Read more Hidden Misses What Remote Viewing Stories Leave Out A dramatic hit is hard to judge unless the failed, vague, unusable, and uncheckable sessions are counted too. Read more Lab vs Ops When Lab Results Meet Real Targets Statistical anomalies in controlled experiments did not translate into dependable intelligence for open-ended real-world targets. Read more Water Cue Why One Vague Detail Can Feel Exact Broad sensory phrases can feel accurate after feedback because many real-world targets contain some plausible version of the cue. Read more Story Bias Why the Story Wins First Remote-viewing stories feel human, vivid, and easy to imagine, while statistical reviews require slower thinking about chance and controls. Read more CIA Myths What the CIA Files Do Not Prove Declassified files prove government interest, not that the CIA confirmed psychic spying worked. 7 pages +Show subtopics Read more Ark Claims Did a CIA File Really Confirm the Ark? A remote-viewing description of a hidden relic is not proof of the Ark unless the object is found and independently examined. Read more CREST Spread How CREST Turned Archive Pages Viral Putting millions of scanned records online made remote-viewing files easier to find and easier to strip of context. Read more File Meaning What a Declassified CIA File Really Proves A released CIA file proves the record exists, not that the agency verified the claim inside it. Read more Geller Files What the Uri Geller Files Leave Unsettled The Uri Geller records preserve a controversy, not a settled verdict on psychic ability. Read more Final Review Why STAR GATE Failed the Intelligence Test The key question is not whether remote viewing was studied, but whether it produced intelligence people could use. Read more Mars Session Why the Mars File Cannot Prove Martian History The Mars session is fascinating as an archive item, but it shows why unverifiable targets make weak evidence. Read more Cold War The Cold War Fear Behind Remote Viewing Cold War fears about Soviet paranormal research helped turn an unlikely idea into a funded intelligence experiment. 7 pages +Show subtopics Read more Czech Trail The Czechoslovak Clue in Psychic Research Czechoslovak psychotronics gave U.S. Read more Race Myth Was There Really a Psychic Arms Race? The so-called psychic arms race was less a balanced contest than a feedback loop of suspicion, rumour and limited evidence. Read more Language Gap When Strange Words Became Intelligence Signals Different terminology made Soviet research hard to judge, turning words like psychoenergetics into intelligence problems as well as scientific ones. Read more Fear Logic Why Fear Can Fund Unlikely Experiments Remote viewing shows how Cold War agencies could fund unlikely tools when the cost of missing a surprise seemed higher than testing them. Read more Psychotronics Why Psychotronics Worried Western Analysts Cold War concern grew from Soviet-bloc psychotronics reports, even when the evidence was too uneven to prove a working psychic weapon. Read more Foreign Watch Why Watching the Soviets Changed the Test The foreign-assessment strand explains why remote viewing was funded as a possible intelligence gap rather than accepted science. Read more ESP Compare Is Remote Viewing Just ESP? Remote viewing is usually framed as a disciplined ESP task, but it overlaps with broader psychic claim traditions. 7 pages +Show subtopics Read more Psychic Spying How Psychic Spying Rebranded ESP The intelligence setting made remote viewing sound operational and modern while preserving older clairvoyant assumptions. Read more Not Psychic Is Remote Viewing Just Psychic Reading? Remote viewing differs from psychic reading by turning a broad ESP claim into a bounded target task with records and feedback. Read more Precognition When Remote Viewing Becomes Future Knowing Some remote-viewing designs drift into precognition when the target is selected or revealed only after the session. Read more ESP Types Which Kind of ESP Is Remote Viewing? Remote viewing can resemble clairvoyance, telepathy, or precognition depending on how the target is chosen and revealed. Read more Target IDs Why Did Remote Viewing Use Target Numbers? Target numbers and procedural language helped remote viewing seem less like fortune-telling and more like a controlled test. Read more Before Feedback Why Notes Before Feedback Matter So Much Remote-viewing records only become meaningful if impressions are fixed before the viewer learns the target. Read more Fair Test What a Strong Remote Viewing Test Needs A fair test needs random targets, proper blinding, stripped transcripts, pre-set scoring, and honest reporting of misses. 7 pages +Show subtopics Read more Clean Transcripts Can the Transcript Give the Game Away? The Marks critique shows why transcripts must be stripped of dates, order clues, file labels, and experimenter notes before judging. Read more Preregistration Lock the Rules Before the Reveal A preregistered protocol makes the scoring rule, stopping point, missing-data plan, and primary outcome visible before results are known. Read more Feedback Timing The Hidden Risk of Early Feedback Trial-by-trial feedback can echo into later responses, so fair tests must lock files and control judging order before revealing targets. Read more Target Pools When Random Targets Are Not Random Enough A target pool only protects the test when every option is fixed in advance, randomly selectable, and hidden from the session team. Read more Triple Blind Who Really Needs to Be Blind? A viewer can be blind while the test still leaks information through monitors, handlers, senders, timestamps, or logistics. Read more Rank Judging Why Decoys Matter More Than Hits Rank-order judging forces a response to beat decoys instead of letting a vague sketch become impressive after the answer is revealed. Read more Fort Meade Inside the Military Remote Viewing Unit Fort Meade gave remote viewing a military setting, but its operational reports still faced questions about usefulness. 7 pages +Show subtopics Read more Secrecy Did Secrecy Make Stargate More Convincing? Security controls made the program look serious, but secrecy also made later claims harder for outsiders to evaluate. Read more Tasking How Did a Psychic Spy Assignment Work? Operational remote viewing depended on targets, session reports, sketches, and customer feedback that rarely matched normal intelligence needs. Read more Detachment G What Was Detachment G Really Built To Do? The Fort Meade viewers were organized as a small intelligence detachment, not a loose group of private psychics. Read more Viewers Who Were the Military Viewers? Names like Joseph McMoneagle became famous, but the unit also depended on monitors, analysts, trainers, and managers. Read more Code Names Why Did Stargate Have So Many Names? GRILL FLAME, CENTER LANE, SUN STREAK, and STAR GATE were linked stages of a shifting government experiment. Read more Usefulness Why Striking Impressions Still Failed Analysts Fort Meade reports could sound suggestive after the fact, but evaluators found them too broad and ambiguous for action. Read more Future Targets Can Remote Viewing Claim the Future? Some remote viewing tests used future-selected targets, raising harder questions about chance, timing, and interpretation. 7 pages +Show subtopics Read more Timing Test Can a Future Target Anchor an Earlier Session? Future-selected targets ask whether a later random choice can match impressions recorded before the target existed. Read more CIA Protocols Inside the CIA Records on Future Targets Declassified records show how government-linked experiments separated viewing, target choice, and beacon activity in time. Read more Chicago Trial What the Chicago Precognition Trial Really Tested The Chicago-area study is a key early case because viewers described sites before the locations were chosen. Read more Rater Reliability When Blind Judges Do Not Agree Rater disagreement is a central weakness because the same transcript can lead blind judges to different predictions. Read more Associative Remote Viewing (ARV) Why Future Predictions Become Image Matches Associative remote viewing turns abstract future outcomes into image choices, but the prediction depends on the match. Read more Selective Hits Why Winning Streaks Can Mislead Runs of apparent hits can look persuasive when misses, stopping rules, and failed forecasts are not handled openly. Read more Hits Why Remote Viewing Hits Can Mislead Human pattern-seeking can make words like water, metal, or movement fit many different targets after feedback. 7 pages +Show subtopics Read more Blind Judging Can Blind Judges Separate Hits From Hindsight? Blind judging and decoys test whether a transcript fits the real target better than plausible alternatives. Read more After Fit How Target Photos Create After the Fact Hits A target image can teach viewers how to reinterpret earlier words, turning ordinary pattern-seeking into apparent recognition. Read more Barnum Hits The Psychology Behind Flexible Remote Viewing Hits Subjective validation explains why broad statements can feel personally or visually accurate when a context invites matching. Read more Sensory Cues When Ordinary Clues Create Psychic Looking Hits Ordinary clues in transcripts, order or handling can make a match look paranormal when the judging process has leaked information. Read more Counting Misses Why Misses Matter as Much as Hits A fair score must keep the misses visible, not retell the session around the few details that seem to fit. Read more Vague Hits Why Vague Impressions Can Feel So Accurate Broad words like water, metal, cold or movement can feel impressive after feedback because many targets can absorb them. Read more Hyman Review Why Unusual Results Were Not Enough Ray Hyman argued that unusual statistics were not enough without strong independent replication and better controls. 7 pages +Show subtopics Read more Single Judge Could One Judge Make the Effect Look Real? The use of one embedded judge made it hard to know whether the matches would survive outside the original research culture. Read more Rejudging The First Test Hyman Wanted Run Again Hyman's most practical demand was simple: let outsiders rejudge the same materials blind and see whether the effect remains. Read more Experiment One The SAIC Study That Looked Stronger on Paper A later reanalysis showed how missing protocol details could reopen ordinary explanations even in a respected SAIC study. Read more Replication What Would Count as Real Replication? For Hyman, real replication meant changing the lab, judges, targets, procedures, and viewer pool without losing the effect. Read more Monomethod Bias When One Method Can Fool a Whole Program Hyman worried that repeated success inside one tightly connected setup could reflect the method rather than the claimed ability. Read more Stats Doubt Why Above Chance Did Not Prove Remote Viewing Low probability scores made the SAIC results interesting, but Hyman argued they still did not identify remote viewing as the cause. Read more Intel Value Why Vague Hits Failed Intelligence Work Remote viewing impressions may sound intriguing after the fact, but intelligence work needs timely, specific, usable information. 7 pages +Show subtopics Read more Background Leakage Did Background Clues Create Better Hits? Some impressive results became less convincing when viewers may have had target context that ordinary analysts already knew. Read more Blind Alleys How Bad Clues Could Waste Real Resources A report mixing possible clues with errors could waste resources by sending analysts toward misleading leads. Read more Conflicting Reports What If the Psychic Sources Disagreed? When different viewers produced inconsistent reports, officials had no dependable rule for deciding which claims to trust. Read more Actionable Info When Psychic Impressions Failed the Action Test Remote viewing often produced intriguing descriptions, but intelligence value depended on whether they could change a real decision. Read more Lab to Field Why Lab Hits Did Not Become Field Value Controlled experiments could score statistical anomalies, but field operations needed specific claims under messy conditions. Read more Vague Matches Why Vague Hits Look Better in Hindsight Broad terms like water, metal, or movement could seem meaningful later while giving analysts little guidance beforehand. Read more Judging Why Scoring Remote Viewing Is So Hard Judging is where remote viewing claims often rise or fall because loose matching can make vague descriptions seem accurate. 7 pages +Show subtopics Read more Photo Bias Can One Photo Steal the Signal? In associative remote viewing, a striking feedback image can pull attention away from the intended target pairing. Read more Decoy Photos The Hidden Power of the Wrong Photos A remote-viewing result can look stronger or weaker depending on whether the decoys are too easy, too similar, or unevenly dramatic. Read more Rank Order Judging When a First Place Match Is Not Enough Rank-order judging turns vague impressions into numbers, but small design choices can change what looks like a hit. Read more AIR Review When Analysts Had to Find the Target The CIA-commissioned AIR review found that operational remote-viewing reports often left analysts sorting vague, inconsistent, and erroneous claims. Read more Hindsight Why Matches Look Better After Reveal Once the correct target is revealed, ordinary attention can turn loose phrases and rough sketches into persuasive-looking matches. Read more Long Reports Why Rich Impressions Are So Easy to Match Long free-response reports can contain enough mixed imagery for later readers to notice hits while overlooking misses. Read more Lab vs Real Why Lab Signals May Not Become Useful Even a true laboratory anomaly would still need to become accurate, timely, and specific enough for practical decisions. 7 pages +Show subtopics Read more Photo Targets Photo Matching Is Not Field Accuracy Rank-order judging can test whether a transcript resembles a target, but real users need coordinates, identities, timings, or verifiable claims. Read more Feedback Gaps The Problem With No Feedback Without timely feedback, viewers and users struggle to learn which impressions were useful and which were noise. Read more AIR Warning What the Official Review Warned About The official evaluation found that statistical effects did not translate into reliable intelligence value for end users. Read more Lab Hits When a Lab Hit Is Not Useful A laboratory hit can look impressive while still failing to answer the concrete question a real user needs solved. Read more Bad Leads When Correct Details Still Mislead A transcript can contain true details and still mislead users when accurate fragments are mixed with errors and generalities. Read more Open Targets Why Open Targets Are So Hard Real targets create a huge answer space where vague impressions rarely narrow the field enough to reduce uncertainty. Read more Leakage How Ordinary Clues Can Mimic Psychic Hits Small ordinary cues can make remote viewing results look better than they are unless experiments are tightly controlled. 7 pages +Show subtopics Read more Monitor Prompts Can the Monitor Accidentally Lead the Viewer? Even a well-meaning interviewer can shape a viewer's impressions if prompts, tone or expectations leak target hints. Read more Target Odds How One Clue Can Shift the Odds When targets are not reused, one ordinary clue can help eliminate options and inflate remote-viewing scores. Read more Marks Critique The Critique That Changed Remote Viewing The Marks and Kammann challenge made sensory cueing a central dispute in the legacy of early SRI remote-viewing tests. Read more Feedback Risk When Feedback Contaminates the Next Session Feedback can train viewers, but poorly timed feedback can also contaminate later trials and transcripts. Read more Transcript Clues When Transcripts Give the Game Away Small details in remote-viewing transcripts can turn blind judging into an order-matching puzzle rather than a psi test. Read more AIR Warnings Why Vague Reports Were Easy to Fit The CIA-sponsored AIR review showed why vague remote-viewing reports were especially vulnerable to analyst fitting and context leakage. Read more Marks Critique The Critique That Shook the Early Claims Marks and Kammann challenged the early SRI findings by pointing to possible cues in the judging materials. 7 pages +Show subtopics Read more Transcript Clues Could Paperwork Explain the Hits? Small details in remote-viewing transcripts could let judges match sessions to targets without any paranormal information. Read more Nature Debate The Journal Fight Over Cues The remote-viewing dispute played out across Nature replies and rebuttals that kept returning to ordinary sensory cues. Read more Blind Judging Were the Judges Really Blind? The Marks and Kammann critique turned on whether judges were truly blind to session order, target history, and procedural hints. Read more Better Controls What a Cleaner Test Would Require After the cueing dispute, stronger remote-viewing tests had to document random targets, cue-stripped transcripts, blind judging, and full reporting. Read more Failed Duplication Why Replication Changed the Argument Their 1978 Nature letter mattered because it reported duplicate experiments that did not verify Targ and Puthoff's conclusions. Read more Flexible Match Why Vague Impressions Can Look Striking Open-ended impressions such as water, structures, or circular shapes could seem meaningful when judges interpreted them broadly. Read more Meaning What Remote Viewing Actually Claims Remote viewing has a specific research meaning that is narrower than imagination, intuition, or mystical vision. 7 pages +Show subtopics Read more Leakage Risks How Remote Viewing Tests Can Go Wrong A monitor can help structure a session, but poor handling can accidentally cue the viewer and weaken the result. Read more Not Clairvoyance Is Remote Viewing Really Seeing? The research claim is usually about information acquisition without ordinary access, not literal sight through walls. Read more Session Notes What Remote Viewers Actually Record Remote-viewing sessions usually produce sketches, textures, shapes, moods, and partial impressions rather than clear pictures. Read more Star Gate What Star Gate Changed About Remote Viewing Government remote-viewing records shaped the term, but they also show why the evidence remains contested. Read more Blind Judging When Is It More Than Guessing? Blind judging is meant to show whether a recorded response fits the real target better than plausible decoys. Read more Hidden Targets Why Remote Viewing Needs a Hidden Target A hidden target is what turns a private impression into a claim that can be tested, scored, and challenged. Read more Middle View What a Balanced View Actually Says The most accurate view is neither simple debunking nor proof, but a split between disputed effects and failed application. 7 pages +Show subtopics Read more Secrecy Cost Did Secrecy Hurt the Science? Classified research made remote viewing harder to scrutinize, replicate, and evaluate through normal scientific channels. Read more AIR Verdict The Review That Split the Debate The 1995 review found a possible laboratory anomaly but rejected remote viewing as useful intelligence work. Read more Statistical Hits When Does a Hit Become Proof? Above-chance results can be intriguing without proving that information travelled by paranormal means. Read more Actionable Intelligence Why Psychic Spying Failed End Users Remote viewing failed most sharply when vague laboratory-style impressions had to become timely, actionable intelligence. Read more Meta Analyses Why the Debate Keeps Coming Back Recent reviews keep the debate alive by aggregating positive studies while leaving doubts about bias and replication unresolved. Read more Vague Matches Why Vague Impressions Can Feel Accurate Remote-viewing claims often depend on matching fragmentary descriptions to targets after the session ends. Read more Pop Culture Why Remote Viewing Became a Modern Myth Books, documentaries, and online communities turned a disputed research program into a lasting cultural mystery. 7 pages +Show subtopics Read more Target Pools Can Online Targets Really Test Viewers? Practice target pools make remote viewing feel repeatable, but they also raise questions about loose matching and selective memory. Read more Goats Story How Goats Turned Psychic Spies Mainstream Jon Ronson's book and the later film made psychic spying memorable by mixing real military curiosity with satire and exaggeration. Read more Viewer Legends How Psychic Spies Became Characters Memoirs and insider histories gave remote viewing recognizable characters, origin stories, and repeatable success narratives. Read more Third Eye Spies When Remote Viewing Becomes Insider History Third Eye Spies shows how advocate documentaries frame remote viewing as hidden Cold War history and human potential. Read more CIA Files Why CIA Files Made the Myth Stick Declassified Stargate records gave remote viewing a documentary aura even when the practical intelligence value stayed disputed. Read more Reddit Practice Why People Still Try It Online Online communities turned remote viewing from a Cold War story into a hobby people can test, share, and argue about. Read more Protocol How a Remote Viewing Session Is Supposed to Work A basic remote viewing protocol records impressions before feedback and tries to block normal sources of information. 7 pages +Show subtopics Read more Target Pools Can a Target Number Leak the Answer? A neutral target number only works when the image pool is random, hidden and protected from accidental clues. Read more First Session How to Run a Clean First Session A simple two-person session can test the basic rules without turning a beginner exercise into a dramatic proof claim. Read more Clean Feedback The Moment Beginners Most Often Fool Themselves Feedback helps learning only when the blind record is finished, saved and kept separate from later interpretation. Read more Monitor Cues When Helping Becomes Hinting A monitor can help a beginner stay engaged, but leading questions and subtle reactions can quietly contaminate the session. Read more Raw Notes Why First Impressions Beat Clever Guesses Separating textures, shapes and sensations from named guesses makes a session easier to judge and harder to retrofit. Read more Decoy Judging Would Your Notes Fit Other Targets Too? Comparing notes with decoys shows whether a response really fits the target better than several plausible alternatives. Read more Read Files How to Read Remote Viewing Files Carefully Declassified remote viewing files are fascinating, but readers need to separate raw records from validated conclusions. 7 pages +Show subtopics Read more Declassification Released Is Not the Same as Proven A released CIA file shows that a record existed in the archive, not that the agency accepted the claim inside it as true. Read more Tasking Clues Was the Target Really Hidden? Tasking details can reveal whether a viewer was truly blind or whether ordinary clues may have shaped the session. Read more Transcripts What a Session Transcript Really Shows A remote viewing transcript can prove a session was recorded, but not that its impressions were accurate, paranormal or useful. Read more Checkable Claims Which Details Can Actually Be Checked? The safest reading method separates vague impressions from details that can be independently checked against the target. Read more Scoring Who Decided It Was a Match? A claimed match may come from ranked comparison, blind judging or subjective interpretation rather than a simple right-or-wrong score. Read more AIR Review Why the AIR Review Still Matters The AIR review helps readers distinguish statistical findings, expert disagreement and operational usefulness in the Star Gate record. Read more Replication Why Mainstream Science Remains Unconvinced Remote viewing remains outside mainstream science because strong independent replication has not become widely accepted. 7 pages +Show subtopics Read more Meta Analysis Can Pooled Results Prove the Effect? Meta-analyses can suggest a real anomaly, but they also raise questions about small studies, missing nulls and inconsistent methods. Read more Misses Count What Happens to the Failed Sessions? Hits become more meaningful only when misses, ambiguous sessions and null results are preserved in the same public record. Read more Over Matching When Vague Hits Look Too Good Blind judging can still overstate success when vague impressions are matched too generously to a small set of possible targets. Read more Replication Gaps Why Does Remote Viewing Fail to Travel? Remote viewing has produced intriguing results, but repeatability falters when protocols, scoring and independent checks change across labs. Read more AIR Review Why Positive Numbers Were Not Enough The CIA-commissioned AIR review shows why positive statistics did not settle whether remote viewing had been demonstrated as paranormal. Read more Pre Declared Rules Why Rules Must Come Before Results Pre-registration matters because flexible target choices, scoring rules and analysis decisions can turn weak signals into impressive-looking results. Read more SAIC Tests The Later Tests Behind the 1995 Debate Later SAIC work kept the laboratory debate alive after the original SRI experiments became controversial. 7 pages +Show subtopics Read more Rank Judging Can Five Targets Make Psychic Claims Testable? The five-target judging system made chance expectations clear, but it also made the judge's role central to the SAIC debate. Read more Target Types Did Moving Targets Help or Hurt? SAIC's target-type results complicated the claim that remote viewing improves when targets are more vivid or moving. Read more Monomethod Bias When One Lab Setup Does Too Much Work The strongest SAIC results raised a hard question: did the effect come from remote viewing, or from a repeated experimental setup? Read more Experiment One Why Experiment One Became So Contested SAIC's first major test showed why cleaner statistics still depended on fragile practical controls around home sessions and response handling. Read more Independent Judges Why New Judges Mattered So Much AIR's review pushed the SAIC debate toward a practical test: whether the results would survive new judges and independent scoring. Read more Significance Gap Why Significant Results Still Fell Short Utts and Hyman agreed the SAIC data were statistically significant, but that agreement did not translate into accepted science or useful intelligence. Read more Shutdown Why Remote Viewing Lost Government Support The government ended remote viewing funding after evaluators found no documented intelligence value worth continuing. 7 pages +Show subtopics Read more Contamination Did Background Clues Make Hits Look Better? Some remote-viewing successes became less persuasive when later interpretation appeared to depend on known cues or outside context. Read more AIR Review The Review That Made Star Gate Hard to Defend The 1995 AIR assessment turned years of remote-viewing work into a cost-benefit question the programme could not answer. Read more Viewer Reliability When Multiple Viewers Did Not Agree The programme struggled because different viewers did not consistently converge on the same target details. Read more Actionable Intel Why 'Actionable Intelligence' Became the Deciding Test The programme ended because its reports did not give intelligence officers reliable information they could act on before answers were known. Read more Final Budget Why a Small Budget Still Needed Proof By 1995, Star Gate was a small contested Fort Meade operation whose remaining cost had to be justified under outside scrutiny. Read more Signal Noise Why Correct Details Still Were Not Enough Even when some details seemed right, analysts could not reliably separate useful signal from errors, guesses, and irrelevant material. Read more Sketches What Remote Viewing Sketches Can and Cannot Show Remote viewing responses mix words, drawings, and impressions, which makes interpretation both useful and risky. 7 pages +Show subtopics Read more Sketch Value Can Sketches Say More Than Words? Sketches can keep layout and geometry visible before a viewer turns a vague form into a misleading noun. Read more Photo Targets How Decoys Tested Remote Viewing Sketches Photo-target trials show how free-response sketches were compared against real targets and plausible decoys. Read more Rinconada The Pool Case That Cuts Both Ways Pat Price's pool-complex account shows why vivid correct-looking details and absent imagined features must be judged together. Read more Judging Rules When Does a Sketch Count as Evidence? A remote-viewing sketch only gains evidential force when judging rules limit clues, editing bias, and selective scoring. Read more Raw Notes Why First Impressions Can Beat Confident Labels Remote-viewing notes become more useful when sensory fragments are separated from confident labels that may be wrong. Read more Retrofit Risk Why One Circle Can Match Too Much A circle, tower, or cluster of lines can look persuasive only after the target is known, making judging controls essential. Read more SRI Tests The Experiments That Made Remote Viewing Famous The Stanford Research Institute experiments created the best-known remote viewing claims and many later disputes. 7 pages +Show subtopics Read more Cueing Dispute Could Hidden Clues Explain the Hits? The cueing dispute asked whether ordinary clues, not psychic perception, could explain the early SRI successes. Read more Pat Price Did Pat Price Really Match the Targets? Pat Price's famous SRI sessions looked impressive partly because matching transcripts to targets became the central battleground. Read more Local Targets How SRI Made Remote Viewing Testable The SRI local target setup made remote viewing look testable, repeatable, and vulnerable to protocol design choices. Read more URDF 3 The Soviet Crane Claim Behind the Legend The Soviet facility case became remote viewing folklore, but the declassified evaluations were far more cautious than the legend. Read more Jupiter Session What Did Ingo Swann Really Predict? Ingo Swann's Jupiter episode is memorable, but delayed planetary feedback made clean validation unusually difficult. Read more Nature Paper Why One Nature Paper Changed Remote Viewing The 1974 Nature paper turned remote viewing into a laboratory claim that supporters and critics still argue over. Read more Stargate Why the Government Tested Psychic Spying The Stargate program shows why U.S. 7 pages +Show subtopics Read more Expert Dispute Did the Evidence Prove Anything Paranormal? The 1995 review became famous because sympathetic and sceptical experts agreed on unusual results but disagreed on what they proved. Read more Lab Evidence What Did the Lab Tests Actually Show? The later review treated SAIC's documented experiments differently from earlier SRI work because methods and records mattered. Read more Cold War Bet Why Did Intelligence Agencies Take This Seriously? Cold War agencies funded remote viewing because even a small chance of success seemed worth testing against Soviet uncertainty. Read more Photo Targets Why Lab Success Was Hard to Use Matching hidden photographs in a lab was easier to score than answering messy real-world intelligence questions. Read more Vague Reports Why Psychic Spying Did Not Become Actionable Operational users found many remote-viewing reports too vague, mixed and interpretive to support confident intelligence decisions. Read more Code Names Why Stargate Was Not One Neat Programme The programme shifted across sponsors, contractors and labels, making its public history harder to follow than one project name suggests. Read more Statistics What Above Chance Results Really Mean Statistical significance can suggest an anomaly, but it does not automatically prove psychic ability or practical usefulness. 7 pages +Show subtopics Read more Actionable Info Can Remote Viewing Ever Be Actionable? For remote viewing to be useful, it must move beyond ranked targets and produce specific details people can verify and act on. Read more Replication What Would Count as Strong Replication? The Utts-Hyman dispute turns on what kind of independent replication would make remote-viewing evidence hard to dismiss. Read more Effect Size When a Small Effect Is Still Not Useful Small average effects can matter in statistics yet still fail when readers ask whether remote viewing works in real decisions. Read more P Values Why Better Than Chance Is Not Proof A statistically unusual remote-viewing result can flag an anomaly without proving a psychic mechanism or usable hidden information. Read more AIR Review Why the Government Still Walked Away The AIR evaluation treated laboratory statistics and intelligence usefulness as separate questions, with very different answers. Read more Matching Why Vague Hits Can Look Strong Free-form impressions can look convincing after the fact, but the matching process can change how strong a hit appears. Read more Targ Puthoff The Physicists Behind Remote Viewing's Rise Targ and Puthoff gave remote viewing its scientific public identity, but their claims remain heavily contested. 7 pages +Show subtopics Read more CIA Interest Did CIA Interest Prove Remote Viewing Worked? Government funding showed official curiosity about remote viewing, not proof that psychic spying worked. Read more Authority Problem Did Physics Credentials Make Remote Viewing Credible? Targ and Puthoff's technical backgrounds helped remote viewing sound scientific before its evidence was settled. Read more Mind Reach How Mind Reach Sold Remote Viewing to Readers Popular writing helped turn SRI experiments into a lasting story about hidden human perception. Read more Legacy Chain How SRI Became the Remote Viewing Origin Story Targ and Puthoff's early SRI work became the reference point for later military remote-viewing programs. Read more Viewer Language Why Calling Psychics 'Viewers' Changed the Story Replacing 'psychic' with 'viewer' made remote viewing feel like a testable skill rather than a rare gift. Read more Geller Testing Why Uri Geller Made SRI More Controversial Uri Geller's SRI sessions brought attention to Targ and Puthoff's work while sharpening criticism of their controls. Read more Targets What Remote Viewers Try to Describe Targets can be places, photos, objects, or future-selected images, and each target type creates different testing problems. 7 pages +Show subtopics Read more Future Targets Can a Target Be Chosen Later? Future-selected targets tested precognition claims, but feedback and decoy photos could create displacement disputes. Read more Photo Pools Did Photo Targets Make Results Cleaner? Photograph targets were easier to randomize and archive, but they pushed rich impressions into ranked image matching. Read more Hammid Clues The Target Clues Hidden in Transcripts The Hammid series became a key example of how transcript cues could make target matching look stronger than it was. Read more Pool Bandwidth When Target Pools Tilt the Test Target pools can bias results when some images are richer, more memorable, or easier to distinguish than others. Read more Object Targets Why Hidden Objects Were Not Simple Concealed objects looked simple as targets, but broad descriptions like hard, small, or metallic could fit too many items. Read more Real Sites Why Real Places Made Testing Harder Real places made remote-viewing sessions vivid, but travel logistics and paperwork could leak clues into judging. Read more Utts Review Why Some Statisticians Took Results Seriously Jessica Utts argued that laboratory results showed real statistical effects, even if practical use was unresolved. 7 pages +Show subtopics Read more Viewers Did Practice Make Remote Viewing Stronger? Utts highlighted stronger results from experienced viewers as one reason the database looked less random. Read more Effect Sizes How Small Effects Became a Big Argument Utts' case depended on repeated small shifts from chance, not dramatic hits in every session. Read more Significance When Significant Numbers Still Fall Short A significant result can flag an unusual pattern without proving that remote viewing caused it. Read more Ganzfeld Why Ganzfeld Studies Entered the Debate Utts used similarities with ganzfeld results to argue that the effect was not confined to one lab protocol. Read more Usefulness Why Lab Hits Did Not Become Intelligence The AIR evaluation separated laboratory scoring success from the much harder demand for useful intelligence. Read more Static Targets Why Photos Scored Better Than Videos One SAIC study reported stronger results for static images while dynamic video targets landed at chance. Read more Search pages Search topic, branch, or keyword... Scope 211 pages Search pages Clear