Within Statistics
Why Vague Hits Can Look Strong
Free-form impressions can look convincing after the fact, but the matching process can change how strong a hit appears.
On this page
- How free response judging works
- Where generous interpretation enters the score
- Safeguards that make matching harder to game
Page outline Jump by section
Introduction
One of the most persistent disputes in remote-viewing research is not only whether sessions produce information above chance, but how that information is judged. Unlike a multiple-choice test, remote-viewing sessions usually consist of sketches, sensory impressions, metaphors, colours, textures and fragments of description. Deciding whether such material “matches” a target inevitably requires interpretation. That makes the judging process a critical point in the debate over whether statistically significant results amount to convincing practical evidence.

Supporters argue that carefully designed free-response judging can detect genuine correspondences while avoiding the limitations of forced-choice tests. Critics counter that vague descriptions can often be made to fit many targets after the fact, allowing subjective interpretation to inflate apparent success. As a result, the strength of a remote-viewing claim depends not only on the viewing session itself but also on how the matching process is designed and controlled.[CIA+2UC Irvine Bren School]cia.govAN EVALUATION OF THE REMOTE VIEWING PROGRAMTypically, the remote viewers described the results of their experiences in written reports…
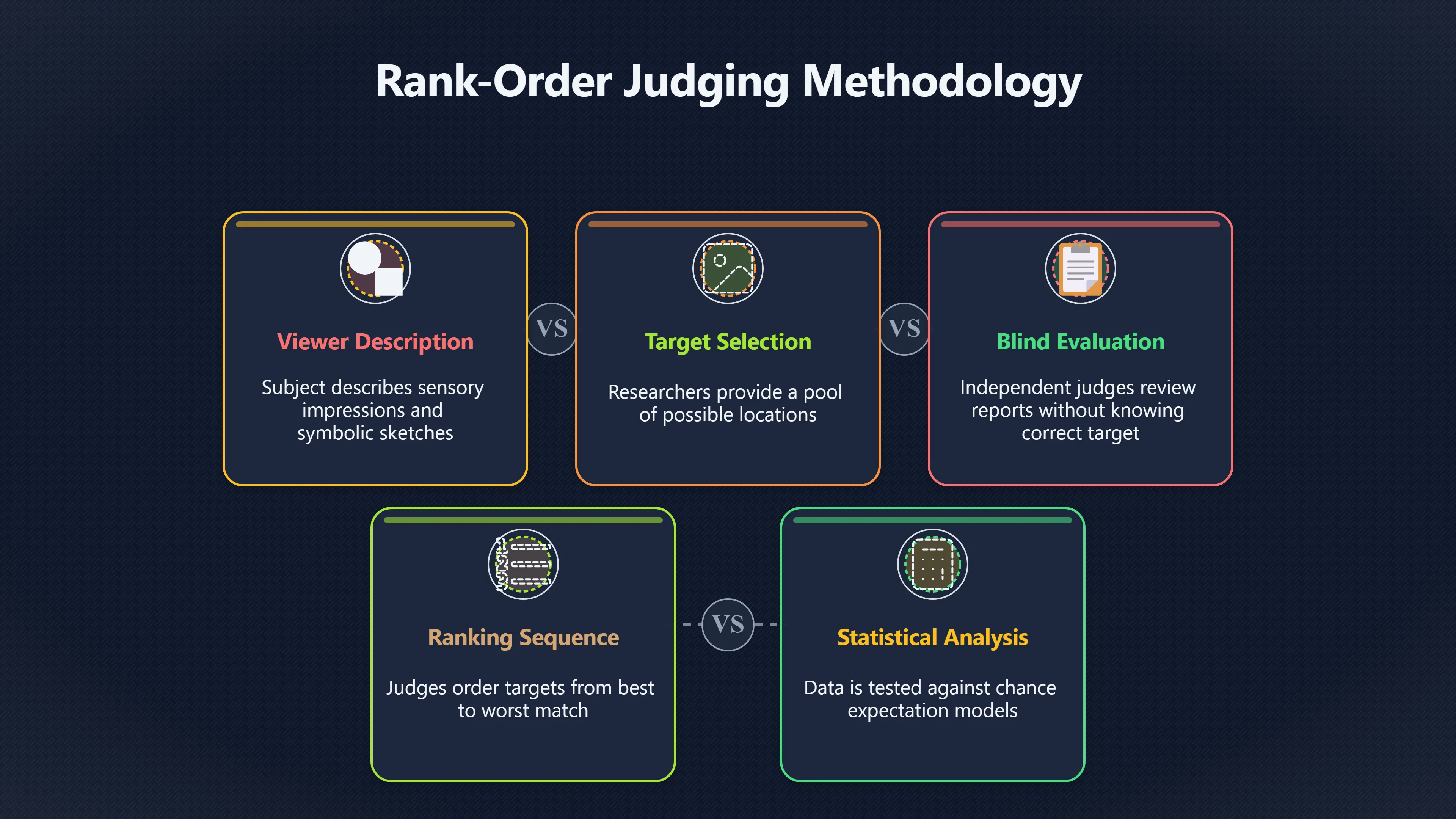
How Free-Response Judging Works
In a typical free-response experiment, the viewer is not asked to identify a target by name. Instead, they describe whatever impressions come to mind. These may include shapes, emotions, movement, textures, temperatures or rough sketches.
After the session, an independent judge—who ideally does not know which target was correct—is presented with the viewer’s report alongside several possible targets. The judge ranks the targets from best match to worst match. If the correct target consistently receives unusually high rankings across many trials, researchers test whether that pattern exceeds what chance would predict. This procedure, known as rank-order judging, has been widely used in laboratory remote-viewing studies because it provides a statistical framework for analysing highly descriptive responses.[UC Irvine Bren School]ics.uci.eduUC Irvine Bren SchoolAn Assessment of the Evidence for Psychic Functioningby J Utts · 1995 · Cited by 103 — After the completion of a rem…
The approach attempts to solve a genuine methodological problem. A drawing of “curved structures with water nearby” cannot easily be scored as simply correct or incorrect. Ranking allows judges to compare the overall similarity between the report and several candidate targets rather than evaluating isolated statements.
Supporters argue that this better reflects the way remote-viewing data are actually produced. The information is often incomplete, symbolic or impressionistic rather than a list of factual claims.
Where Generous Interpretation Enters the Score
The weakness of free-response judging is that similarity itself can be subjective.
Many remote-viewing reports contain broad descriptions that could plausibly fit numerous locations or photographs. Phrases such as “tall structure”, “movement”, “bright area”, “water”, “metal”, “people”, or “cold atmosphere” are sufficiently common that different judges may legitimately disagree about which target they resemble most closely.
Interpretation becomes even more flexible when viewers describe metaphorical impressions rather than literal objects. A report mentioning “energy”, “explosion”, or “pressure” might later be interpreted as machinery, a waterfall, an industrial site or even emotional activity depending on which target is available for comparison.
This creates several opportunities for subjective matching:
- Selective emphasis. Judges may naturally focus on the strongest correspondences while discounting mismatches.
- Unequal weighting. One highly distinctive feature may outweigh many incorrect details, even without predefined rules.
- Metaphorical flexibility. Symbolic descriptions can be interpreted in multiple ways after the target is known.
- Holistic impressions. Judges often evaluate an overall “feel” rather than counting objective correspondences.
None of these necessarily reflects dishonesty. They arise because humans are naturally good at recognising patterns and constructing meaningful similarities, particularly when evaluating rich descriptive material rather than simple factual answers.[UC Irvine Bren School]ics.uci.eduexternal judges provide much better hit rates than viewer…

Why Apparently Strong Hits Can Be Misleading
Free-response judging illustrates why statistical significance and practical proof are not identical.
Imagine a session containing twenty separate impressions. Perhaps three resemble the target closely, five are arguable, and twelve appear unrelated. Depending on how the comparison is performed, the session might be remembered as an impressive success or a poor performance.
This effect becomes stronger when:
- targets share common visual features;
- judges know something about the experiment’s aims;
- viewers or experimenters participate in scoring;
- scoring criteria are developed after seeing the responses.
Critics such as Ray Hyman have argued that some apparently convincing examples can emerge through “subjective validation”, where attention naturally concentrates on striking correspondences while overlooking numerous incorrect or ambiguous statements. In his review of the U.S. government’s remote-viewing programme, Hyman argued that many viewer reports were so general that reasonable guessing combined with subjective evaluation could account for at least some apparent successes.[Wikipedia]WikipediaJessica UttsJessica Utts
This criticism is aimed less at isolated spectacular cases than at the mechanism by which descriptive reports acquire evidential weight.
Safeguards That Make Matching Harder to Game
Researchers who use free-response methods have developed several safeguards intended to reduce interpretive bias.
The most important is blind judging. Judges should not know which target is correct, who produced the session, or what result the experimenters expect. This reduces conscious and unconscious influences during scoring. Rank-order judging with randomly selected decoy targets also limits opportunities to compare a report against an unlimited range of possible matches.[UC Irvine Bren School]ics.uci.eduUC Irvine Bren SchoolAn Assessment of the Evidence for Psychic Functioningby J Utts · 1995 · Cited by 103 — After the completion of a rem…
Additional protections include:
- predefining the target pool before data collection;
- using multiple independent judges rather than a single evaluator;
- measuring agreement between judges;
- specifying scoring procedures before the experiment begins;
- analysing all sessions rather than highlighting only dramatic examples.
These practices aim to constrain interpretation so that success depends less on persuasive storytelling and more on reproducible scoring rules.

Why the Debate Persists
Supporters and critics largely agree that judging quality matters; they disagree about whether existing safeguards are sufficient.
Jessica Utts argued that structured blind judging provides a legitimate statistical basis for evaluating free-response remote viewing, even though the responses themselves are descriptive rather than binary. She noted that rank-order methods define a clear chance expectation and therefore allow formal statistical testing.[UC Irvine Bren School]ics.uci.eduUC Irvine Bren SchoolAn Assessment of the Evidence for Psychic Functioningby J Utts · 1995 · Cited by 103 — After the completion of a rem…
Critics accept that blind judging is preferable to informal matching but argue that descriptive reports remain vulnerable to interpretive flexibility. From this perspective, reducing obvious methodological flaws does not entirely eliminate the possibility that generous matching contributes to positive results, especially when effect sizes are modest and practical predictions remain inconsistent.[UC Irvine Bren School]ics.uci.eduexternal judges provide much better hit rates than viewer…
This disagreement helps explain why debates over remote viewing continue despite decades of experiments. Statistical analyses may indicate above-chance performance under particular judging procedures, yet questions remain about whether those procedures fully separate genuine information from the human tendency to recognise meaningful patterns in ambiguous descriptions. That distinction sits at the heart of the broader question of when statistical significance becomes persuasive practical proof.[CIA+2UC Irvine Bren School]cia.govAN EVALUATION OF THE REMOTE VIEWING PROGRAMTypically, the remote viewers described the results of their experiences in written reports…
Amazon book picks
Further Reading
Books and field guides related to Why Vague Hits Can Look Strong. Use these as the next step if you want deeper reading beyond the article.
The Invisible Gorilla
Explores perception and interpretation errors relevant to matching tasks.

Statistics Done Wrong
First published 2015. Subjects: Missing observations (Statistics), Methodology, Statistics.

eBay marketplace picks
Marketplace Samples
Live-tested eBay searches with available results related to this page.




Endnotes
1.
Source: cia.gov
Link:https://www.cia.gov/readingroom/docs/CIA-RDP96-00791R000200180005-5.pdf
Source snippet
AN EVALUATION OF THE REMOTE VIEWING PROGRAMTypically, the remote viewers described the results of their experiences in written reports...
2.
Source: Wikipedia
Title: Jessica Utts
Link:https://en.wikipedia.org/wiki/Jessica_Utts
3.
Source: ics.uci.edu
Link:https://www.ics.uci.edu/~jutts/air.pdf
Source snippet
UC Irvine Bren SchoolAn Assessment of the Evidence for Psychic Functioningby J Utts · 1995 · Cited by 103 — After the completion of a rem...
4.
Source: ics.uci.edu
Link:https://www.ics.uci.edu/~jutts/hyman.html
Source snippet
external judges provide much better hit rates than viewer...
Additional References
5.
Source: skepticalinquirer.org
Link:https://skepticalinquirer.org/wp-content/uploads/sites/29/2019/03/Issue-02-18.pdf
6.
Source: researchgate.net
Link:https://www.researchgate.net/publication/340914519Performance_at_a_Precognitive_Remote_Viewing_Task_with_and_without[Ganzfeld
Source snippet
Roe and others published Performance at a Precognitive Remote Viewing Task, with and without Ganzfeld Stimulation: Three...
7.
Source: researchgate.net
Title: 369604750 Remote Viewing a 1974 2022 systematic review and meta analysis
Link:https://www.researchgate.net/publication/369604750_Remote_Viewing_a_1974-2022_systematic_review_and_meta-analysis
Source snippet
(PDF) Remote Viewing: a 1974-2022 systematic review...This is the first meta-analysis of all studies related to remote viewing tasks con...
8.
Source: documents.theblackvault.com
Link:https://documents.theblackvault.com/documents/remoteviewing/stargate/STARGATE%20%238%20237/Part0005/CIA-RDP96-00789R003100110001-5.TXT
Source snippet
Attitude and target differences(D. FREEMAN, J. A. Mood, personality, and attitude0 in [precognition]({{ 'precognition/' | relative_url }}) tests. Subject selection in a...
9.
Source: nsarchive2.gwu.edu
Title: The effect sizes for the viewers 009, 372 and 389 were 0.432 (p =.Read more
Link:https://nsarchive2.gwu.edu/NSAEBB/NSAEBB438/docs/doc_57.pdf
Source snippet
National Security ArchiveAn Evaluation of Remote Viewing: Research and...by MD Mumford · 1995 · Cited by 76 — RESULTS: Responses were bl...
10.
Source: youtube.com
Title: AP Psych Unit 0: MUST-KNOW Practice Questions
Link:http://www.youtube.com/watch?v=TsuK7k3J5X8
Source snippet
"Remote viewing" free-response judging "rank-order" experiment Hiring Managers Are Judging You On These Things Teal...
11.
Source: youtube.com
Link:http://www.youtube.com/watch?v=yFTuZmQiQf8
Source snippet
AP Psych Unit 0: MUST-KNOW Practice Questions...
12.
Source: youtube.com
Title: Statistical Significance and [p-Values]({{ ‘p-values/’ | relative_url }}) Explained Intuitively
Link:http://www.youtube.com/watch?v=DAkJhY2zQ3c
Source snippet
Statistical Significance vs Effect Size: The Distinction Every Principal Needs...
13.
Source: youtube.com
Title: P value versus effect size
Link:http://www.youtube.com/watch?v=sTRPNxmBE2Y
Source snippet
Statistical Significance (p-values) & Practical Significance (Effect Size) of Research Results...
14.
Source: journalofscientificexploration.org
Link:https://journalofscientificexploration.org/index.php/jse/article/view/1038/660
Topic Tree